오늘 리뷰할 논문은 Efficiently Learning an Encoder that Classifies Token Replacements Accurately, ELECTRA 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문리뷰] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
- 꼼꼼하고 이해하기 쉬운 ELECTRA 논문 리뷰
Summary
BERT의 MLM loss는 downstream task에 효과적이지만, 많은 연산을 필요로 한다. 그래서 논문은 대신 replaced token detection라고 이름 붙인 sample-efficient pre-training task를 제안한다. input을 masking하는 대신, 작은 generator network에서 sample된 plausible alternatives로 몇몇 tokens을 교체한다. 그리고 corrupted tokens의 original identity를 예측하도록 학습하는 대신 corrupted input의 각 token이 generator sample로 교체된 것인지 아닌지를 예측하도록 discriminative model를 학습한다. mask된 token만이 아니라 전체 input tokens에 정의됐기 때문에 이 task는 MLM보다 효과적이다. 결과적으로 동일한 model size, data, compute에서 이 방식으로 배운 contextual representations는 BERT보다 성능이 좋았으며 특히 작은 모델에서 gain이 컸다.
MLM에선 network가 pre-training 중에 인공적인 [MASK] token을 보는데 downstream task에 fine-tuning할 때는 [MASK]가 없어서 mismatch가 발생하는데 논문의 방식은 이를 방지한다. 또 MLM은 원본 token을 예측하는 generator로써 미학습되는데 ELECTRA는 모든 token이 original인지 replacement인지 구분하는 discriminator로 학습된다. 이 방식은 GAN을 연상시키지만, GAN을 text에 적용하기 어렵기 때문에 corrupted token을 만드는 generator가 maximum likelihood로 학습된다는 점에서 논문의 방식은 adversarial하지 않다.
더 많은 연산으로 pre-training하는 것이 거의 항상 더 좋은 downstream accuracy를 만드므로 논문은 downstream 성능 만큼이나 연산 효율도 중요하게 여겨야 할 요소라고 생각한다. 이런 관점에서 논문은 여러 크기의 ELECTRA 모델을 만들고 downstream 성능과 연산 요구량을 비교한다.
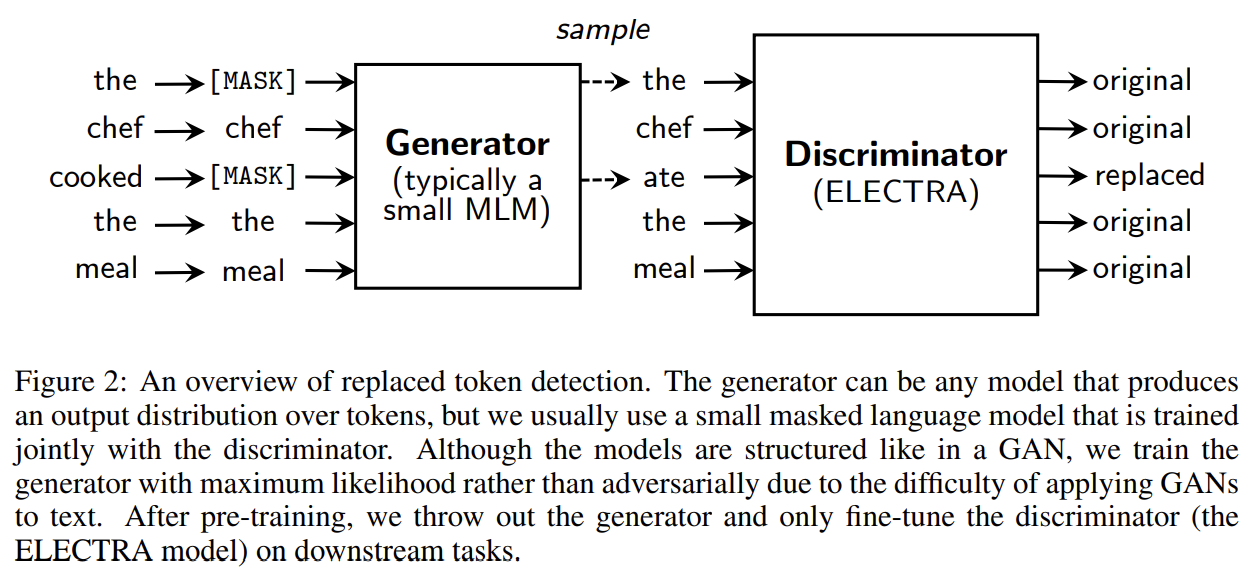
replaced token detection은 두 neural network generator G, discriminator D를 학습시킨다. G, D는 각각 input tokens x = [x1, ..., xn]에 대한 sequence를 contextualized vector representations h(x) = [h1, ..., hn]의 sequence로 map하는 encoder (Transformer network)로 구성된다. 주어진 position t에 대해(in our case only positions where x_t = [MASK]) generator은 softmax layer로 특정 토큰 x_t를 생성할 확률을 output한다.
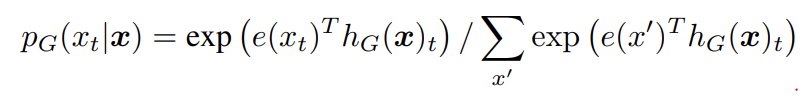
e는 token embeddings를 의미한다. 주어진 position t에 대해 discriminator은 토큰 x_t가 'real'인지, 즉 generator distribution이 아니라 data에서 온 것인지 sigmoid output layer로 예측한다.
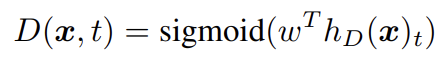
generator은 MLM을 수행하도록 학습된다. input x = [x1, x2, ..., xn]가 주어졌을 때 MLM은 먼저 m = [m1, ..., mk]을 mask하기 위해 1~n 사이 정수로 random set of positions를 고른다. 선택된 토큰들은 [MASK] 토큰으로 교체되며 로 표기한다. generator은 masked-out tokens의 original identities를 예측하도록 학습된다. discriminator은 masked-out tokens를 generator tokens로 교체하여 corrupted example 를 만들고 discriminaotor가 내의 어떤 tokens이 original input x와 맞는지 예측하도록 학습한다. model input과 loss function은 다음과 같다.
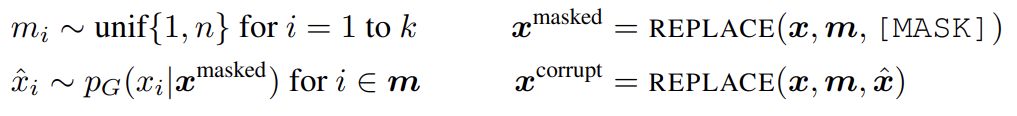
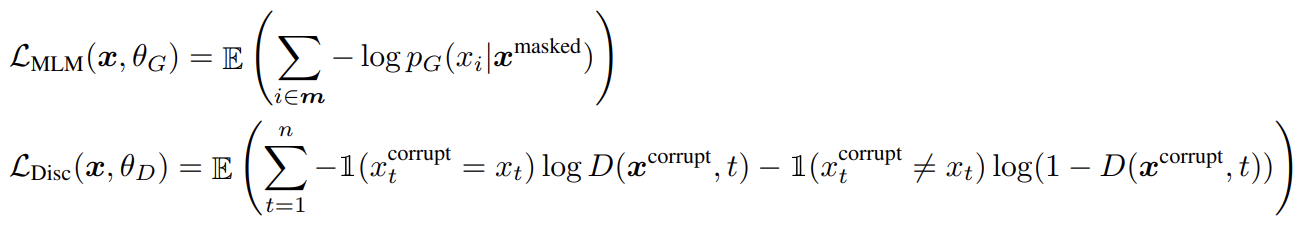
training objective가 GAN과 비슷하지만 몇 가지 다른 점이 있다. 첫째로 generator가 올바른 token을 생성한다면 그 토큰은 'fake'가 아니라 'real'로 판정된다(이 방식이 downstream 성능을 적당히 향상시켰다). 또 discriminator을 속이기 위해 adversarialy가 아니라 maximum likelihood로 generator가 학습됐다. generator을 Adversarially training하는 것은 어려운데, generator에서 sampling하는 것을 back-propagate하는 게 불가능하기 때문이다. 마지막으로 보통의 GAN처럼 noise vector를 input으로 받지 않는다.
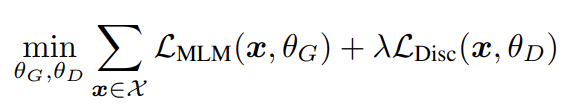
raw text의 large corpus X에 대해 위의 loss를 최소화한다. losses 내의 기댓값은 single sample로 근사한다. discriminator loss를 generator에 역전파하지 않는다(sampling step 때문에 불가능하다). pre-trainng 이후 generator을 버리고 discriminator을 downstream task에 fine-tuning한다.
실험은 GLUE, SQuAD benchmark에 했다. pre-train은 원본 BERT와 동일하게 Wikipedia와 BooksCorpus 데이터셋을 사용했는데 Large model들은 XLNet에서 사용한 대로 ClueWeb, CommonCrawl, Gigaword를 추가해 BERT의 데이터셋을 확장했다.
model architecture와 대부분의 hyperparameter은 BERT와 동일하다. GLUE에 fine-tuning할 때는 ELECTRA의 꼭대기에 간단한 linear classifier을 추가했다. SQuAD에선 ELECTRA의 꼭대기에 XLNet에서 가져 온 question-answering module을 추가했다.
model에 몇 가지 extension을 추가해서도 실험한다. 따로 명시하지 않은 이상 이 실험들은 BERT-Base와 동일한 model size와 training data를 사용했다.
- Weight Sharing
generator와 discriminator 사이 weight sharing을 통해 pre-training의 효율을 높일 수 있다고 제안했다. G와 D가 같은 크기일 때 모든 transformer weights가 tie될 수 있다. 그러나 G의 크기가 작은 게 효율적이라고 밝혀졌기 때문에 G와 D의 embeddings (token과 positional embeddings 양쪽 다)만 공유했다. 이 경우 embeddings를 discriminator’s hidden states의 크기로 사용했다. G의 “input”과 “output” token embeddings은 BERT처럼 항상 tie되었다.
G와 D의 크기가 같을 때 GLUE score 기준 no weight tying은 83.6점, tying token embeddings은 84.3점, tying all weights는 84.4점이었다. 저자들은 (전부 tie하는 게 아니라) tied token embeddings가 좋다고 가설을 세웠는데 MLM이 특히 이 (토큰 임베딩) representation을 학습하는 데 효과적이기 때문이다. discriminator가 input에 존재하거나 generator로 생성된 token만 update하는 반면 generator은 모든 token embedding을 update하기 때문이다. 반면 전부 tie하는 전략은 G와 D가 같은 크기여야 한다는 단점 때문에 성능 향상이 작았다. 이 결과를 바탕으로 이후 실험은 tied embeddings를 사용했다.
- Smaller Generators
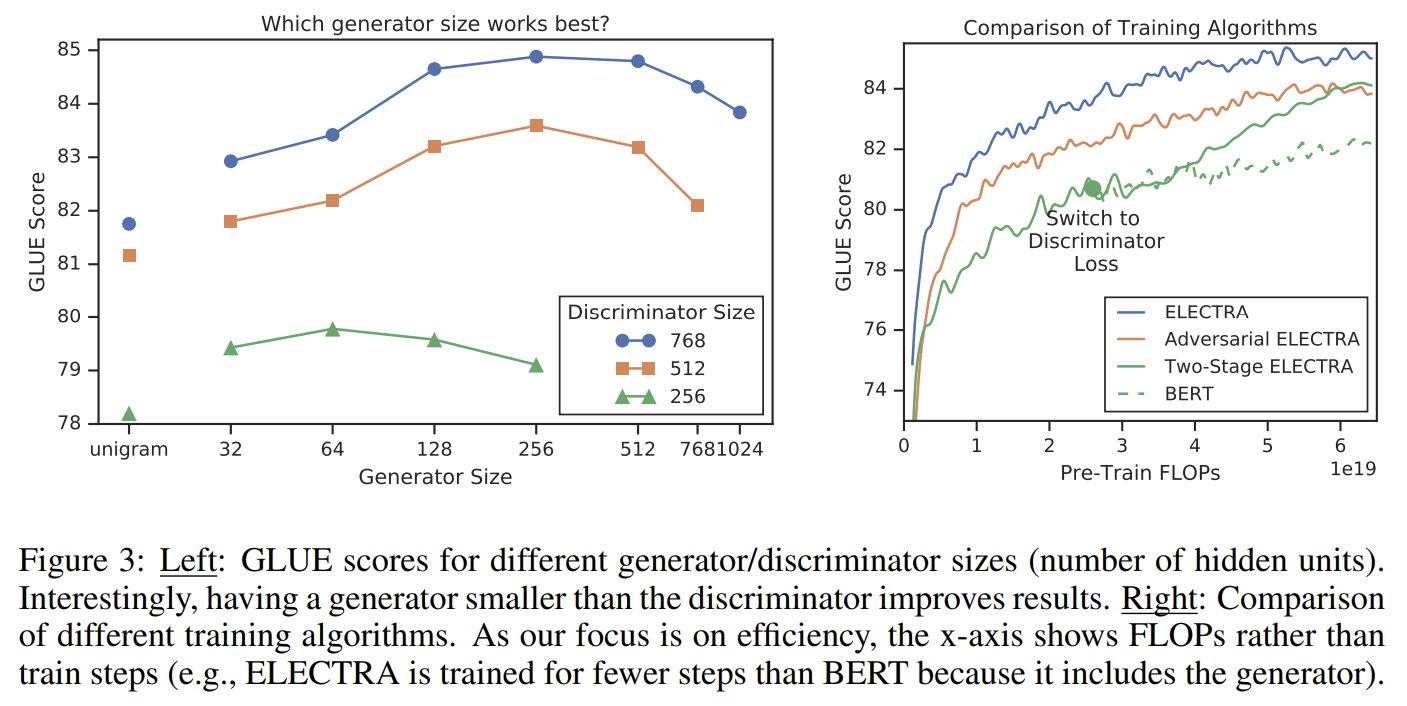
만약 G와 D가 같은 크리라면 ELECTRA를 학습하는 데 걸리는 step 당 연산량은 MLM만을 사용할 때보다 두 배가 될 것이다. 그래서 이를 줄이기 위해 (다른 hyperaparameter은 유지하고) layer size를 줄여 작은 G를 사용할 것을 제안한다. 실험 결과 generator가 discriminator 크기의 1/4~1/2일 때 가장 잘 작동했는데 너무 강한(큰) generator을 사용하면 discriminator가 학습하기에 너무 어려운 task를 부과하기 때문으로 추측된다. 이후 실험은 주어진 discriminator size에 대해 최고의 성능을 내는 generator size를 사용했다.
- Training Algorithms
제안된 training objective는 G와 D를 공동으로 학습한다. 대신, 다음과 같이 두 가지 단계로 학습하는 방법을 실험했다.

Fig 3의 결과를 보면 two-state training 중 generative에서 discriminative objective로 전환할 때 downstream task 성능이 유의미하게 향상됐지만 joint training을 넘지는 못했다.

논문의 목표는 pre-training 효율을 향상시키는 것이기 때문에 small model도 실험한다. BERT-Base hyperparameters에서 시작해 sequence length를 512에서 128로 줄이고 batch size를 256에서 128로 줄이고 모델의 hidden dimension size를 768에서 256으로 줄이고 768에서 128로 더 작은 token embeddings을 사용했다. 공평한 비교를 위해 BERT-Small도 동일한 hyperparameter로 학습했다. 실험 결과 ELECTRA-Small은 더 많은 연산과 parameter를 사용하는 다른 모델보다 더 잘 작동한다.
- LARGE MODELS
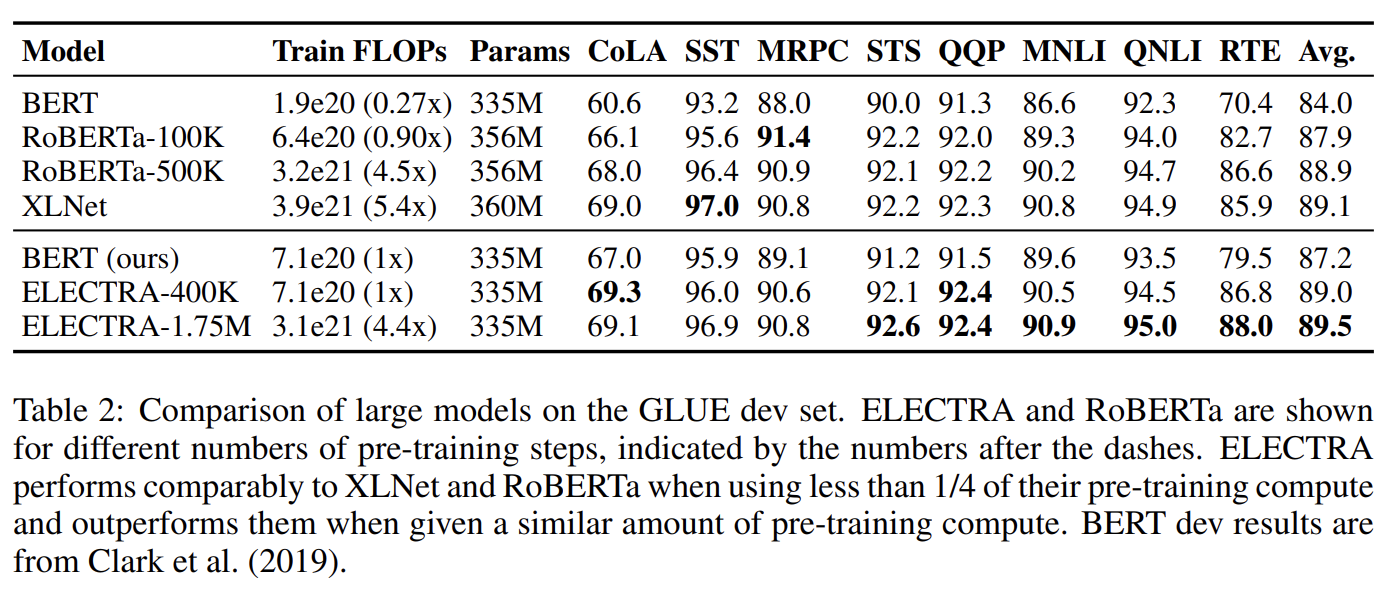
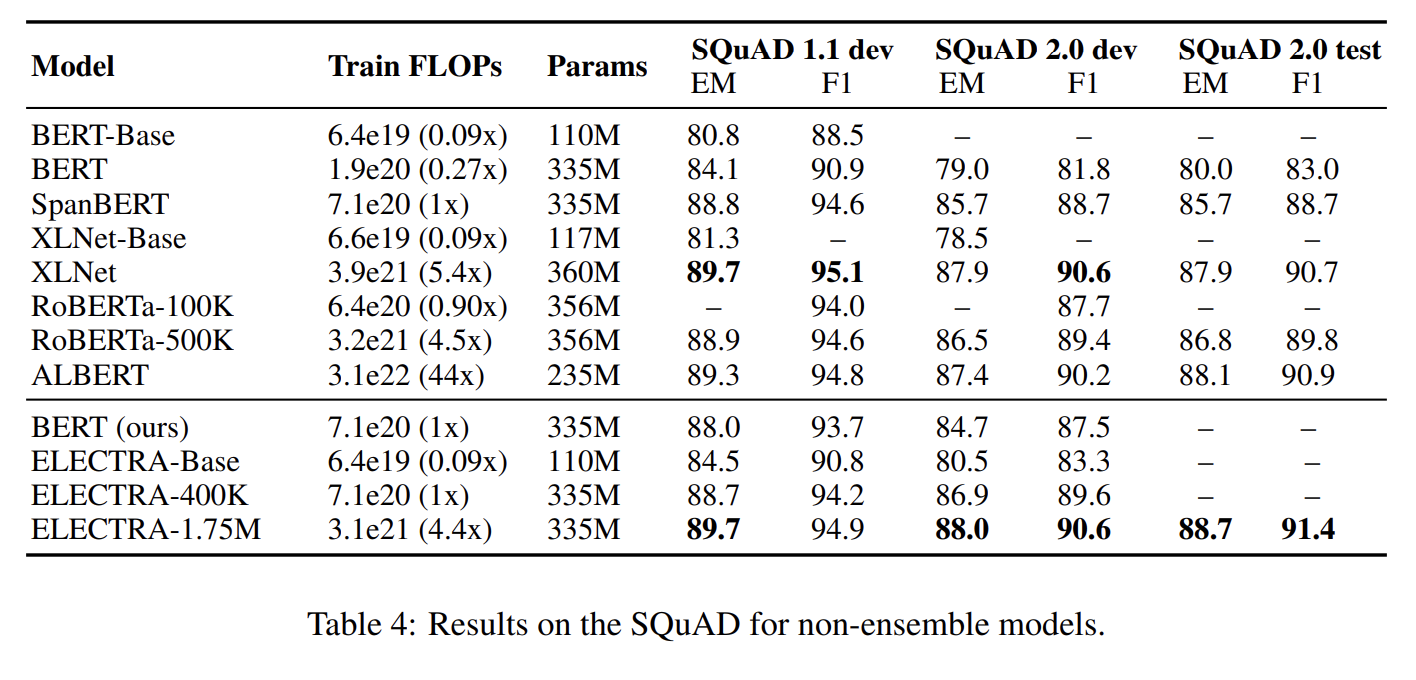
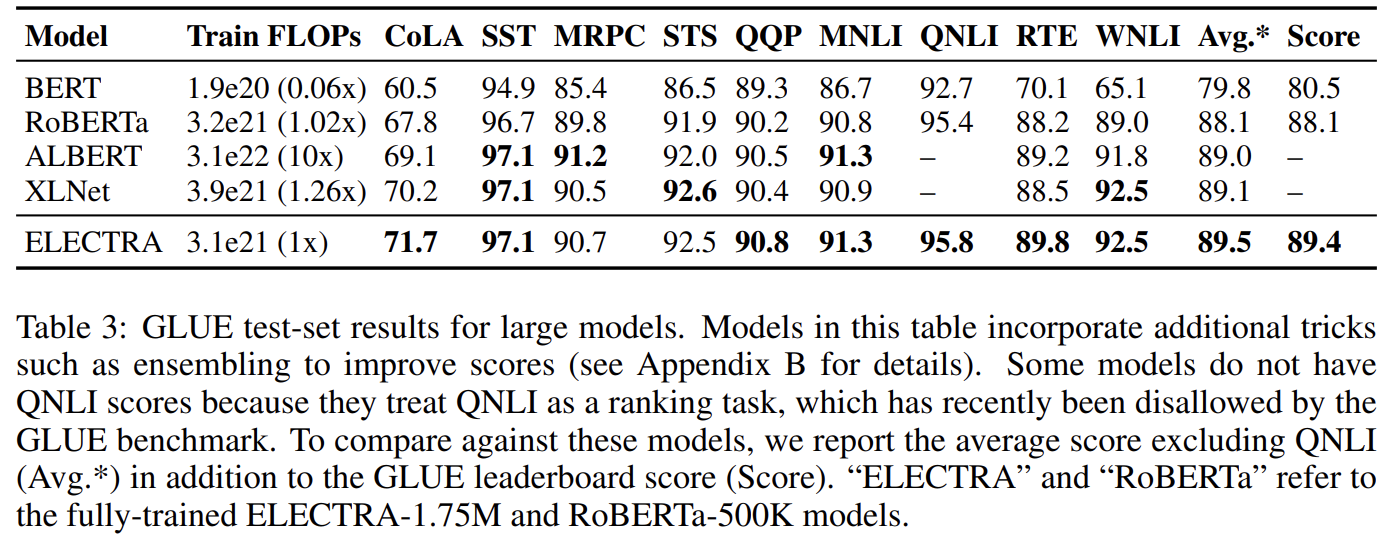
large scale에서 replaced token detection pretraining task의 효과를 확인하기 위해 big ELECTRA models도 실험한다. 설명은 생략한다.
- EFFICIENCY ANALYSIS
앞서 MLM이 token의 일부만 사용해 training objective를 부과하기 때문에 비효율적이라고 주장했는데, model이 여전히 많은 input tokens를 받기 때문에 근거가 명백하지 않을 수 있다. ELECTRA의 성능 향상이 어디서 오는지 더 정확히 알기 위해 BERT와 ELECTRA 사이 'stepping stone'이도록 설계된 여러 pre-training objectives를 비교한다.


실험 결과 첫째로 ELECTRA 15%가 ELECTRA보다 더 나쁘게 작동한다는 점에서 ELECTRA가 subset이 아니라 전체 input token에 정의된 loss로 많은 이익을 봄을 발견했다. 둘째로 Replace MLM이 BERT보다 약간 잘 작동한다는 점에서 BERT가 [MASK] token의 pre-train fine-tune mismatch로 성능에 손해를 본다는 것을 알았다. 마지막으로 All-Tokens MLM는 BERT와 ELECTRA 사이 차이를 가장 줄였다. 종합해서 ELECTRA의 성능 향상은 모든 token을 사용한 점이 크게 기여했고 pre-train fine-tune mismatch를 완화한 게 작게 기여했다.
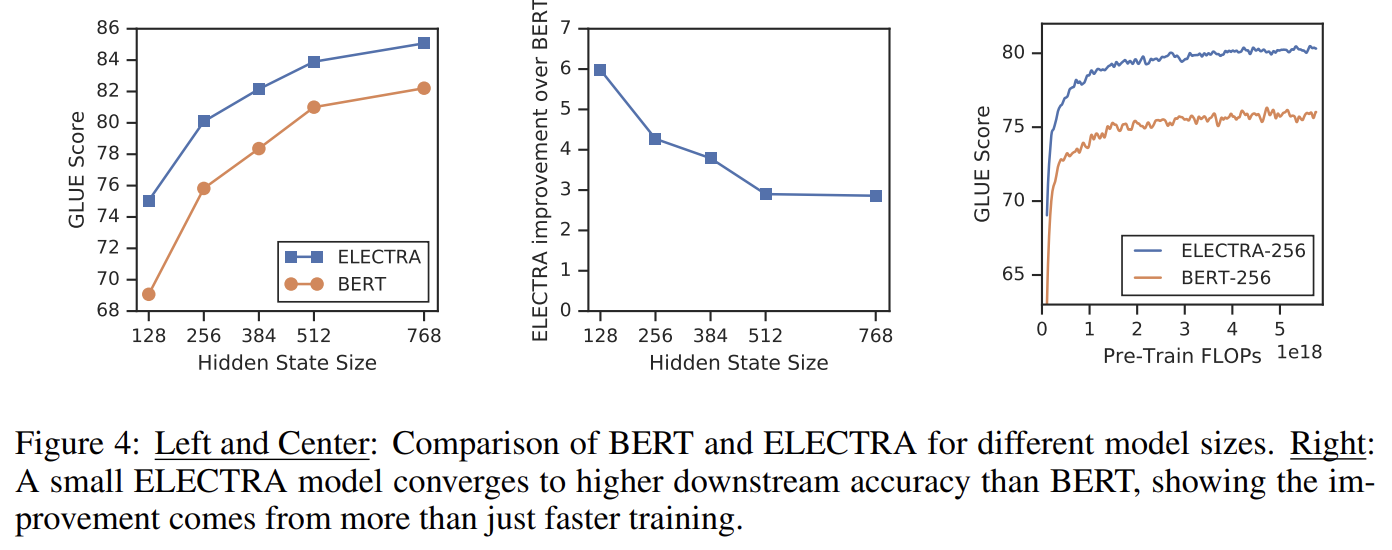
All-Tokens MLM에 비해 ELECTRA의 성능 향상은 ELECTRA의 gain이 단지 faster training에서 오지 않음을 의미한다. BERT와 ELECTRA를 다양한 크기에서 비교하여 이를 연구한다. model이 작아질수록 ELECTRA의 gain이 커진다. small models이 수렴까지 완전히 학습됐을 때 ELECTRA는 BERT보다 더 높은 downstream 정확도를 보인다. 각 position에서 가능한 tokens의 full distribution을 model할 필요가 없기 때문에 ELECTRA가 BERT보다 parameter-efficient한 것으로 추측된다.
Strengths
- 지금껏 NSP를 지적한 논문은 많이 봤는데 여기는 MLM의 문제를 보완해서 신선했다.
- 다른 논문에선 MLM이 masked token 간의 연관성을 배울 수 없는 단점이 있다고 지적했는데 replaced token detection은 그런 문제가 없을 듯하다.
- adversarial하지는 않지만 GAN처럼 generator와 discriminator을 사용한 점이 흥미로웠다.
Weaknesses
- 크기가 작을수록 ELECTRA의 효율이 커졌는데 크기가 크면 성능이 올라가는 자연스러운 경향과 괴리가 있는 것 같다.
