오늘 리뷰할 논문은 Bidirectional Encoder Representations from
Transformers, BERT 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [최대한 자세하게 설명한 논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (1)
- [NLP | 논문리뷰] BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding 상편
- BERT 논문 정리(리뷰)- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding paper review
Summary
최근 language representation models와 달리 BERT는 모든 layers에서 왼쪽과 오른쪽 context를 모두 공동으로 conditioning해서 unlabeled text로부터 deep bidirectional representations을 pre-train하도록 디자인되었다. 결과적으로 pre-trained BERT model는 하나의 output layer을 추가해 (task specific한 architecture 수정 없이) 여러 task에서 SOTA를 달성하도록 fine-tune될 수 있다.
pre-trained language representations을 downstream tasks에 적용하는 두 가지 방법은 feature-based와 fine-tuning이다. ELMo 같은 feature-based 방식은 pre-trained representations를 additional features로 포함해 task-specific architectures를 사용한다. GPT 같은 fine-tuning 방식은 task-specific parameters를 최소한으로 도입하며 모든 pre-trained parmeters를 fine-tuning하여 downstream tasks를 학습한다.
그러나 논문은 현재의 방식들은 (특히 fine-tuning 방식이) pre-trained representations의 능력을 제한한다고 주장한다. 주된 한계는 standard language models가 unidirectional하다는 것이며, 이는 pre-training 중 사용될 수 있는 architecture의 선택지를 제한한다. 예를 들어 GPT는 left-toright architecture 사용하는데 모든 token이 transformer의 self-attention layers에서 previous tokens에만 attend할 수 있다. 이런 제한은 sentence-level tasks에 sub-optimal하며 fine-tuning 방식을 (question answering처럼 양방향에서의 context를 포함하는 게 중요한) token-level tasks에 적용할 때 몹시 해로울 수 있다.
논문은 BERT를 제안해 fine-tuning 방식을 발전하고자 한다. BERT는 Cloze task (Taylor, 1953)에서 영감을 받은 “masked language model” (MLM) pre-training objective를 사용해 앞서 설명한 unidirectionality constraint를 완화하고자 한다. masked language model은 input에서 몇 개의 token을 랜덤하게 mask하고 목표는 context에 기반해 masked word의 original vocabulary id를 예측하는 것이다. left-toright language model pre-training과 달리 MLM objective은 representation이 left와 right context를 융합하게 하며 deep bidirectional Transformer를 pre-train할 수 있게 한다. MLM 뿐만 아니라 text-pair representations를 공동으로 pre-train하는 “next sentence prediction” task도 사용한다.
논문의 기여는 다음과 같다.

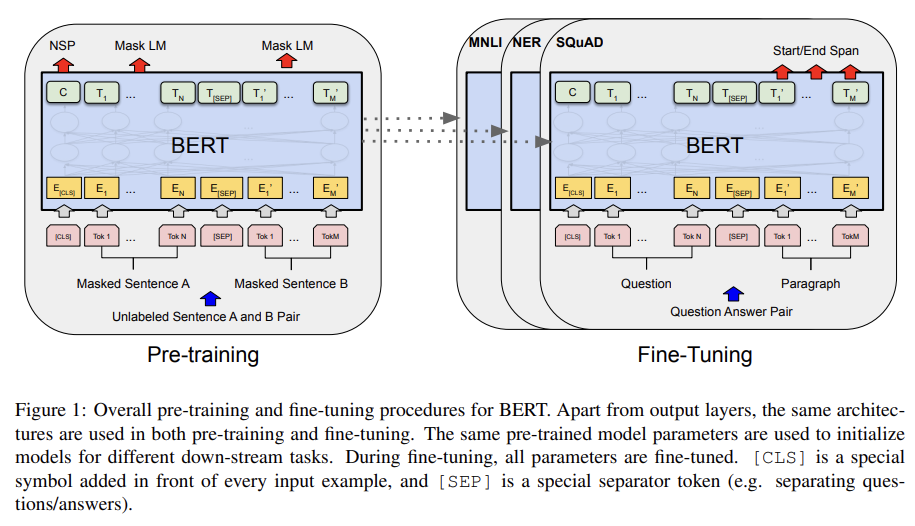
BERT framework는 두 단계, pre-training과 fine-tuning로 이루어진다. pre-training에서 모델은 여러 pre-training task에 unlabeled data로 훈련된다. fine-tuning에서는 먼저 모델이 pre-trained parameters로 초기화된 후 downstream task의 labeled data를 사용해 모든 parameter가 fine-tune된다. 각 downstream task가 (동일한 pre-trained parameters로 초기화되지만) 각기 다른 fine-tunded model을 가진다.
BERT의 독특한 특징은 서로 다른 tasks에 걸친 unified architecture이다. pre-trained architecture와 final downstream architecture 사이엔 최소한의 차이만 존재한다.
BERT의 모델 architecture은 Vaswani et al. (2017) (Attention is all you need)에서 기반한 multi-layer bidirectional Transformer encoder이다.
논문에서는 layer(Transformer blocks)의 수를 L, hidden size를 H, self-attention heads의 수를 A라고 둔다. 그리고 두 가지 크기의 모델 (L=12, H=768, A=12, Total Parameters=110M)와 (L=24, H=1024,
A=16, Total Parameters=340M)를 가지고 실험한다. 는 비교를 목적으로 GPT와 같은 크기로 디자인됐다. 그러나 BERT Transformer는 bidirectional self-attention를 사용하고 GPT Transformer는 (모든 token이 왼쪽 context만 attend할 수 있는) constrained self-attention을 사용한다.
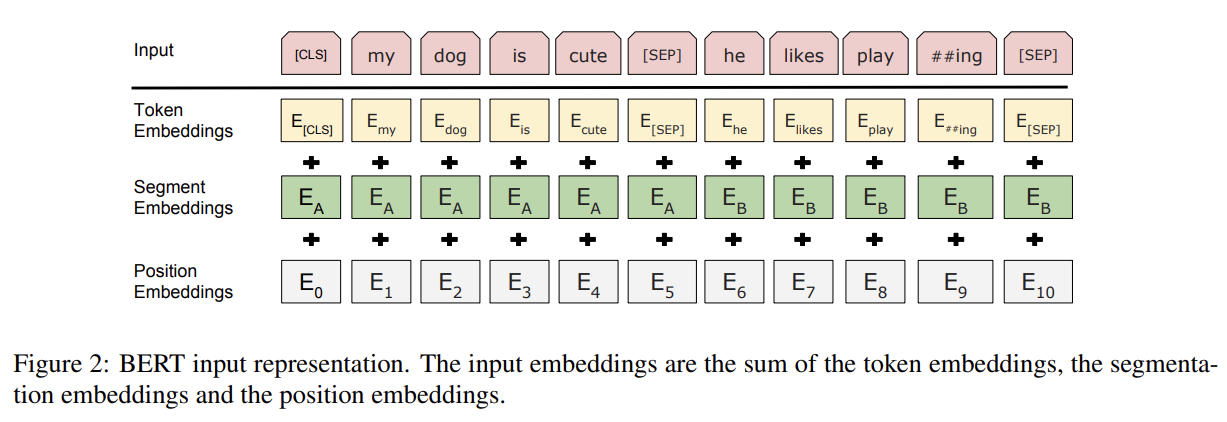
BERT가 다양한 down-stream tasks를 처리할 수 있게 하기 위해 우리의 input representation은 single sentence와 pair of sentence를 명료하게 하나의 token sequence 안에 표현할 수 있다. (논문에서 sentence는 언어적 의미의 문장 말고 contiguous text의 arbitrary span이 될 수 있다. "sequence"는 BERT로의 input token sequence를 의미하며 single sentence나 two sentences packed together가 될 수 있다.)
30,000 token vocabulary를 가진 WordPiece embeddings (Wu et al., 2016)를 사용한다. 모든 sequence의 첫 token은 항상 special classification token ([CLS])이다. 이 token에 상응하는 final hidden state는 classification task를 위한 aggregate sequence representation로 사용된다. sentence pairs는 single sequence로 pack된다. sentence는 두 가지 방법으로 구분한다. 우선 special
token ([SEP])로 분리하고, 둘째로 sentence A에 속하는지 sentence B에 속하는지 나타내는 learned embedding를 모든 token에 더한다. input embedding은 E라고 표기하며 special [CLS] token의 final hidden vector을 라고 표기하고 i번째 input token의 final hidden vector를 라고 표기한다. 주어진 token의 input representation은 corresponding token embedding(WordPiece embedding을 사용), segment embedding(문장 A인지 B인지 구분), position embeddings(Transformer 원본 논문과 동일)을 합함으로써 구성된다.
BERT의 pre-train은 두 가지 unsupervised tasks로 훈련한다.
- Task #1: Masked LM
standard conditional language models는 left-to-right이나 right-to-left로만 학습될 수 있는데, bidirectional conditioning은 각 word가 직접 자기자신을 볼 수 있게 하기 때문에 모델이 multi-layered context에서 target word를 너무 쉽게 예측할 수 있기 때문이다.
deep bidirectional representation를 학습하려면 input tokens의 일부를 랜덤하게 mask하고 그 masked tokens을 예측해야 한다. 이 과정을 “masked LM” (MLM)라고 부른다. mask tokens에 상응하는 final hidden vectors이 vocabulary에 대한 output softmax로 먹여진다. 모든 실험에서 각 sequence 내의 WordPiece tokens의 15%를 랜덤하게 mask한다.
이는 bidirectional pre-trained model를 얻을 수 있게 하지만, 단점은 [MASK] token이 fine-tuning 중에는 나타나지 않기 때문에 pre-training과 fine-tuning 사이 mismatch가 만들어진다는 것이다. 이를 완화하기 위해 "masked" word를 항상 [MASK] token로 바꾸지는 않는다. training data generator가 prediction을 위해 랜덤하게 15%의 token positions을 고른다. i번째 token이 선택됐을 때, 그 토큰을 80% 확률로 [MASK] token으로 바꾸거나 10% 확률로 랜덤 토큰으로 바꾸거나 10% 확률로 unchanged i-th token로 바꾼다. 그리고 나서 original token을 예측하기 위해 cross entropy loss를 가지고 Ti가 사용된다.
- Task #2: Next Sentence Prediction (NSP)
Question Answering (QA)와 Natural Language Inference (NLI)처럼 많은 중요한 downstream tasks가 두 문장 간의 관계를 이해하는 데 기반하는데, 이는 language modeling으로 직접 포착되지 않는다. sentence relationship을 이해하도록 학습하기 위해 (어떤 monolingual corpus에서도 쉽게 생성할 수 있는) binarized next sentence prediction task를 pre-train한다. 구체적으로는, 각 pretraining exmple에서 sentence A와 B를 고를 때 50% 확률로 B는 실제로 A 다음에 나오는 문장이고(labeled as IsNext), 50% 확률로 corpus에서 랜덤하게 뽑은 문장이다(labeled as NotNext). next sentence prediction (NSP)을 위해 C가 사용된다.
pre-training corpus는 BooksCorpus (800M words) (Zhu et al.,
2015)와 English Wikipedia (2,500M words)를 사용했다.
fine-tuning은 간단한데 transformer의 self-attention mechanism이 BERT가 많은 downstream tasks를 model하도록 허용하기 때문이다. BERT는 self-attention mechanism를 사용하며 self-attention을 가지고 concatenated text pair를 encoding하는 것이 두 sentence 사이 bidirectional cross attention를 포함한다.
각 task에 대해 단순히 task specific inputs와 outputs를 넣고 모든 parameter를 end-to-end로 fine-tune한다. input에서 pre-training의 sentence A와 B는 (1) sentence pairs in paraphrasing, (2) hypothesis-premise pairs in entailment, (3) question-passage pairs in question answering, (4) degenerate text-∅ pair in text classification or sequence tagging와 유사하다. output에서 sequence tagging나 question
answering 같은 token-level tasks을 위해 token representations이 output layer에 먹여지며 [CLS] representation은 entailment나 sentiment analysis 같은 classification을 위해 output layer에 먹여진다.
pre-training에 비해 fine-tuning은 상대적으로 덜 비싸다.
실험은 11 NLP tasks에 fine-tune한다.
- GLUE
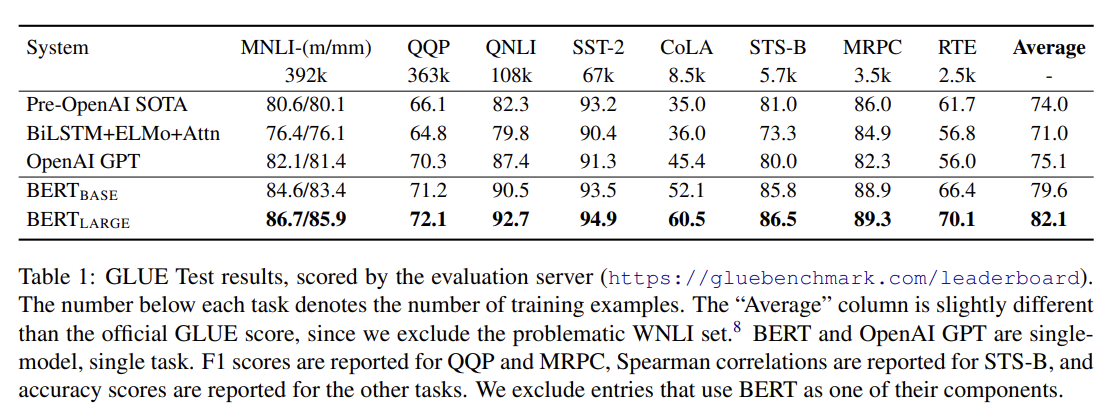
General Language Understanding Evaluation (GLUE) benchmark (Wang et al., 2018a)는 다양한 natural language understanding
tasks의 집합이다. fine-tuning 중 새로 도입된 유일한 parameter은 classification layer weights 이며 K는 label 수다. C와 W를 가지고 standard classification loss 를 계산한다. 둘 다 모든 task에서 상당한 margin으로 SOTA를 달성한다. 는 보다 모든 task에서 (특히 training data가 작을 때) 상당히 더 성능이 좋았다.
- SQuAD v1.1
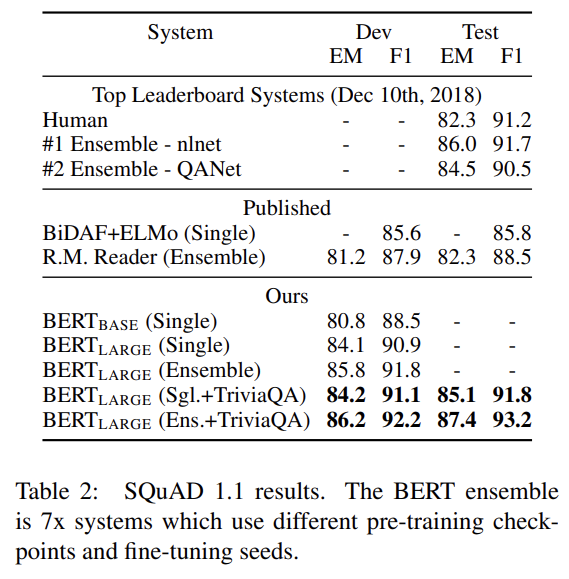
Stanford Question Answering Dataset (SQuAD v1.1)은 100k crowdsourced question/answer pairs의 모음이다. 질문과 위키피디아에서 온 passage를 받아 passage 내의 answer text span를 예측하는 것이다. Fig 1에서 볼 수 있듯 question answering task에서 input question와 passage를 single packed sequence로 표현하고, question은 A embedding을 passage는 B embedding을 사용한다. fine-tuning 중 start vector 와 end vector 를 도입한다. word i가 answer span의 시작일 확률은 Ti와 S의 dot product 이후 paragraph 내의 모든 word에 대한 softmax로 계산한다. (이하 설명 생략)
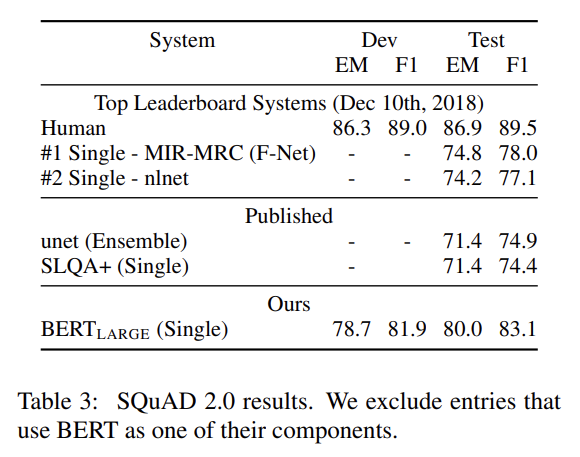
- SQuAD v2.0
주어진 passage에 short answer가 존재하지 않을 가능성을 허용해 더 realistic하게 SQuAD 1.1 problem definition을 확장한 것이다. 설명은 생략한다.
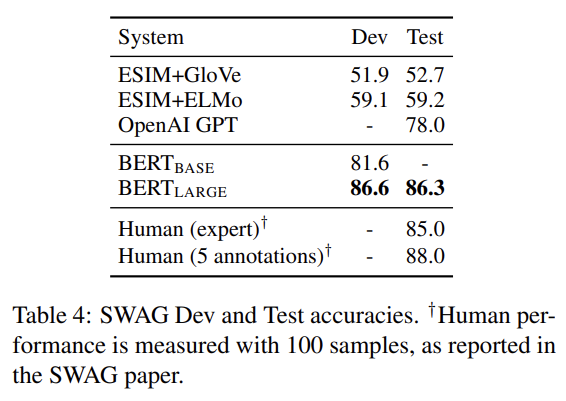
- SWAG
Situations With Adversarial Generations (SWAG) dataset은 grounded commonsense inference를 평가하는 113k sentence-pair completion examples를 포함한다. sentence가 주여졌을 때 4가지 선택지 중 가장 설득력 있는 continuation을 선택하는 과제다. 설명은 생략한다.
ablation study도 한다.
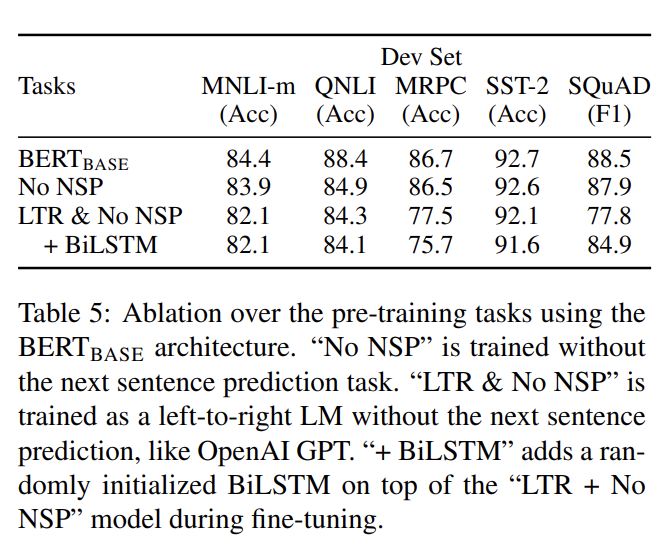
- Effect of Pre-training Tasks
와 동일한 pre-training data, fine-tuning scheme, hyperparameters를 사용하는 두 pre-training objectives를 평가함으로써 BERT의 deep bidirectionality의 중요성을 입증한다.
- No NSP : “masked LM” (MLM)은 사용하지만 “next sentence prediction” (NSP) task은 없이 학습한 bidirectional model
- LTR & No NSP : MLM 대신 standard Left-to-Right (LTR)
LM를 사용해 학습한 left-context-only model. NSP도 사용하지 않음.
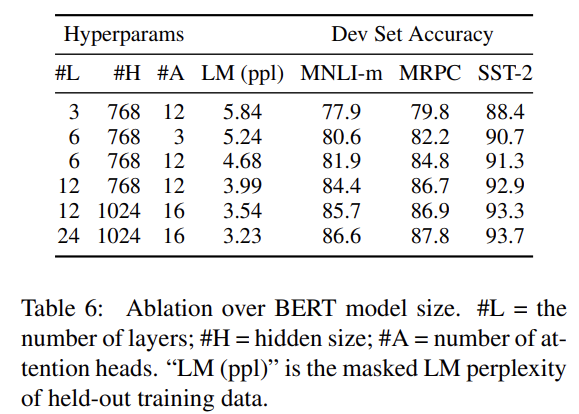
- Effect of Model Size
layer, hidden unit, attention head 숫자를 다르게 한 여러 BERT 모델의 fine-tuning task accuracy을 비교한다. 크기가 클수록 4 데이터셋에서 모두 성능 향상이 있었다. 또 논문은 최초로 very small scale
tasks에도 (모델이 충분히 pre-train되었다면) extreme model sizes로 scaling하는 것이 성능을 크게 향상시킴을 입증했다.
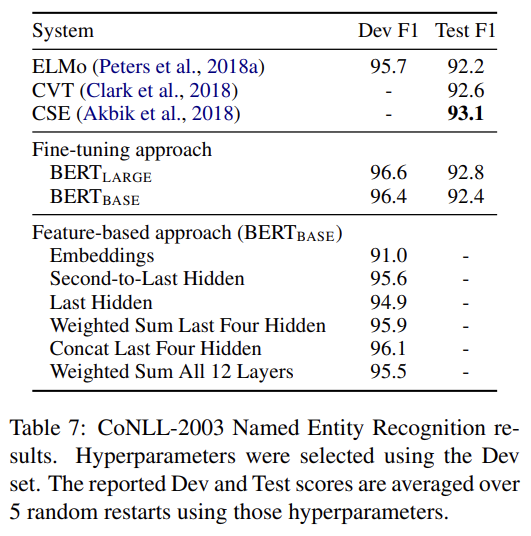
- Feature-based Approach with BERT
여태까지 실험 결과는 pre-trained model에 간단한 classification layer을 붙여서 모든 parameter를 downstream task에 fine-tune하는 방식이었다. 그러나 pre-trained model에서 fixed features를 추출하는 feature-based 방식도 장점이 있다. 그래서 BERT를 CoNLL-2003 Named Entity Recognition (NER) task에 적용해 두 방식을 비교했다. (중략) 결과는 BERT가 fine-tuning과 feature-based 방식 모두에 효과적임을 보여준다.
Strengths
- pre-training에서 MLM과 NSP를 잘 설계해서 bidirectional context를 활용하도록 학습한 것이 성능에 중요한 것 같다.
- 큰 모델이 충분히 fine-tuned되었고 downstream task에서 적은 숫자의 randomly initialized additional parameters를 사용한다면 downstream task의 데이터가 매우 적더라도 larger, more expressive pre-trained representations로 이득을 볼 수 있음을 보였다.
