오늘 리뷰할 논문은 BUTD 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- Bottom-Up and Top-Down Attention for Image Captioning and VQA
- VQA: Visual Question Answering - Computer Vision & NLP 분야에 대해
Summary
fine-grained analysis와 심지어 multiple steps of reasoning을 통해 깊은 이미지 이해를 가능하게 하고자 image captioning과 visual question answering (VQA) 분야에서 Top-down visual attention mechanisms이 널리 사용되었다. 논문은 objects와 다른 두드러진 image regions의 수준에서 attention이 연산되게 하는 combined bottom-up and top-down attention mechanism을 제안한다. (Faster R-CNN에 기반한) bottom-up mechanism은 (각각 연관된 feature vector를 가진) image regions을 제안하고 top-down mechanism은 feature weightings를 결정한다.
human visual system에선 attention이 현재 과제(예컨대 사물을 보는 것)로 인해 결정되는 top-down signals로써 의도적으로 집중될 수 있고 예상치 못한, 새로운, 두드러진 자극과 연관된 bottom-up signals로써 자동적으로 집중될 수 있다. 논문은 비슷한 용어를 적용해 nonvisual 또는 task-specific context로 얻은 attention mechanisms을 top-down, 순수한 visual feed-forward attention mechanisms을 bottom-up이라고 칭한다.

image captioning과 VQA에 사용되는 가장 전통적인 visual attention mechanism은 top-down 종류다. partially-completed caption output이나 image 관련 question을 context로 받아 이 메커니즘은 일반적으로 CNN의 하나 이상의 layer의 output에 선택적으로 attend하도록 학습된다. 그러나 이 방식은 attention의 대상이 되는 image regions가 어떻게 결정되는지 고려하지 않는다. Fig 1에 개념적으로 묘사된 것처럼 resulting input regions는 image의 내용물과 무관하게 동일한 크기와 모양을 가진 neural receptive fields의 uniform grid다. 그러나 더 인간 같은 captions와 question answers을 생성하기 위해서는 objects와 다른 salient image regions가 attention을 위한 더 자연스러운 기반(basis)이다.
논문은 combined bottom-up and top-down visual attention mechanism을 제안한다. bottom-up mechanism은 salient image regions의 집합을 제안하고, 각 region은 pooled convolutional feature vector로 대표된다. 실제로는 Faster R-CNN을 사용해 bottom-up attention을 구현한다. top-down mechanism은 image regions에 대한(over) attention distribution을 예측하기 위해 task-specific context를 사용한다. 그 다음 attended feature vector은 모든 regions에 대한(over) image features의 weighted average로서 계산된다.
bottom-up과 top-down attention의 조합을 2가지 task에서 평가한다. 첫째로 caption generation 중 salient image regions의 multiple glimpse를 받는 image captioning model을 선보인다. 경험적으로 bottom-up attention의 포함은 image captioning에 상당한 이익이 있었다. MSCOCO test server에 대한 결과가 SOTA를 달성한다. 넓은 응용력을 입증하기 위해 동일한 bottom-up attention features로 VQA model을 추가로 선보인다. 이 모델을 사용해 2017 VQA Challenge에서 1등을 했다.
image I가 주어졌을 때 image captioning model과 VQA model은 둘 다 possibly variably-sized set of k image features 를 input으로 받는다. 각 image feature은 image의 salient region을 encode한다. spatial image features V는 bottom-up attention model의 output이나 일반적인 관행을 따라 CNN의 spatial output layer로 다양하게 정의될 수 있다. top-down attention component의 경우 image captioning model과 VQA model 둘 다 (최근 모델의 복잡한 schemes와 달리) 단순한 one-pass attention mechanisms을 사용함에 주의하라.
- Bottom-Up Attention Model
spatial image features V의 정의는 포괄적이다(generic). 그러나 여기서는 sptial regions을 bounding boxes의 측면에서 정의하고 Faster R-CNN을 사용해 bottom-up attention을 구현한다. Faster R-CNN은 특정 classes에 속하는 objects의 instances를 식별하고 그들을 bounding boxes로 localize하기 위해 디자인된 object detection model이다. 다른 region proposal networks도 attentive mechanism으로서 훈련될 수 있다.
Faster R-CNN은 두 단계로 사물을 감지한다. 첫 단계는 Region Proposal Network (RPN)이며 object proposals을 예측한다. 작은 네트워크가 CNN의 intermediate level에서 features 위를 slide한다. 각 spatial location에서 네트워크는 class-agnostic objectness score와 (다양한 scales와 aspect ratios의) anchor boxes에 대한 bounding box refinement을 예측한다. intersection-over-union (IoU) threshold를 가진 greedy non-maximum suppression을 사용해 top box proposals가 2단계의 input으로 선택된다. 2단계에선 각 box proposal에 대해 작은 feature map (예를 들어 14×14)을 추출하기 위해 region of interest (RoI) pooling이 사용된다. 이 feature maps는 CNN의 final layers로의 input으로서 함께 batch된다. model의 final output은 각 box proposal에 대해 class labels의 softmax distribution과 class-specific bounding box refinements로 구성된다.
논문은 ResNet-101 [13] CNN와 함께 Faster R-CNN을 사용한다. image captioning나 VQA에 사용할 set of image features V를 생성하기 위해 모델의 final output을 받아 각 object class에 대해 (IoU threshold를 사용해) non-maximum suppression을 수행한다. 그 다음 class detection probability가 confidence threshold를 초과하는 모든 regions을 선택한다. 선택된 각 region i에 대해 이 region에서 mean-pooled convolutional feature로 가 정의된다. image feature vectors의 dimension D는 2048이다. 이런 식으로 사용되며 Faster R-CNN은 (대량의 선택지에서 상대적으로 적은 수의 image bounding box features만 선택되기 때문에) ‘hard’ attention mechanism로서 효과적으로 기능한다.
bottom-up attention model을 pretrain하기 위해 먼저 Faster R-CNN with ResNet-101을 ImageNet에 pretrain하고 Visual Genome data에 훈련시킨다. 좋은 feature representations의 학습을 돕기 위해 (object classes에 추가로) attribute classes을 예측하기 위해 추가적인 training output을 추가한다. region i에 대한 attributes를 예측하기 위해 mean pooled convolutional feature 를 ground-truth object class의 learned embedding와 concatenate하고 이를 각 attribute class + ‘no attributes’ class에 대한 softmax distribution을 정의하는 추가적인 output layer에 먹인다.

original Faster R-CNN multi-task loss function은 4가지 요소로 구성되는데 각각 RPN와 final object class proposals에 대한 classification과 bounding box regression outputs으로 정의된다. 논문은 이 요소들을 유지하고 attribute predictor를 학습시키기 위한 추가적인 multi-class loss component를 추가한다.
- Captioning Model
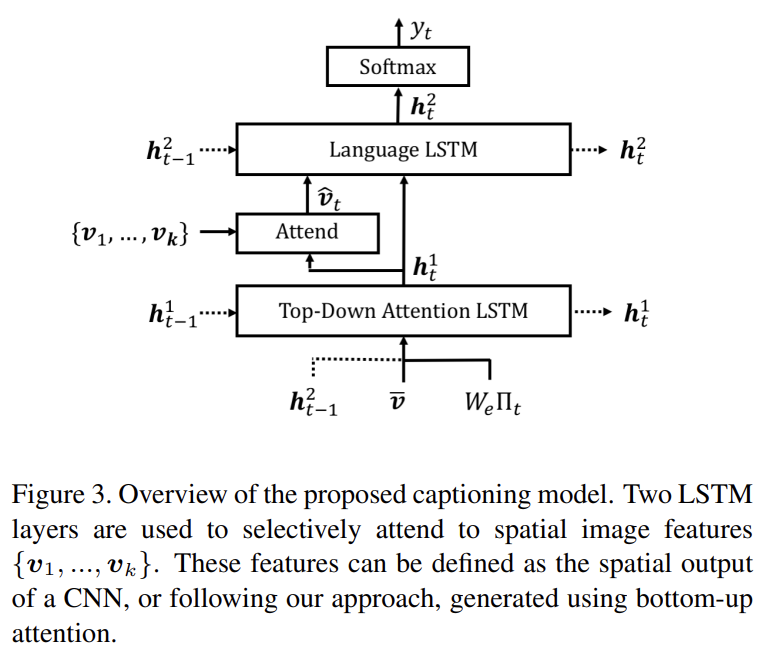
set of image features V가 주어졌을 때 captioning model은 caption generation 중 각 feature을 weight하기 위해 existing partial output sequence을 context로 써서 ‘soft’ top-down attention mechanism을 사용한다. (심지어 bottom-up attention 없이도 논문의 captioning model은 SOTA를 달성한다)
high level에서 captioning model은 (standard implementation를 사용한) 2 LSTM layers로 구성된다. single time step에 대한 LSTM의 작동을 다음과 같이 표기한다.
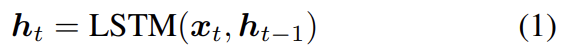
는 LSTM input vector이고 는 LSTM output vector다. 표기의 편의를 위해 memory cells의 전파는 생략했다. 이제 모델의 각 layer에 대해 LSTM input vector 와 output vector 의 formulation을 설명한다.
- Top-Down Attention LSTM
captioning model 내에서 첫번째 LSTM layer을 top-down visual attention model로, 두번째 LSTM layer를 language model로 특징짓는다(각 layer는 식에서 윗첨자로 표시). bottom-up attention model은 앞서 설명했으며 그것의 outputs은 단순히 features V로 생각됨에 주의하라. 각 time step에서 attention LSTM로의 input vector는 다음과 같이 language LSTM의 previous output와 mean-pooled image feature 와 previously generated word의 encoding의 concatenation으로 구성된다.
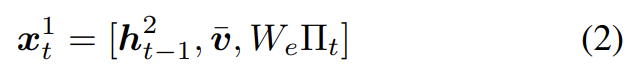
은 vocabulary Σ에 대한 word embedding matrix고 는 timestep t에서 input word의 one-hot encoding이다. 이 inputs는 attention LSTM에게 language
LSTM의 state에 관한 최대 context와 이미지의 전체적인 content와 현재까지 생성된 partial caption output을 제공한다. word embedding은 pretraining 없이 random initialization에서 학습됐다.
attention LSTM의 output 가 주어졌을 때 각 timestep t에서 각 k image features 에 대해 다음과 같이 normalized attention weight 를 생성한다.
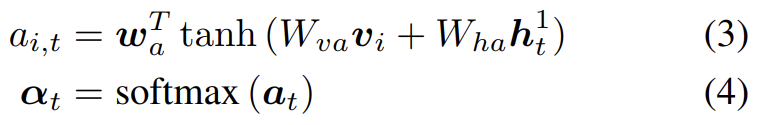
는 learned parameters다. language LSTM로의 input으로 사용된 attended image feature은 모든 input features의 convex combination으로 계산된다.
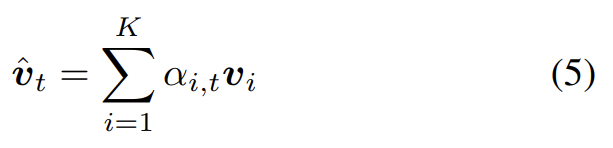
- Language LSTM
language model LSTM으로의 input은 다음과 같이 attended image feature와 attention LSTM의 output의 concatenation으로 구성된다.

sequence of words 를 로 표기한다. 각 timestep t에서 possible output words에 대한 conditional distribution은 다음과 같다.
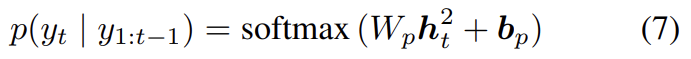
는 학습된 weights와 biases다. complete output sequences에 대한 distribution은 conditional distributions의 곱으로 계산된다.
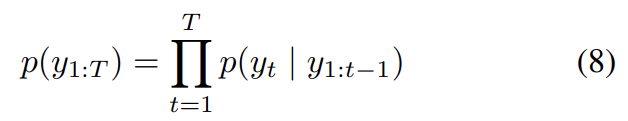
- Objective
target ground truth sequence 와 parameters θ를 가진 captioning model이 주어졌을 때, 다음과 같은 cross entropy loss를 최소화한다.
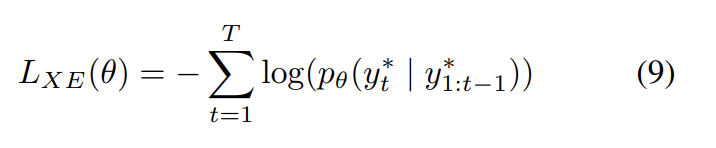
최근 연구 [34]와 공평한 비교를 위해 CIDEr에 대해 최적화된 결과도 기록한다. cross-entropy trained model에서 초기화해서 negative expected score를 최소화한다.
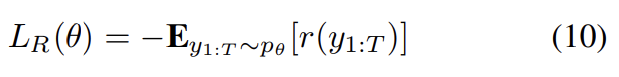
r은 score function (e.g., CIDEr)이다. Self-Critical Sequence Training 34로 묘사된 방식을 따라 이 loss의 gradient는 다음과 같이 계산할 수 있다.
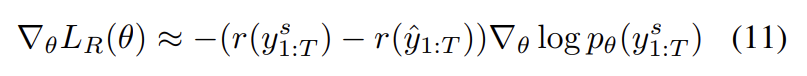
는 sampled caption이고 는 current model을 greedy하게 decoding하여 얻은 baseline score이다. (다른 REINFORCE [44] algorithms처럼) SCST는 training 중 policy로부터 sampling함으로써 space of captions을 탐구한다. 이 gradient는 current model로부터의 score보다 높게 score되는 sampled captions의 probability를 증가시킨다.
실험에선 SCST를 따르지만 sampling distribution을 제한함으로써 학습 절차를 가속한다. beam search decoding을 사용해 decoded beam 내에서만 captions을 sample한다. 경험적으로 beam search를 사용해 decoding하면 resulting beam이 일반적으로 최소한 하나의 very high scoring caption을 지님을 관측했다(비록 자주 이 caption이 집합 내에서 log-probability가 가장 높지는 않을지라도). 반대로 아주 적은 unrestricted caption samples가 greedily-decoded caption보다 높게 score됐다. 이 방식을 사용해 single epoch 만에 CIDEr optimization을 완료했다.
- VQA Model
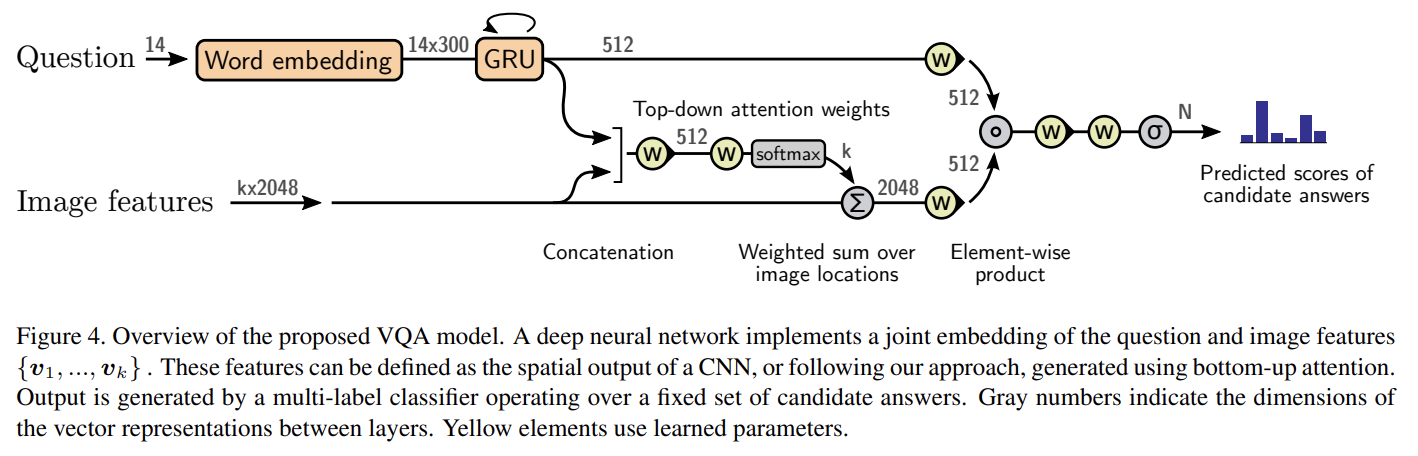
set of spatial image features V가 주어졌을 때, VQA model도 각 feature를 weight하기 위해 question representation을 context로 삼아 ‘soft’ top-down attention mechanism을 사용한다. Fig 4에서 볼 수 있듯 모델은 잘 알려진 question과 image의 joint multimodal embedding을 구현하며 set of candidate answers에 대한(over) scores의 regression을 예측한다. 이 방식은 많은 기존 연구의 바탕이었다. 그러나 우리의 captioning model의 경우 이 상대적으로 단순한 모델이 높은 성능을 보이기 위해 implementation decisions이 중요하다.
네트워크 내의 learned non-linear transformations은 gated hyperbolic tangent activations으로 구현된다. 이들은 highway networks의 특수한 경우인데 전통적인 ReLU나 tanh layers에 대해 경험적으로 강한 우위(advantage)를 가진다. 각각의 ‘gated tanh’ layers는 다음과 같이 (parameters a = {W, W', b, b'}를 가진) function 를 구현한다.
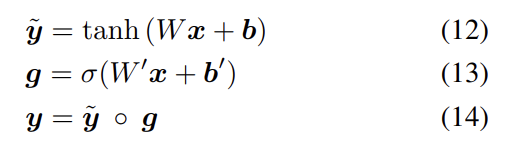
σ는 sigmoid activation function이고 는 learned weights고, 는 learned biases고, ◦는 Hadamard (element-wise) product이다. vector g는 intermediate activation 에 gate로서 곱셈으로 작동한다.
논문의 방식은 먼저 각 question을 gated recurrent unit 5의 hidden state q로 encode한다(각 input word가 learned word embedding으로 표현된다). 식 (3)과 비슷하게 GRU의 output q가 주어졌을 때, 각 k image features 에 대한 unnormalized attention weight 를 다음과 같이 생성한다.
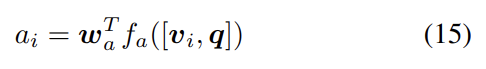
는 learned parameter vector다. 식 (4)와 식 (5)는 (아래첨자 t를 무시하고) normalized attention weight과 attended image feature 를 계산하기 위해 사용된다. 가능한 output responses y에 대한 distribution은 다음과 같다.
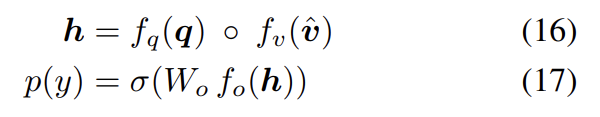
h는 question과 image의 joint representation이고 는 learned weights이다.
Visual Genome dataset을 bottom-up attention model을 pretrain하기 위해 사용하고 VQA model을 학습할 때 data augmentation을 위해 사용한다. (이하 생략)
captioning model을 평가하기 위해 MSCOCO 2014 captions dataset을 사용한다. VQA model을 평가하기 위해 VQA v2.0 dataset을 사용한다.
bottom-up attention의 효과를 측정하기 위해 captioning과 VQA 실험 둘 다 full model (Up-Down)을 기존 연구, ablated baseline과 비교한다. 각 경우에서 baseline (ResNet)은 bottom-up attention mechanism 대신 각 image를 encode하기 위해 ImageNet에 pretrain된 ResNet CNN을 사용한다. (이하 생략)
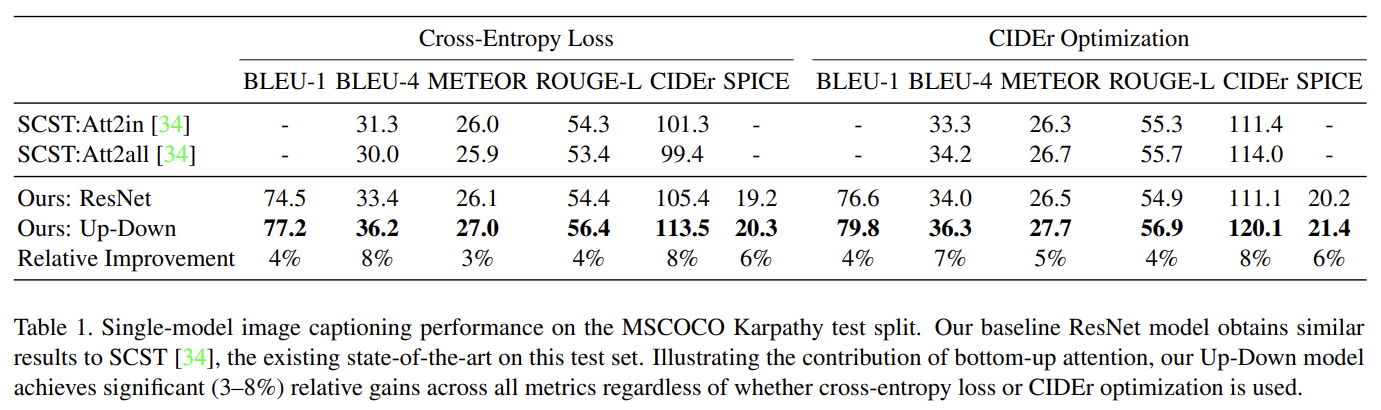
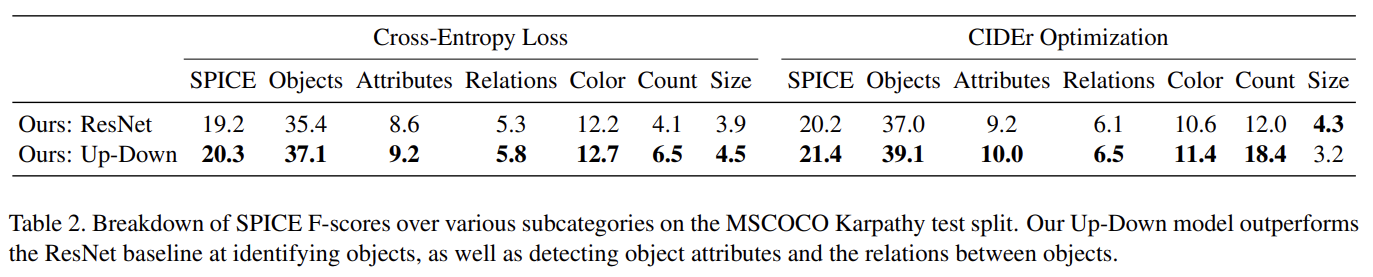
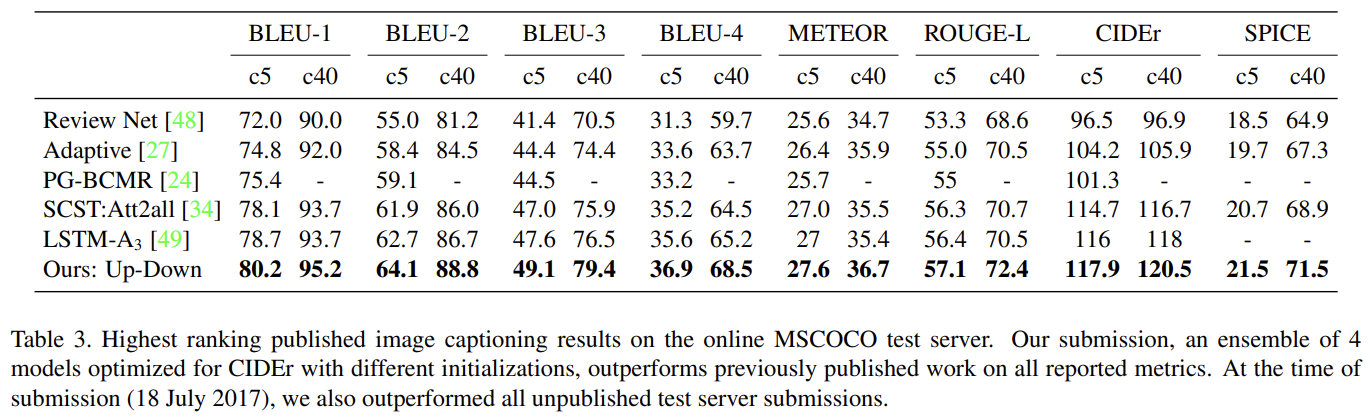
Tab 1은 full model과 ResNet baseline을 기존 SOTA인 SCST와 비교한다. Tab 2에서 알 수 있듯 bottom-up attention의 기여가 크다. Tab 3는 official MSCOCO evaluation server에 CIDEr optimization을 가지고 학습된 4 ensembled models의 성능을 평가한 것이다.
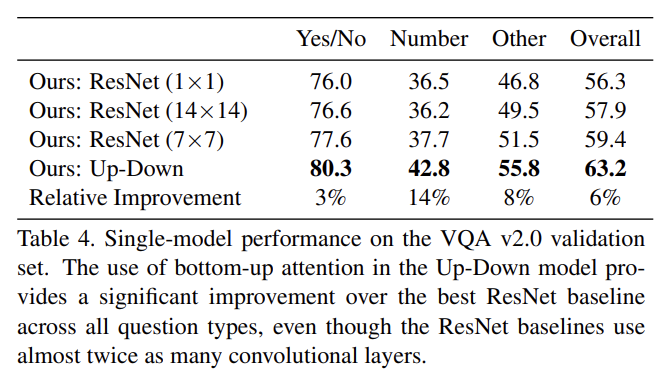
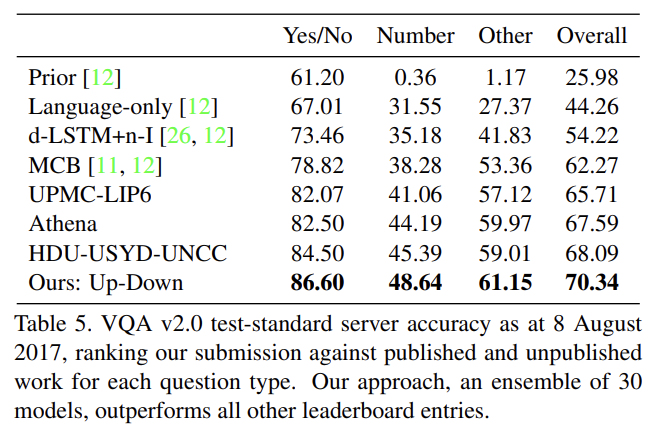
Tab 4는 VQA v2.0 validation set에 full Up-Down VQA model의 single model performance을 몇몇 ResNet baseline과 비교한 것이다. ResNet baseline이 거의 2배 많은 convolutional layers를 사용함에도 불구하고 bottom-up attention의 추가는 모든 question types에 걸쳐(across) best ResNet baseline보다 상당한 성능 향상을 제공한다. Tab 5는 official VQA 2.0 test-standard evaluation server에 30 ensembled models의 성능을 보여준다. 다른 모든 test server submissions보다 뛰어나며 2017 VQA Challenge에서 1등을 차지했다.


질적 평가를 위해 Fig 5에서 Up-Down captioning model가 생성한 여러 words에 대한 attended image regions을 시각화한다. 우리의 방식은 fine details나 large image regions에 동등하게 집중할 수 있다. 이 능력은 모델 내의 attention candidates가 (각각 object나 관련된 여러 objects나 salient image patch에 align된) 다양한 scales와 aspect ratios를 가지는 많은 겹치는 regions으로 구성되기 때문이다.
기존 방식과 달리 candidate attention region이 object나 관련된 여러 objects에 상응하면 그 objects와 연관된 모든 visual concepts이 공간적으로 co-related한 것으로 보이고 함께 처리된다. 다시 말해, 우리의 방식은 object에 관련된 모든 정보를 한 번에 고려할 수 있다. 이는 또한 attention이 구현되는 자연스러운 방법이다. human visual system에서 separate features of objects을 올바른 조합으로 통합하는 문제를 feature binding problem이라고 부르는데 선행 연구들은 solution에 attention이 핵심적인 역할을 한다고 주장한다. Fig 6는 VQA attention의 예시다.
Strenghts
- 인간의 시각과 집중을 모방해 기존의 top-down attention 방식과 논문의 bottom-up attention을 결합한 아이디어가 흥미로웠다.
- Fig 1에서 볼 수 있듯 전체 image를 attention하는 게 아니라 bottom-up 방식으로 Faster R-CNN을 통해 RoI를 추출한 후 그걸 attention했다. 직관적으로 생각할 때 이 방법이 더 효율적이다.
