오늘 리뷰할 논문은 EBGAN 논문이다.
증명의 수학은 이해하지 못했다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- [논문 리뷰] Energy-Based Generative Adversarial Networks
- 초짜 대학원생의 입장에서 이해하는 Energy-Based Generative Adversarial Networks (1)
Summary
energy-based model이란 것은 input space의 각 점을 single scalar 값인 "energy"로 map하는 함수를 만든다는 것이다. learning phase에서는 desired configurations는 low energy, incorrect configurations은 high energy가 할당되게 energy surface를 형성한다. Supervised learning에서는 training set의 pair (X, Y )에 대해 Y가 correct면 energy가 작은 값이고 incorrect면 큰 값이다. Unsupervised learning에서는 data manifold에 lower energy를 할당한다. 이때 contrastive sample이라는 용어는 energy pull-up을 유발하는 data point를 의미한다. (예를 들어 supervised learning에서는 incorrect Y, unsupervised learning에서는 low data density regions에서 온 points)
논문은 (explicit probabilistic interpretation 없이) discriminator을 energy function(=contrast function)으로 간주할 것을 제안한다. discriminator이 계산한 energy function은 generator을 위한 trainable cost로 볼 수 있다. high data density 영역은 low energy를 할당하고 그 외 영역은 높은 값을 할당하도록 discriminator을 학습할 수 있다. 반대로 generator은 discriminator가 낮은 energy를 할당하는 영역에서 sample을 생산하는 trainable parameterized function로 볼 수 있다.
discriminator을 energy function으로 해석하는 것은 알반적인 binary classifier with logistic output와 더불어 여러 다양한 architectures과 loss functionals의 사용을 허용한다. 그중 논문은 reconstruction error를 energy로 간주한 auto-encoder architecture를 discrminator로 사용한다.
논문의 기여는 다음과 같다.

discriminator D는 energy value E를 산출한다. 논문은 편의상 E가 non-negative value라고 가정했는데 E가 하한이 존재하는 한 analysis가 성립한다. 그리고 논문은 margin loss를 사용하는데 다른 여러 choice도 가능하다. generator이 convergence에서 멀 때 better quality gradients를 얻기 위해 G, D에 다른 loss를 사용한다.
positive margin m, data sample x, generated sample G(z)에 대해 loss는 다음과 같다.
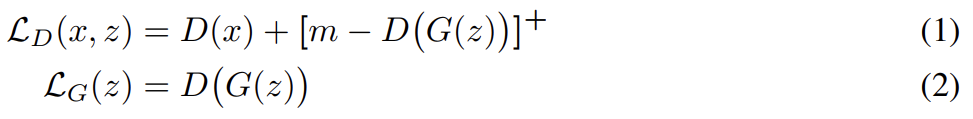
이다. 를 최소화하는 것은 의 둘째항을 최대화하는 것과 비슷하다. 같은 minimum을 가지지만 D(G(z)) ≥ m 일 때 non-zero gradiens를 가진다.
논문은 시스템이 Nash equilibrium에 도달하면 G가 dataset distribution과 구분할 수 없는 sample을 생성한다는 것을 이론적 분석을 통해 보인다. 증명은 non-parametric setting 하에 진행되고, 즉 D와 G가 infinite capacity를 가진다고 가정한다. , 는 G(z)의 density distribution이라 두고 다음과 같이 두 함수를 정의한다.
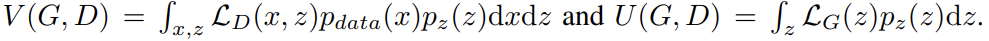
D가 V를 최소화하도록, G가 U를 최소화하도록 학습하면 시스템의 Nash equilibrium은 다음 두 식을 만족하는 쌍 ()다.
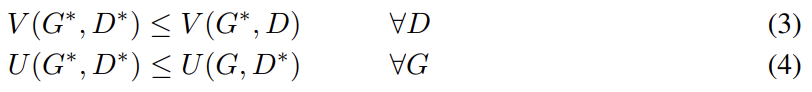
증명은 다음과 같다.


(proof는 논문의 appendix에)
논문의 실험에서는 D를 auto-encoder로써 설계한다.
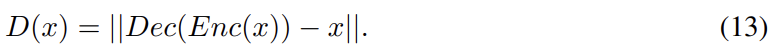
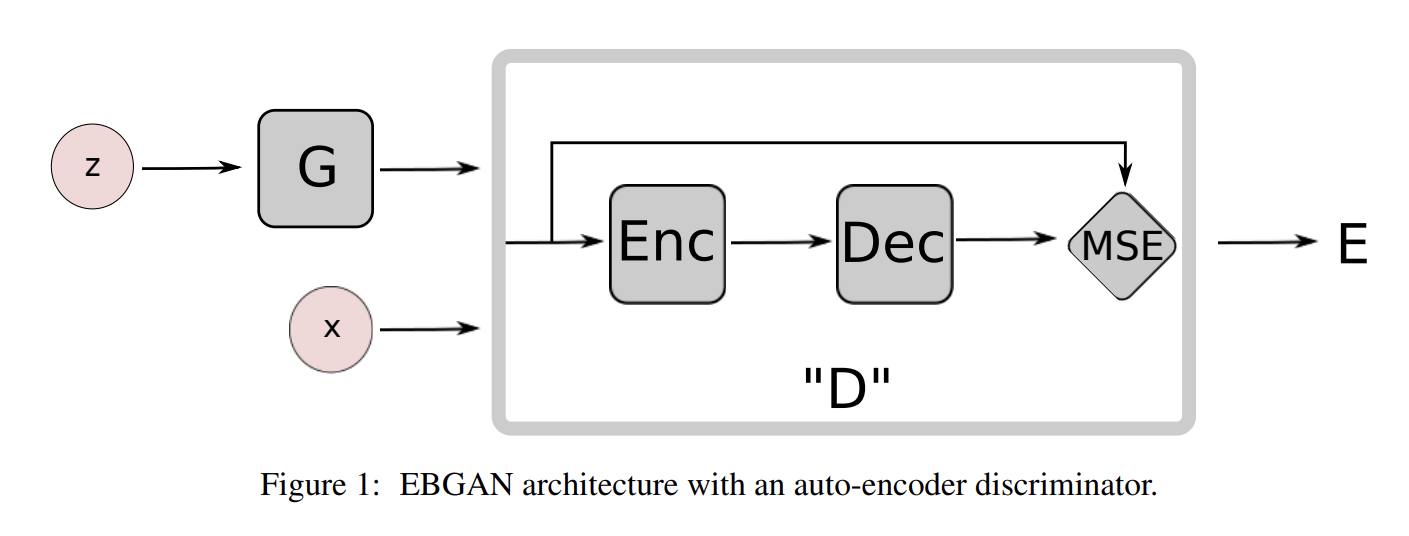
Fig 1은 auto-encoder discriminator을 가진 EBGAN model의 diagram이다. auto-encoder를 사용한 게 임의의 선택 같지만 다음과 같은 이유로 binary logistic network보다 매력적이다.
- model을 학습하기 위해 single bit of target information를 사용하는 대신, reconstruction-based output은 discriminator에 다양한 targets을 제공한다. binary logistic loss로는 오직 두 targets만 가능해서 minibatch 내에서 서로 다른 samples에 대응하는 gradients가 orthogonal하지 못하다. 이는 training에 비효율적이고, 그렇다고 minibatch size를 줄이는 것도 비효율적이다. 반면 reconstruction loss는 minibatch 내에서 서로 매우 다른 gradient directions를 생성해서 effeciency 손해 없이 larger minibatch size를 허용한다.
- auto-encoders는 전통적으로 energy-based model을 표현하기 위해 사용됐다. 몇 regularization terms과 함께 train되면 auto-encoders는 supervision이나 negative examples 없이 energy manifold를 배울 능력이 있다. 이는 EBGAN auto-encoding model가 real sample을 reconstruct하도록 train되더라도 discriminaor가 스스로 data manifold를 발견하는 것에 기여함을 의미한다. 반면 binary logistic loss로 학습된 discriminator은 generator가 생성한 negative example 없이는 잘 작동하지 못한다.
auto-encoder 학습의 흔한 문제는 모델이 identity function보다 더 배울 수 있다는 것인데(learn little more than), 즉 전체 space에 zero energy를 할당할 수 있다는 것이다. 이 문제를 피하고자 모델은 data manifold 바깥의 points에 higher energy를 할당하도록 강요되어야 한다. 앞선 연구는 latent representations를 regularizing하는 방식으로 이 문제를 다뤘다. regularizer은 auto-encoder의 reconstructing power을 제한해서 input points의 일부에만 low energy를 할당할 수 있게 집중시킨다.
논문은 EBGAN framework의 energy function(=discriminator)도 generator가 생성한 contrastive samples에 high reconstruction energies를 줘야 하니 regularize된 것으로 볼 수 있다고 주장한다. 또 1. regularizer(=generator)가 handcrafted된 게 아니라 fully trainable하고 2. adversarial training paradigm이 producing contrastive sample과 learning energy function 사이 직접적인 interaction을 가능하게 하기 때문에 EBGAN이 더 flexibility를 허용한다고 주장한다.
논문은 의 몇 개 mode에만 cluster되어 sample을 생성하는 문제를 방지하는 "repelling regularizer"을 제안한다. repelling regularizer을 구현하는 것은 representation level에서 동작하는 Pulling-away Term (PT)을 포함한다. 은 encoder output layer에서 가져온 batch of sample representations를 나타내며 PT는 다음과 같다.
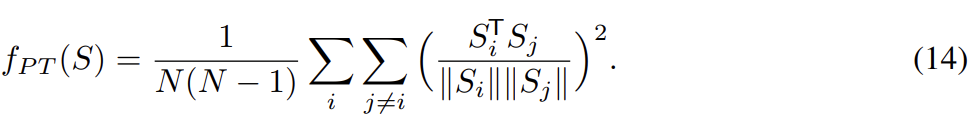
PT는 minibatch에서 작동하며 pairwise sample representation를 orthogonalize하려고 시도한다. Euclidean distance 대신 cosine similarity를 선택한 이유는 항이 하한을 가지고 scale에 invariant하기 위함이다. 이 항을 가지고 학습한 모델은 EBGAN-PT라고 부른다. PT는 generator loss에만 사용되고 discriminator loss에는 사용하지 않는다.

논문은 GANs에 비교한 EBGANs의 stability를 평가하기 위해 fully-connected networks를 가지고 MNIST digit generation task를 수행한다. 여러 architectural choices와 hyperparameter에 대해 exhaustive grid search를 한다.
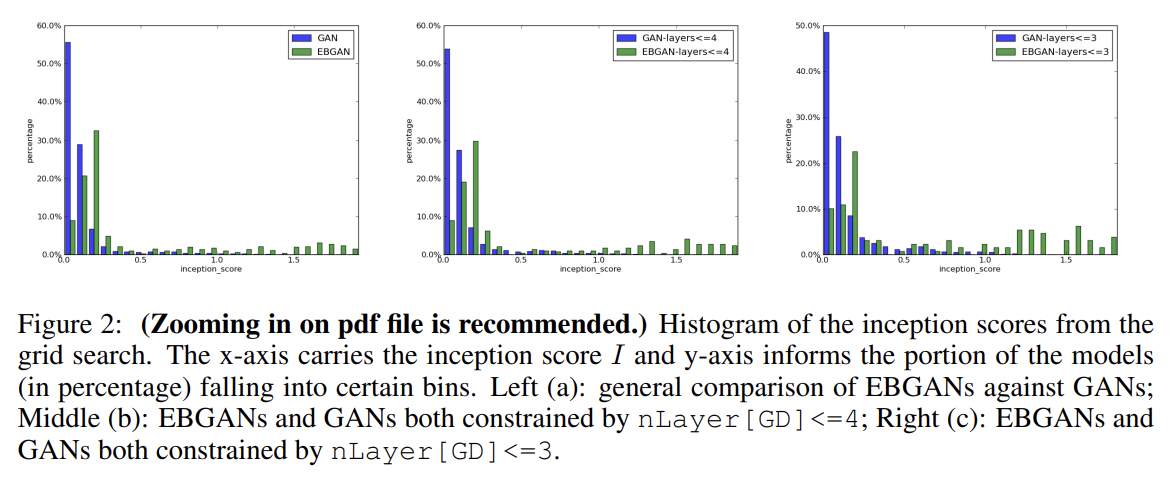
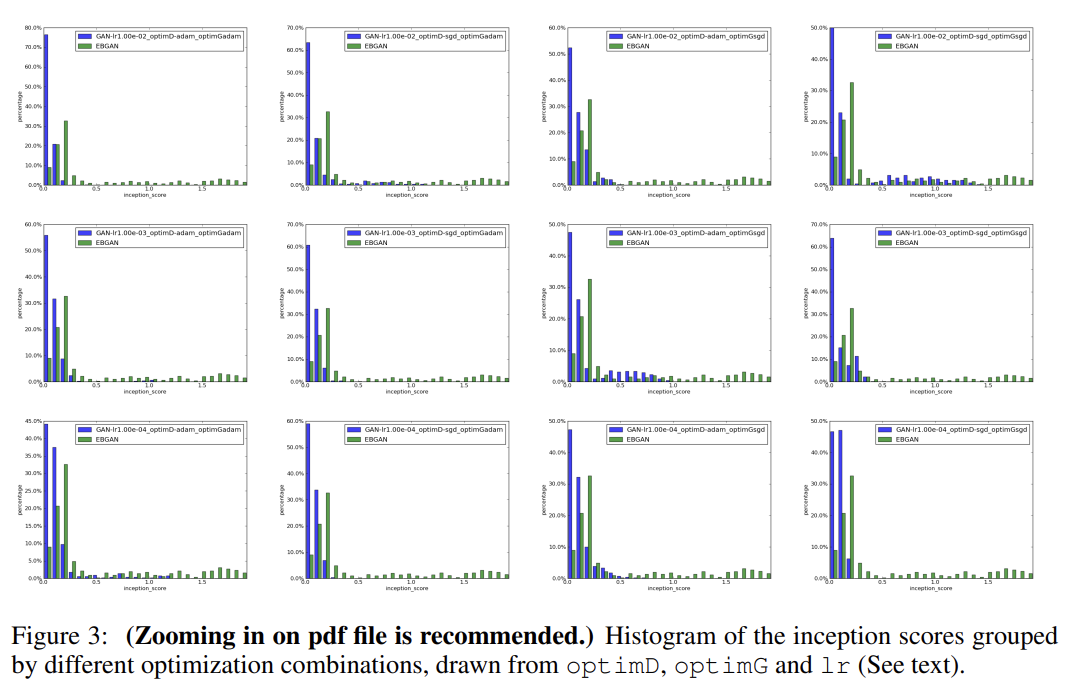
nLayerD는 Enc와 Dec을 합친 총 layer 수이며 편의상 Dec를 1층으로 고정하고 Enc의 층 수만 tune했다. margin은 10으로 두고 tune하지 않았다. generation quality를 평가하기 위해 inception score을 사용했다. (inception score을 약간 변형한) I' scores를 표현한 히스토그램들은 EBGANs가 GANs보다 더 확실히 학습됨을 보여준다.

논문은 permutation-invariant MNIST를 사용해 semi-supervised learning에서 EBGAN framework의 잠재력을 탐구한다. bottom-layer-cost Ladder Network (LN) (Rasmus et al., 2015)를 EGBAN framework (EBGAN-LN)와 사용한다.
EBGAN framework이 semi-supervised learning을 할 때 중요한 기법 하나를 발견했는데, 식 (1)의 margin value m을 점진적으로 감소시키는 것이다. 이는 가 data manifold에 근접할수록 generator을 덜 punish한다는 것이다.


LSUN bedroom dataset과 large-scale face dataset CelebA under alignment를 사용해 EBGAN을 deep convolutional architecture에 적용해 64 × 64 RGB images를 생성한다. Fig 5, 6에서 결과를 DCGANs과 비교했다.


마지막으로 ImageNet에 EBGAN을 학습시켜 high-resolution image를 생성하게 했다.
Strengths
- discriminator을 energy function으로 해석하는 관점과 autoencoder을 사용한 점이 insight가 신선했다.
Weaknesses
- 실험이 부실한 것 같다.
