오늘 리뷰할 논문은 BART 논문이다. Bidirectional Auto-Regressive Transformer라는 이름답게 BERT (Bidirectional Encoder Representation from Transformer)의 bidirectional한 특성과 GPT의 auto-regressive한 특성을 합친 형태로, 기존 Sequence to Sequence 트랜스포머 모델을 새로운 Pre-training objective를 통해 학습하여 하나로 합친 모델이라고 한다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문리뷰] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- [논문 리뷰] BART - FacerAin
Summary
논문은 sequence-to-sequence models을 pre-training하는 denoising autoencoder인 BART를 소개한다. BART는 arbitrary noising function로 오염된 text로 훈련되며 original text를 reconstruct하도록 학습된다. architecture은 standard Tranformer-based neural machine translation architecture이지만 (simplicity에도 불구하고) BERT (bidirectional encoder)와 GPT (left-to-right decoder) 등 다른 pretraining schemes를 일반화한 것으로 볼 수 있다.
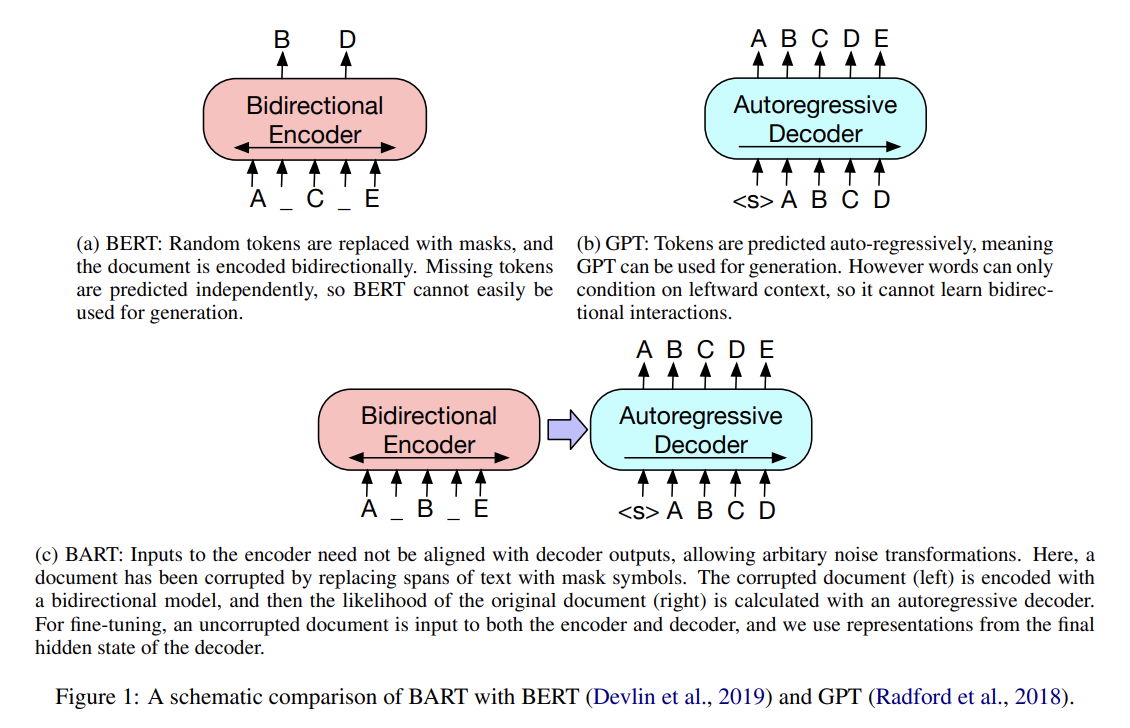
이 setup의 핵심 장점은 noising flexibility, 즉 (길이 변화를 포함해) 임의의 transformation을 original text에 적용할 수 있다는 것이다. 여러 noising approaches을 평가했으며 original sentences의 순서를 랜덤하게 섞는 방법과 (zero length 포함) 임의의 길이의 spans of text를 single mask token으로 대체하는 novel in-filling scheme이 최고의 성능을 보였다. 이 방식들은 모델이 전반적인 문장 길이에 더 신경쓰게 하고 input에 longer range transformations을 줌으로써 BERT의 word masking과 next sentence prediction objectives를 일반화한다. BART는 (fine-tune되었을 때) 특히 generation task에 뛰어나며 comprehension task에도 잘 작동한다.
또한 BART는 fine-tuning을 생각하는 새로운 방식을 제시한다. 논문은 machine translation을 위해 BART가 몇 개의 추가적인 transformer layers 위에 쌓인 새로운 scheme을 제시한다. 이 layers들은 foreign language를 noised English로 번역하도록 훈련되어 BART는 pre-trained target-side language model로 사용된다.
BART는 corrupted document를 original document로 map하는 denoising autoencoder이다. 이는 corrupted text에 대한 bidirectional encoder와 left-to-right autoregressive decoder를 가진 sequence-to-sequence model로 구현된다. pre-training을 위해 original document의 negative log likelihood를 최적화한다.
GPT를 따라 ReLU 대신 GeLU를 사용하고 parameter를 N(0, 0.02)로 초기화한 것 외에는 BART는 원본 논문의(Attention is all you need) standard sequence-to-sequence Transformer architecture를 사용한다. base model은 encoder와 decoder에 6 layers를 사용하고 large model은 각각에 12 layers를 사용한다. architecture은 BERT와 비슷하지만 다음과 같이 다르다. (1) decoder의 각 layer가 encoder의 final hidden layer에 대해 추가적인 cross-attention을 수행하고 (2) BERT는 word-prediction 전에 추가적인 feed-forward network를 사용하지만 BART는 그러지 않는다. 전체적으로 BART는 동일한 크기의 BERT 모델보다 10% 더 많은 parameters를 가진다.
BART는 document를 corrupt한 후 reconstruction loss, 즉 decoder output과 original document 사이 cross-entropy를 최적화함으로써 학습된다. 특정 noising schemes에 맞춘 기존의 denoising autoencoders와 달리 BART는 document corruption을 어떤 종류든 모두 허용한다.
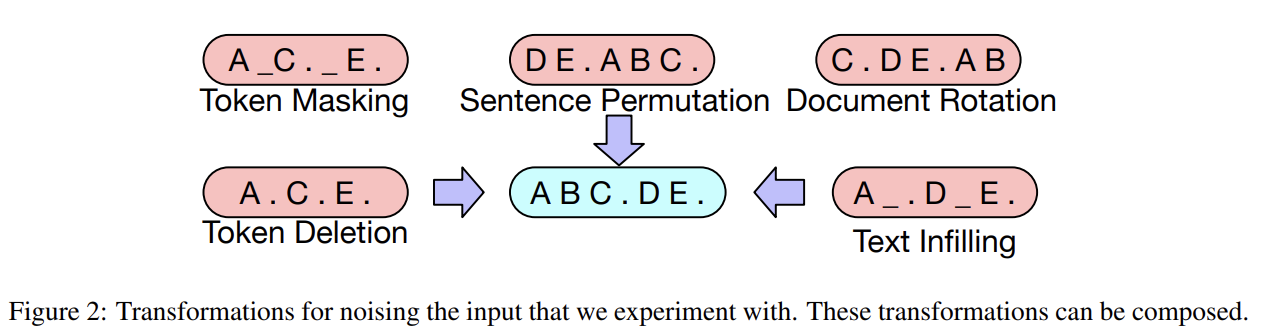
trasnsformation은 기존에 존재하던 것과 논문에서 새로 고안한 것 모두 실험해보며 그 종류는 다음과 같다.


BART로 생성된 representations는 다음과 같은 downstream applications에 사용될 수 있다.
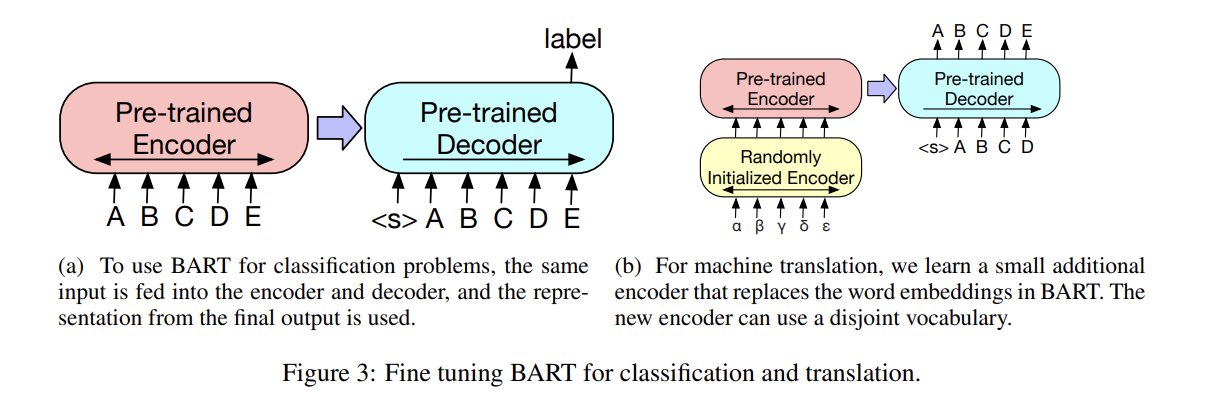
- Sequence Classification Tasks
encoder와 decoder에 동일한 input을 넣고 final decoder token의 final hidden state가 새로운 multi-class linear classifier에 먹여진다. 이는 BERT의 CLS token과 비슷하나 여기서는 end에 additional token을 추가해 decoder에서 token에 대한 representation이 complete input에서 decoder states를 attend할 수 있게 했다.
- Token Classification Tasks
SQuAD의 answer endpoint classification 같은 token classification tasks의 경우 encoder와 decoder에 complete document를 넣고 decoder의 top hidden state를 각 word의 representation으로 삼는다. 이 representation이 token을 classify하는 데 사용된다.
- Sequence Generation Tasks
BART가 autoregressive decoder를 지녔기 때문에 abstractive question answering나 summarization 같은 sequence generation tasks에 직접 fine-tune될 수 있다. 두 경우 다 정보가 input에서 복사되지만 조작되었으며(manipulated), denoising pre-training objective와 비슷하다. encoder input은 input sequence고 decoder은 output을 autoregressive하게 생성한다.
- Machine Translation
기존 연구 Edunov et al. (2019)는 pre-trained encoders를 포함함으로써 model이 향상될 수 있음을 보였으나 decoder의 pre-trained language models를 사용한 성능 향상은 한계가 있었다. 논문은 (bitext로부터 학습한 new set of encoder parameters를 추가함으로써) BART 모델의 encoder와 decoder 모두를 single pretrained decoder로써 사용한다.
더 정확히는 BART의 encoder embedding layer을 새로이 랜덤하게 초기화한 encoder로 대체한다. 모델은 end-to-end로 학습되며 새로운 encoder가 foreign words를 BART가 English로 de-noise할 수 있는 input 형태로 map한다. (즉 BART의 encoder+decoder을 translation decoder로 삼고, translation encoder을 새로 추가한다는 것)
source encoder는 두 단계로 학습하며, 둘 모두 cross-entropy loss를 역전파한다. 첫 단계에서는 대부분의 BART parameters를 freeze한 후 randomly initialized source encoder, BART positional
embeddings와 BART encoder의 첫 layer의 self-attention input projection matrix만 update한다. 두 번째 단계에서는 모든 parameter를 작은 수의 iteration 동안 학습한다.
BART는 pre-training 중 더 많은 noising schemes를 지원한다. 논문은 base-size models (6 encoder and 6 decoder layers, with a hidden size of 768)를 사용해 여러 옵션을 평가한다.
여태껏 여러 pre-training objectives가 제안되었지만 training data, training resources, architectural differences, fine-tuning procedures 등의 차이로 인해 공평한 비교가 힘들다. 논문은 discriminative와 generation tasks에 대해 제안된 강력한 pre-training approaches를 re-implement한다. 가능한 한 이들의 차이가 pre-training objective와 무관하게 조절하려고 한다. 그러나 성능 향상을 위해 각 objective의 learning rate와 layer normalization 사용을 약간씩 조절하기는 한다. 다음 approaches를 비교한다.

Permuted LM, Masked LM와 Multitask Masked LM에 대해 sequence의 output part의 likelihoods를 효율적으로 계산하기 위해 two-stream attention (Yang et al., 2019)을 사용한다.
실험은 (1) task를 standard sequence-to-sequence problem으로 취급해 source input을 encoder에 넣고 decoder ouput이 target이 되는 경우와 (2) source를 target의 prefix에 추가해 decoder에 넣고 sequence의 target part의 loss만 계산한 경우로 했다. 전자가 BART에 적합했고 후자가 다른 model들에 적합했다.
task 설명은 캡처로 대체한다.

실험 결과는 Tab 1과 같다.
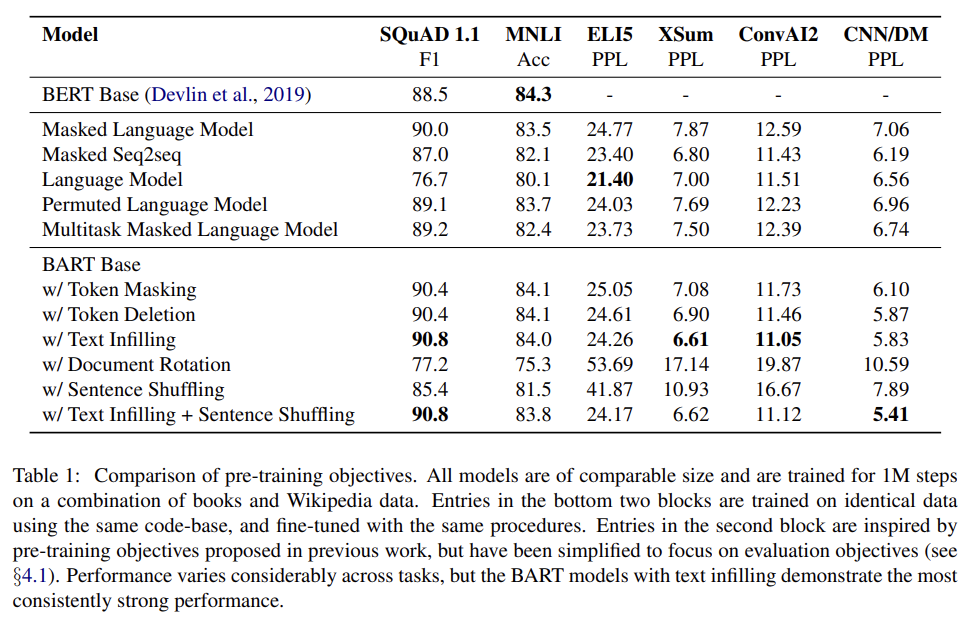
몇 가지 경향이 뚜렷하다. 자세한 설명은 생략한다.
-
Performance of pre-training methods varies significantly across tasks
-
Token masking is crucial
-
Left-to-right pre-training improves generation
-
Bidirectional encoders are crucial for SQuAD
-
The pre-training objective is not the only important
factor -
Pure language models perform best on ELI5
-
BART achieves the most consistently strong performance
최근 연구는 pre-training이 large batch sizes와 corpora로 scale되었을 때 downstream performance가 극적으로 향상될 수 있음을 보였다. 이 점을 확인하기 위해 BART를 RoBERTa와 같은 크기를 사용해 실험을 했다.
encoder와 decoder 각각이 12 layers, hidden size 1024를 가지는 large model을 pre-train했다. RoBERTa를 따라 batch size 8000으로 500000 steps 동안 학습했다. documents는 GPT-2와 동일한 byte-pair encoding로 tokenize되었고 (앞선 실험 결과에 따라 transformation은) text infilling과 sentence permutation의 조합을 사용했다. 각 document의 30%의 tokens을 mask하고 모든 문장을 permute한다. (앞선 base model의 결과에선) sentence permutation이 CNN/DM summarization datase에만 상당한 성능 향상을 보이지만 larger pre-trained models에서는 이 task에서 더 배울 수 있으리라고 가설을 세웠다. model이 data에 더 잘 fit하기 위해 training step의 마지막 10% 동안은 dropout을 하지 않았다. Liu et al. (2019)와 같은 pre-training data를 사용했다.
- Discriminative Tasks
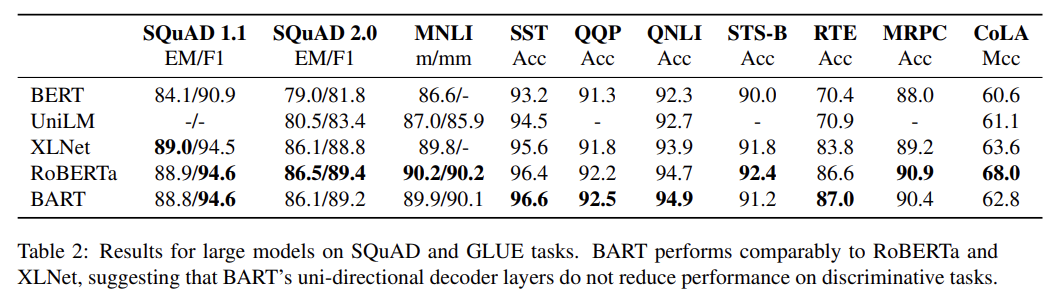
Tab 2는 SQuAD와 GLUE tasks에 BART와 최근 방법들을 비교한다. 가장 직접적으로 비교가능한 baseline은 RoBERTa고, resource가 같지만 다른 objective로 pre-train됐다. 전반적으로 BART의 성능은 다른 모델과 비슷한데, 이는 (곧 설명할) generative tasks에서 BART의 성능 향상이 classification performance를 희생시킨 게 아님을 보여준다.
- Generation Tasks
여러 text generation tasks를 실험한다. BART가 standard sequence-to-sequence model로 fine-tune되며 fine-tuning 도중 label smoothed cross entropy loss (Pereyra et al., 2017)를 사용한다. generation 중에 beam size는 5로 두고 beam search에서 duplicated trigrams는 제거했고 모델을 validation set에 min-len, max-len, length penalty를 가지고 tune했다.
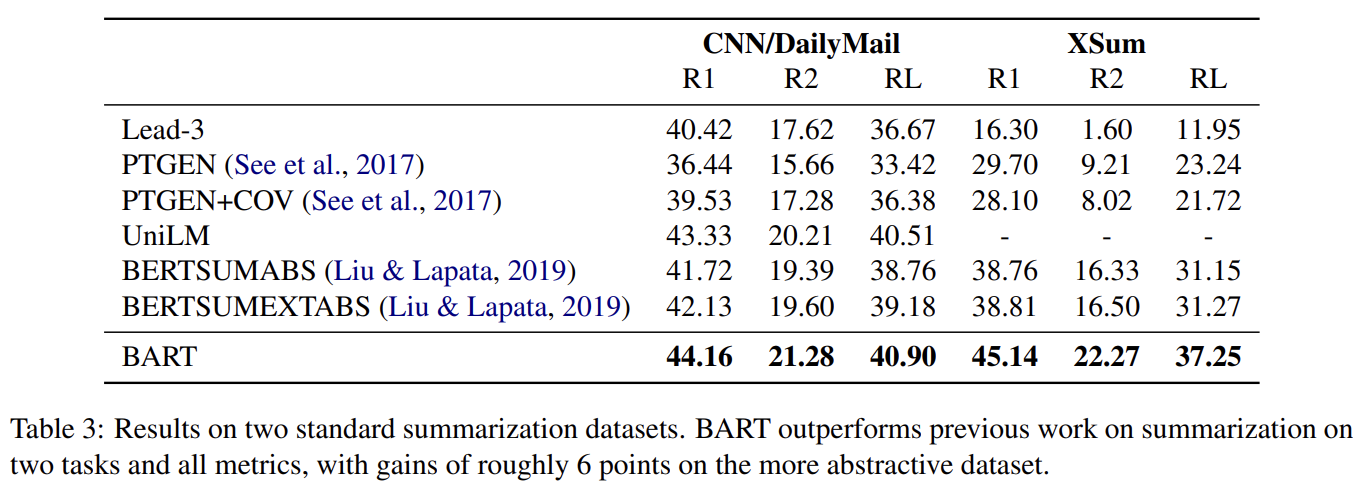
summarization task에서 SOTA와의 비교를 위해 서로 다른 특징을 가진 두 데이터셋 CNN/DailyMail와 XSum에 실험했다. CNN/DailyMail의 요약은 source sentence를 닮는다. Extractive models이 잘 작동하며 baseline들도 잘 작동한다. 그럼에도 BART는 모든 기존 연구보다 성능이 뛰어나다. 반면 XSum은 몹시 추상적이며, extractive models가 잘 작동하지 못한다. BART는 best previous work를 뛰어넘는다.
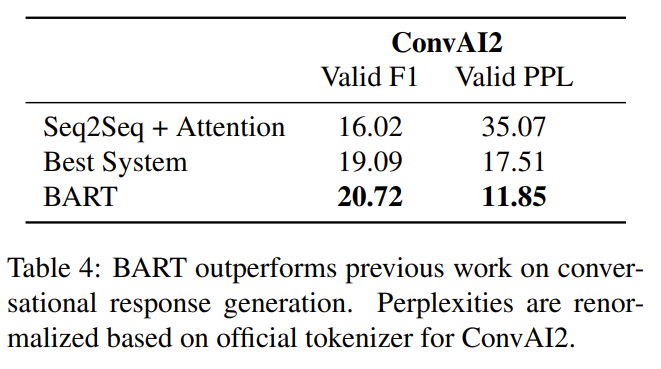
ConvA12에 agents가 previous context와 textually-specified persona 모두에 condition되어 response를 생성하는 dialogue response generation을 평가한다. BART는 두 automated metrics에서 기존의 연구를 뛰어넘는다.
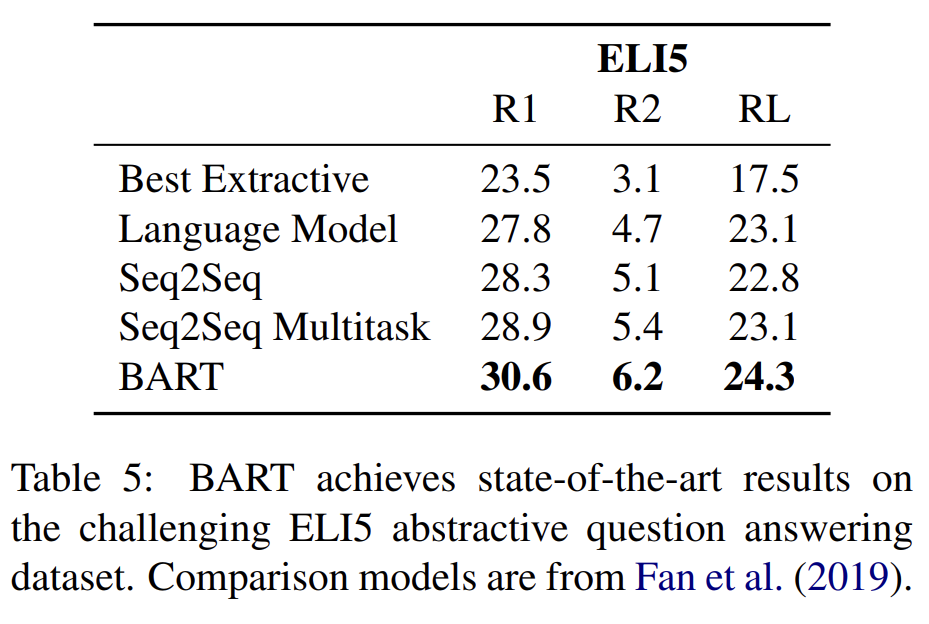
최근에 제안된 ELI5 데이터셋을 사용해 Abstractive QA, 즉 long free-form answers를 생성하는 모델의 능력을 테스트한다. BART가 기존의 연구를 outperform했다.
- Translation

Sennrich et al. (2016)의 back-translation data로 augment된 WMT16 Romanian-English 데이터셋으로 translation을 평가한다. 설명은 생략한다.
Strengths
- 임의의 transformation을 통해 corrupt된 document를 original document로 복구하는 pre-training 방식을 통해 discriminative tasks는 기존 연구(RoBERTa)와 성능이 비슷하지만 generation tasks에선 SOTA를 달성했다.
- decoder만 사용하는 기존의 방식들과 달리 BART의 encoder와 decoder을 하나의 decoder로 생각하고 새로운 encoder을 추가해 machine translation하는 방식이 참신했다. 성능도 경쟁적이었다.
