오늘 리뷰할 논문은 StyleGAN2다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 Summary] StyleGAN2 (2020 CVPR) "Analyzing and Improving the Image Quality of StyleGAN"
- [Paper Review] StyleGAN2 : Analyzing and Improving the Image Quality of StyleGAN 논문 분석
- StyleGAN2(Analyzing and Improving the Image Quality of StyleGAN)
Summary
논문은 StyleGAN의 architecture와 training method를 바꿔 characteristic artifacts를 다룬다. 특히 generator normalization를 다시 디자인하고, progressive growing을 점검하고, latent code에서 image로 mapping이 좋은 conditioning을 가지도록 격려한다. 이 path length regularizer는 image quality를 향상시킬 뿐 아니라 generator가 invert하기 쉽다는 장점도 있다. 또 generator가 얼마나 잘 output resolution을 활용하는지 visualize해서 capacity problem을 확인한다. StyleGAN2는 existing distribution quality metrics와 perceived image quality의 측면에서 SOTA를 달성한다.
(지난 포스트에서 StyleGAN을 리뷰했으므로 설명은 생략하겠다)

많은 사람들이 StyleGAN에서 characteristic artifact를 발견했다. 첫째로 논문은 common blob-like artifacts의 기원을 조사해 architecture의 design flaw를 피하기 위해 이를 생성한다는 것을 알아냈다. 논문은 generator의 normalization을 redesign하여 artifact를 제거한다. 둘째로 progressive growing과 관련된 artifact를 분석한다. training 중 network topology를 바꾸지 않고 같은 목표(low-resolution 학습에서 시작해서 high-resolution으로 점진적으로 이동하며 high-resolution GAN training을 안정화하는 것)를 가진 alternative design을 제안한다. 이 디자인은 생성된 이미지의 효과적인 resolution이 기대보다 작다는 것을 보여주며, capacity 증가의 동기를 부여한다.
image quality의 양적 평가를 위해선 Frechet inception distance (FID)와 Precision and Recall (P&R)을 사용한다. 그러나 FID와 P&R은 모두 shape보다는 texture에 집중하는 classifier에 기반하기 때문에 image quality의 모든 측면을 정확하게 포착하지 못한다. 논문은 본래 latent space interpolation의 quality를 추정하기 위한 metric이었던 perceptual path length (PPL) metric이 shape의 consistency와 stability와 상관관계가 있다는 것을 관찰했다. 이를 바탕으로 synthesis network(=generator)가 smooth mapping을 좋아하도록 regularize하여 quality 향상을 이룬다. 이로 인한 연산비용에 대응하기 위해 모든 regularization을 덜 자주 실행한다.
마지막으로 논문은 image를 latent space W로의 projection이 StyleGAN보다 pathlength regularized StyleGAN2에서 상당히 더 잘 작동함을 알았다. 이는 generated image를 source로 attribute하는 것을 쉽게 한다.
Fig 1에서 볼 수 있듯 StyleGAN은 generator의 intermediate feature map에 물방울 모양 artifact가 생긴다. 논문은 이것이 generator가 AdaIN을 통해 signal strength information를 의도적으로 sneaking하는 것이라고 가설을 세웠다. 즉, statistics를 dominate하는 strong, localized spike를 생성하는 것으로 generator은 효과적으로 signal을 scale할 수 있다. 이 가설은 이후 normalization을 바꿨을 때 droplet artifact가 사라지는 것으로 증명되었다.
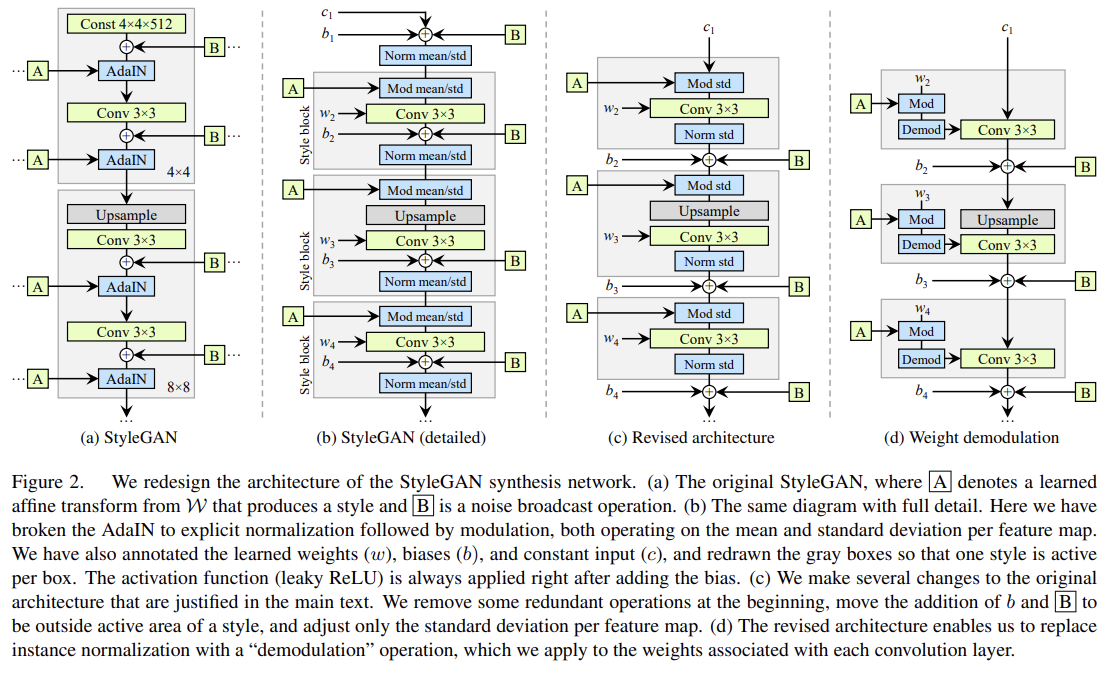
original StyleGAN은 bias와 noise를 style block 내에 적용하여 그들의 상대적 효과가 current style’s magnitudes에 inversely proportional하도록 한다. 논문은 이들을 style block 바깥에 놓아 normalized data에 작동하는 게 더 predictable results를 만듬을 관찰했다. 또 이 변화는 (mean 필요 없이) standard deviation 하나만으로도 normalization과 modulation을 가능하게 했다. constant input에 대한 (input 직후) bias, noise, normalization도 안전하게 제거될 수 있었다.
StyleGAN의 장점 중 하나는 다른 layer에 다른 latent w를 먹여서 style mixing을 하는 것이다. 실제로는 style modulation은 특정 feature map을 order of magnitude로(자릿수가 변하게) 증폭시킬 수 있다. 따라서 style mixing이 잘 작동하려면 per-sample basis로 amplification을 대응해야한다.
논문은 artifact를 제거하면서 여전히 scale-specific control이 가능한 대안을 제시한다. 핵심 아이디어는 explicit forcing이 아니라 incoming feature maps의 expected statistics에 normalization을 하는 것이다.
convolution 직전에 나타나는 modulation은 convolution의 각 input feature map을 incoming style을 바탕으로 scale한다. 이는 convolution weight를 scaling하는 식으로 구현된다.
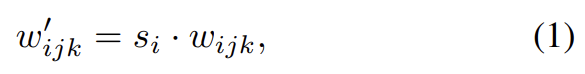
instance normalization의 용도는 convolution’s output feature maps의 statistcs에서부터 s의 효과를 없애는 것이다. 논문은 이 목표가 직접 달성될 수 있다고 봤다. input activations이 unit standard deviation을 가진 i.i.d. random variables라고 가정하자. modulation과 convolution 이후 activation의 standard deviation은 다음과 같다.
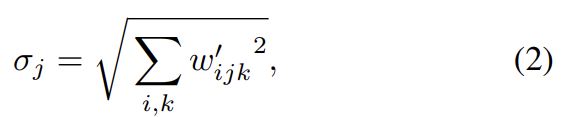
즉 상응하는 weights의 L2 norm으로 scale된 것이다. 뒤이은 normalization은 이를 다시 unit standard deviation으로 복구시키려 한다. 이는 각 output feature map j를 로 scale하여 'demodulate'을 함으로써 이루어진다.
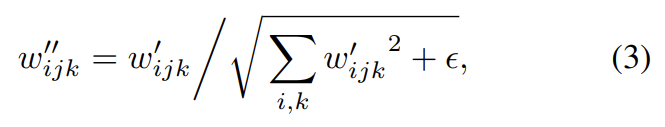
은 분모가 0이 되는 걸 막기 위한 작은 값이다.
이제 entire style block를 weight가 식 (1), 식 (3)과 s을 통해 조절된 single convolution layer로 변환됐다. instance normalization에 비하면 이 demodulation technique은 약한데, feature maps의 actual content 대신 signal에 대한 statistical assumptions에 기반하기 때문이다.

이 디자인은 characteristic artifacts을 제거하면서도 full controllability를 유지한다. FID는 거의 변화가 없지만 P&R에는 향상이 있었다.

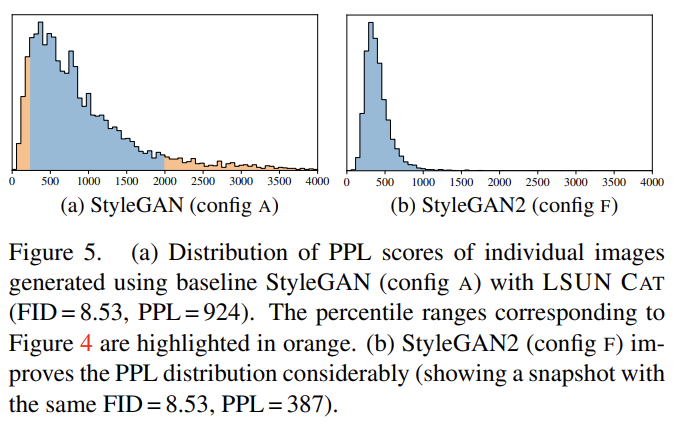
(perceptual path length (PPL) 설명 생략. distance이기 때문에 낮을수록 좋다.)
그러나 단순히 minimal PPL를 격려할 수는 없는데, 이는 generator을 zero recall와 함께 degenerate solution로 인도할 것이기 때문이다. 대신 논문은 smoother generator mapping에 집중하는 새로운 regularizer을 소개한다. 이 regularization term은 연산이 비싸기 때문에 먼저 모든 regularization 기술에 적용 가능한 general optimization인 lazy regularization을 설명한다.
일반적으로 main loss function(예컨대 logistic loss)과 regularization term(예컨대 R1)은 동시에 optimize된다. 그러나 논문은 regularization terms을 main loss function보다 덜 자주 계산해서 연산량과 메모리 사용량을 줄일 수 있음을 관찰했다.
이제 우리는 fixed-size step in W가 image에 non-zero, fixed-magnitude change를 만들도록 격려하고 싶다. 다시말해 image space에서 random direction으로 상응하는 w gradients를 관찰했을 때 이 graidnet들이 image-space direction에 무관하게 동일한 길이를 가져야 한다는 소리다. single w ∈ W에서 generator mapping g(w) : W → Y의 local metric scaling properties은 Jacobian matrix 로 포착된다. 방향에 관계없이 expected length를 유지하기 위해 다음과 같이 regularizer을 설정한다.
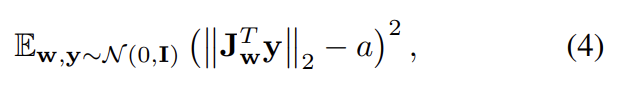
y는 normally distributed pixel intensitie를 가진 random images, z는 normally distributed, w ∼ f(z)다. Jacobian matrix의 explicit computation을 피하기 위해 standard backpropagation으로 효율적으로 계산 가능한 identity 를 사용한다. constant a는 optimization 도중 length 의 long-running exponential moving average으로 설정되어 optimization 스스로 적절한 global scale을 찾도록 한다.
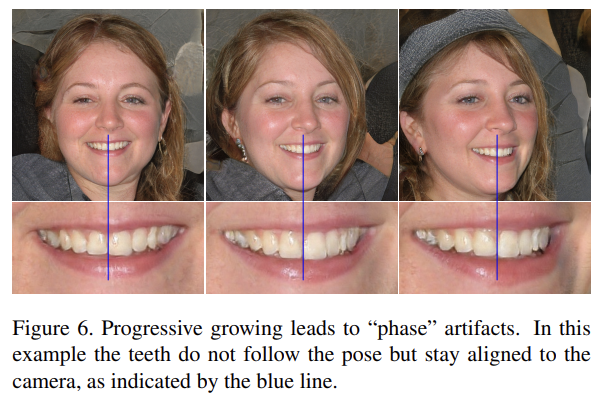
progressive growing은 high-resolution image synthesis의 안정화에 좋지만 characteristic artifact를 만든다. 핵심 issue는 progressively grown generator가 detail에 대한 강한 location preference를 가진다는 것이다. 논문은 progressive growing에서 각 resolution이 output resolution에 잠시동안만(momentarily) 작동해서 maximal frequency detail를 생성하도록 강요한다고 생각했다. 이는 trained network가 intermediate layers에서 excessively high frequencies를 가지게 해 shift invariance를 compromise한다.
(즉 저해상도에서 maximum frequency detail을 만들어 위치 고정이 일어나고 다음 해상도에서 이를 기반으로 이미지를 생성할 때 참조했기 때문에 artifact가 생긴다는 의미)
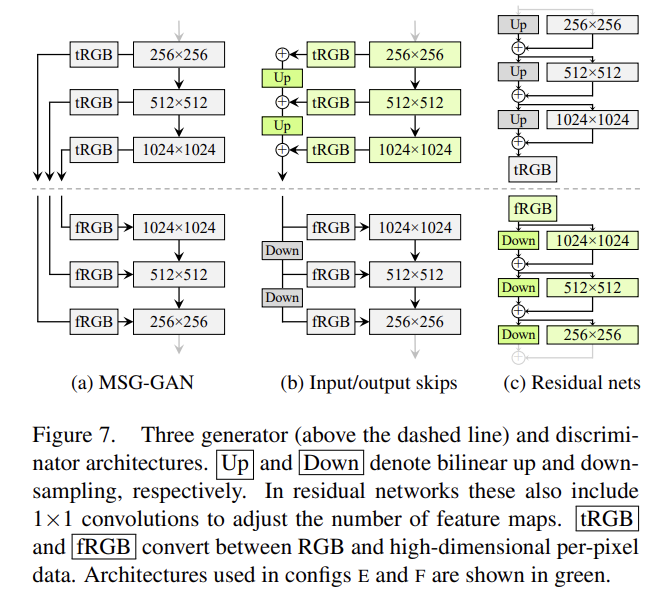
따라서 논문은 progressive growing 없이 high-quality images를 생성하는 alternative architecture을 탐색했다. MSG-GAN은 여러 skip connections으로 generator와 discriminator의 matching resolutions를 연결한다. MSG-GAN generator은 image 대신 mipmap을 output하도록 수정되었다. Fig 7b에서 여러 resolution에 대응하는 RGB ouputs의 contribution을 더하고 upsampling하여 디자인을 간략화했고 discriminator의 각 블록에 downsample했다. 모든 up, downsampling operations에 bilinear filtering을 적용했다. Fig 7c에선 residual connection을 사용하도록 디자인을 수정했다.
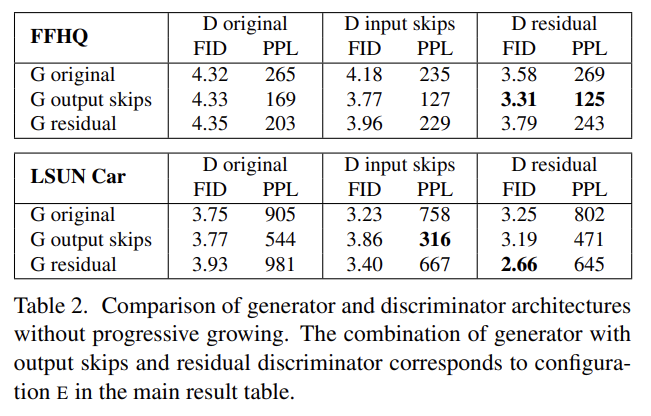
Tab 2에서 세 디자인을 비교했다. generator에 skip connection은 모든 설정에서 PPL을 향상시킨다. residual discriminator network는 FID에 유용하다. 그러나 residual architecture은 generator에 해로웠다. 논문의 이후 실험에선 skip generator와 residual discriminator을 progressive growing 없이 사용한다.
progressive growing의 핵심은 generator가 처음에는 low-resolution features에 집중하다가 점점 관심을 finer-detail로 이동하는 것이다. Fig 7의 architecture은 이를 가능하게 한다. 그러나 강요된 것이 아니기 때문에 generator은 이가 유용할 때만 그렇게 할 것이다. 이 행동을 분석하려면 generator가 training에서 특정 resolution에 얼마나 의존하는지 quantify해야한다.
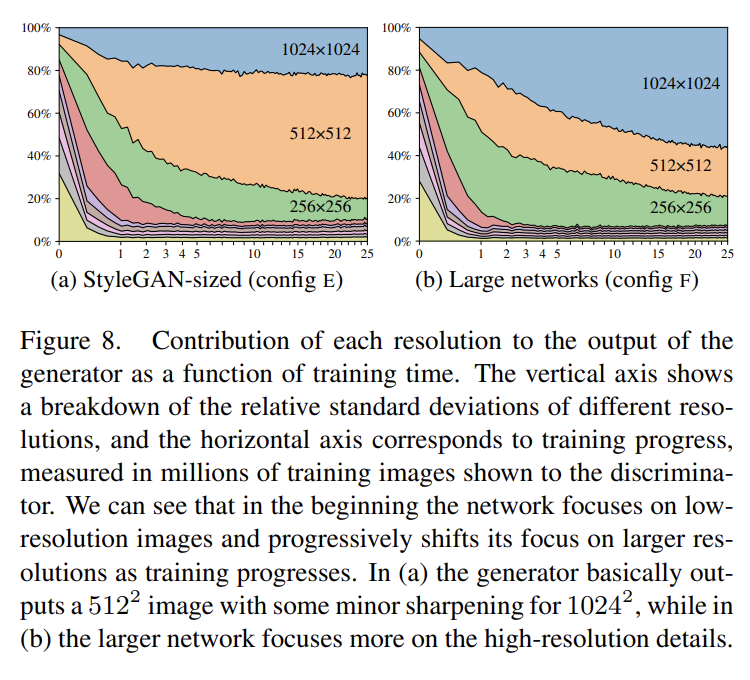
skip generator가 여러 resolution에서 RGB values를 합치는 것으로 이미지를 형성하기 때문에 final image에 얼마나 기여하는지를 측정해 상응하는 layers의 상대적 중요도를 추정할 수 있다. Fig 8a는 각 tRGB layer에 의해 생성된 pixel values의 standard deviation을 그린 것이다.
training 초기에 new skip generator가 progressive growing과 비슷하게 동작함을 볼 수 있다. 그러니 training 후반으로 갈수록 highest resolution이 dominate할 것을 기대할 수 있는데, 실제로는 target resolution을 fully utilize하지 못했다. 생성된 이미지를 manually 조사한 결과 training data에 존재하는 pixel-level detail이 부족함을 깨달았다. 진정한 1024x1024 image가 아니라 512x512의 sharpened version처럼 보였다는 것이다.
이는 network에 capacity problem이 있는 게 아닌가하는 의혹을 일으켰고 두 네트워크(G, D)의 highest-resolution layers에 있는 feature maps를 2배로 키워 실험했다. 그 결과 Fig 8b는 기대와 더 부합하여 highest-resolution layers의 기여도가 상당히 올랐다.
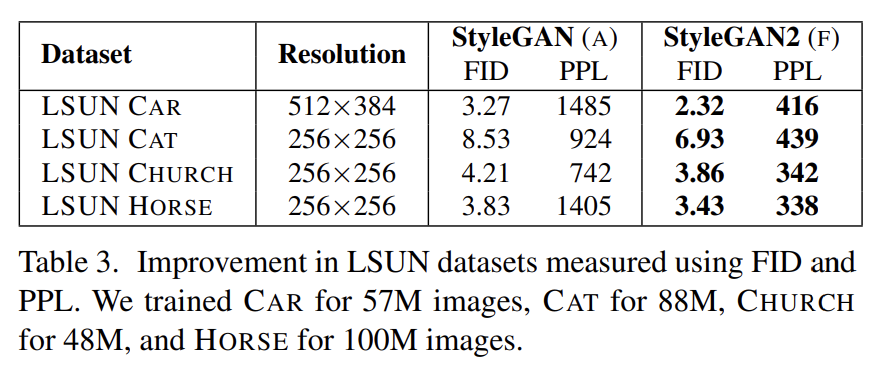
synthesis network g를 invert하는 것은 여러 응용이 가능한 흥미로운 문제다. latent feature space에서 주어진 image를 조작하려면 먼저 matching latent code w를 찾아야 한다. 논문은 (기존의 방식과 달리) original, unextended latent space에서 latent code를 찾는데 집중했다.
논문의 projection method는 기존의 방법과 2가지에서 다르다. 첫째로 latent space를 더 철저히 탐구하기 위해 optimization 중 ramped-down noise를 latent code에 더한다. 둘째로 StyleGAN generator의 stochastic noise inputs도 optimize하여 그들이 coherent signal을 carry하지 않도록 regularize한다. regularization은 여러 scales에서(over) noise maps의 autocorrelation coefficients가 unit Gaussian noise와 match하도록 강제한다.

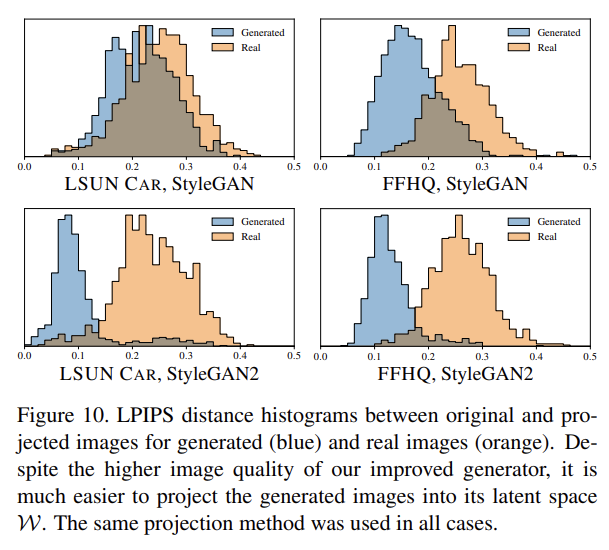
original/resynthesized image 사이 LPIPS distance를 계산해 projection이 성공한 정도를 측정한다. StyleGAN2는 W에 잘 project되서 generating network에 거의 unambiguously attribute되었다. 그러나 original StyleGAN은 W에서 image로의 mapping이 너무 복잡해서 실제로는 성공하기 힘들었다. StyleGAN2는 image quality가 상당히 향상되었으메도 source attribution을 쉽게 만듬을 알 수 있었다.
Strengths
- 기존 StyleGAN의 artifact와 발생 원인을 잘 규명하고 해결해 성능 향상을 이루었다.
- progressive growing을 사용하지 않고도 같은 이점을 획득했다.
Weaknesses
- path length regularization의 연산량이 많아 lazy regularization을 사용해야할 정도였다.
