오늘 리뷰할 논문은 multimodal survey 논문이다. multimodal approach에서 유명한 4가지 방식을 소개하는 듯하다.
Self supervised unimodal label prediction and Multi-task for better representation 부분은 뭔 소린지 이해를 못했다.
아래 포스트를 먼저 보면 도움이 될 것이다.
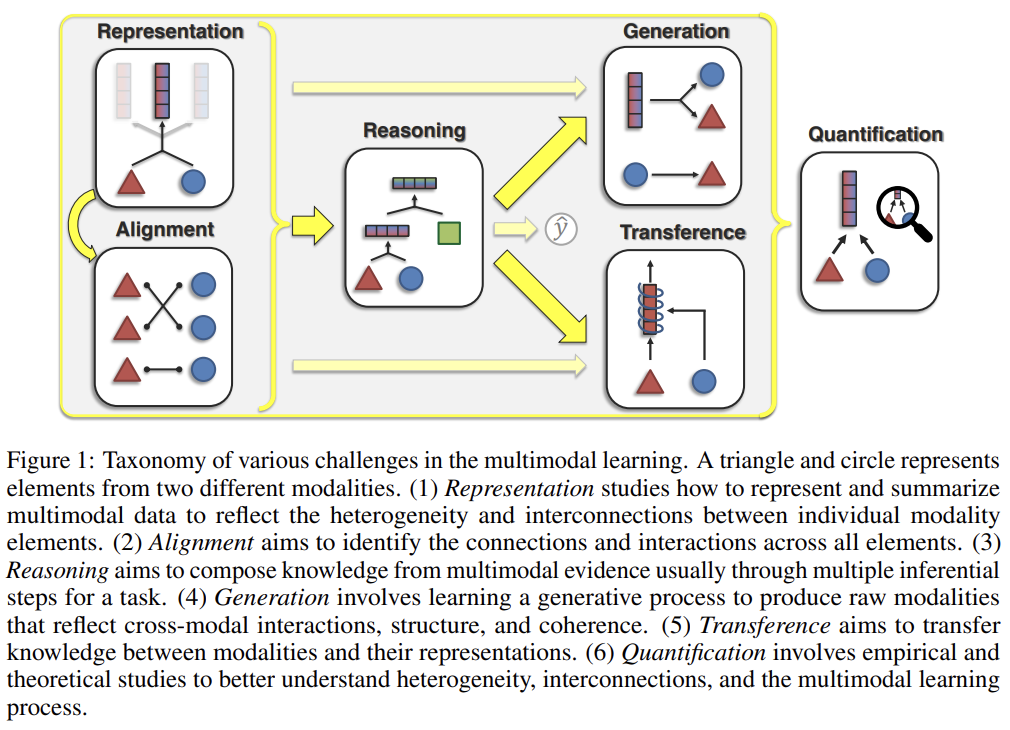
self-supervised learning의 일반적인 기술은 input의 observed/unhidden part를 보고 input의 unobserved/hidden part를 예측하는 것이다. (NLP에서 문장 일부를 가리고 그 단어를 맞추는 것처럼)
논문은 4가지 best self supervised learning approaches를 소개한다.
- 주어진 image-text pair에 대해 image-to-text와 text-to-image를 생성하는 cross modal generation. 그리고 generated text와 image samples를 input pair와 비교한다.
- masked language modelling에서 masked token을 예측하기 위해 audio와 video modality에서 오는 신호를 사용하는 cross modal transformer.
- Seq2Seq를 이용한 cyclic translation between modalities. 주어진 modality가 다른 modality로 translate된 후 다시 원래대로 translate된다. learned hidden encoding이 final prediction에 사용된다.
- self supervised fashion으로 multimodal datasets에서 unimodal labels을 생성하는 approach. multimodal과
unimodal labels 모두에 공동으로 학습하기 위해 Multitask learning이 사용된다.
- Cross-modal generation
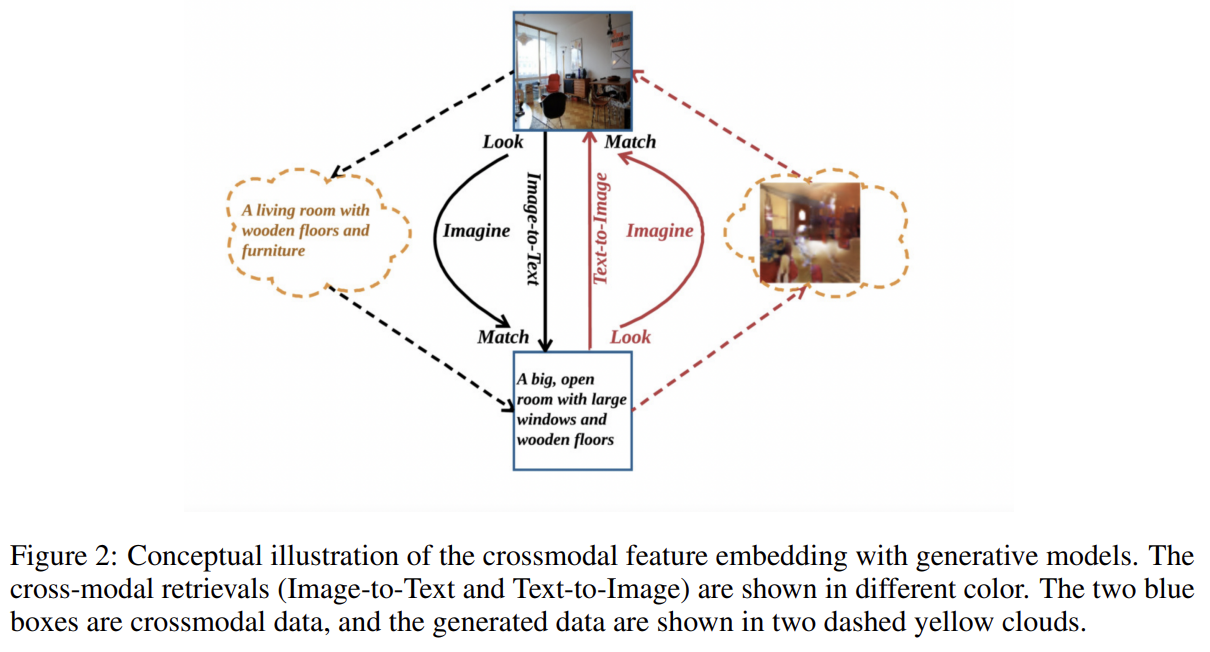
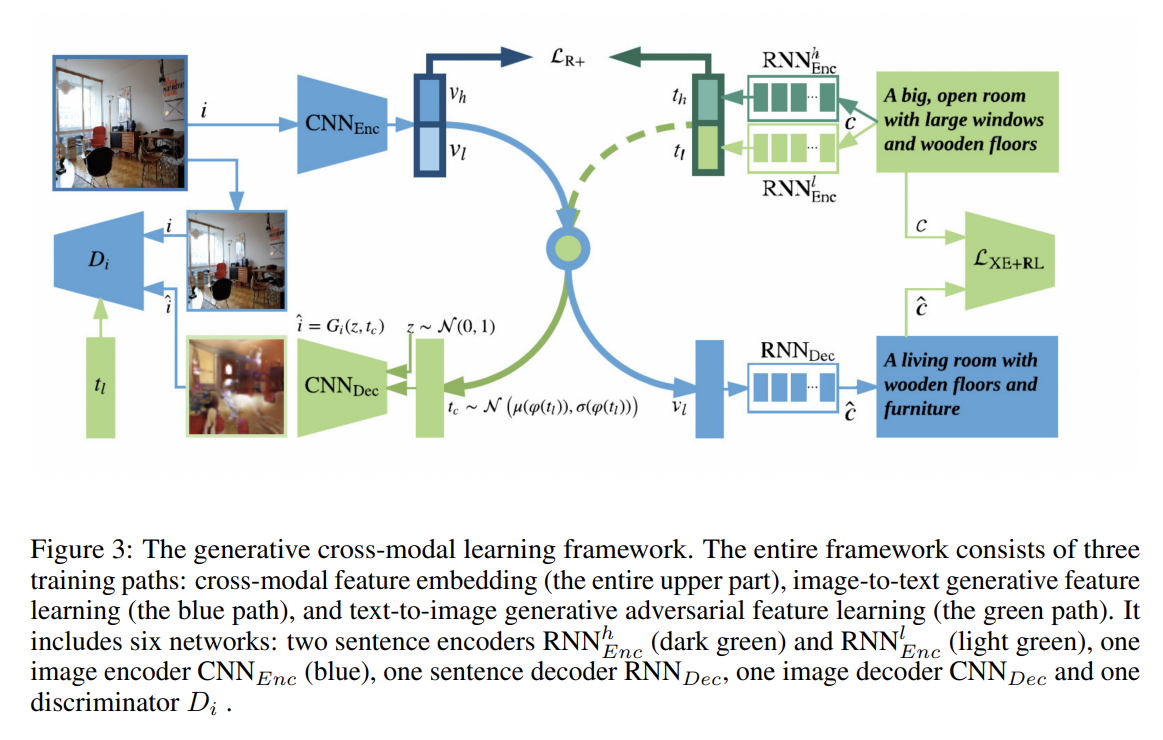
주요 아이디어는 Gu et al. [2018]이 제안했으며 global semantic level에서 conventional cross-modal feature embedding에 추가로 두 generative models, image-to-text와 text-to-image,에 기반한 additional cross-modal feature embedding at the local level를 도입하는 것이다. look, imagine, match의 세 단계를 가진다.
- Cross-modal pretraining for transformers
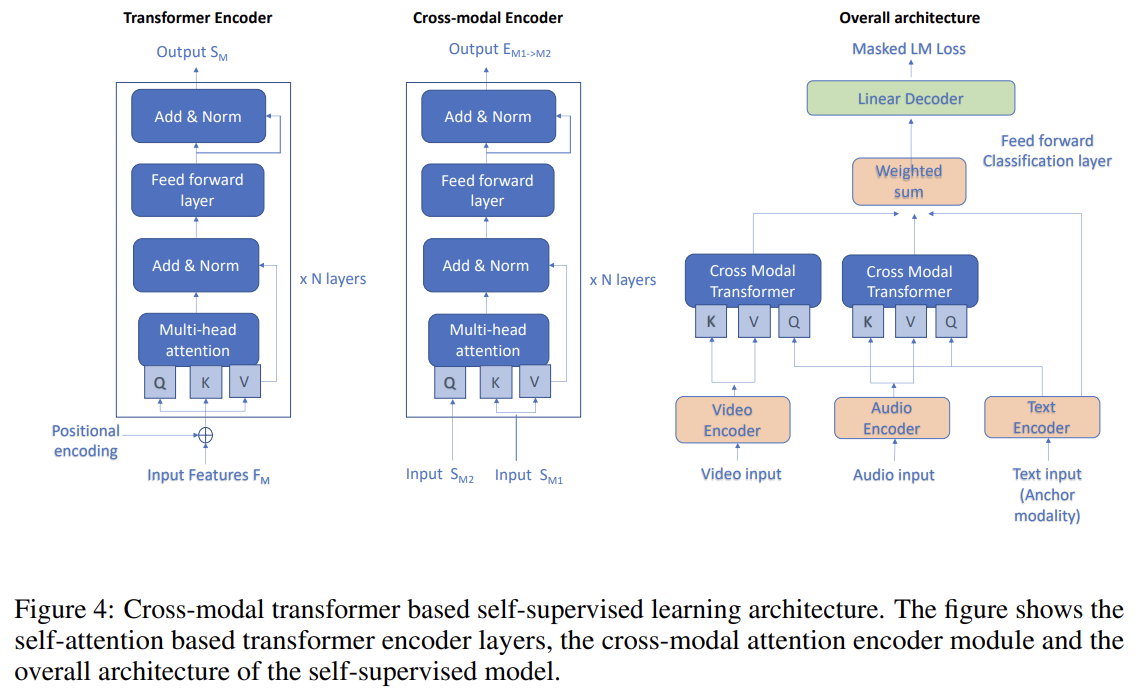
주요 아이디어는 Khare et al. [2021]가 제안했으며 self supervised fashion으로 cross-modal transformer을 pretrain하고 emotion recognition을 위한 transformer을 finetune했다.
개별 modalities에 대해 self-attention based transformer encoder를 사용하고 각각의 uni-modal transformer encoder outputs을 cross-modal transformer로 조합해 emotion recognition을 위한 multi-modal representation을 배운다.
- Self supervised cyclic translation
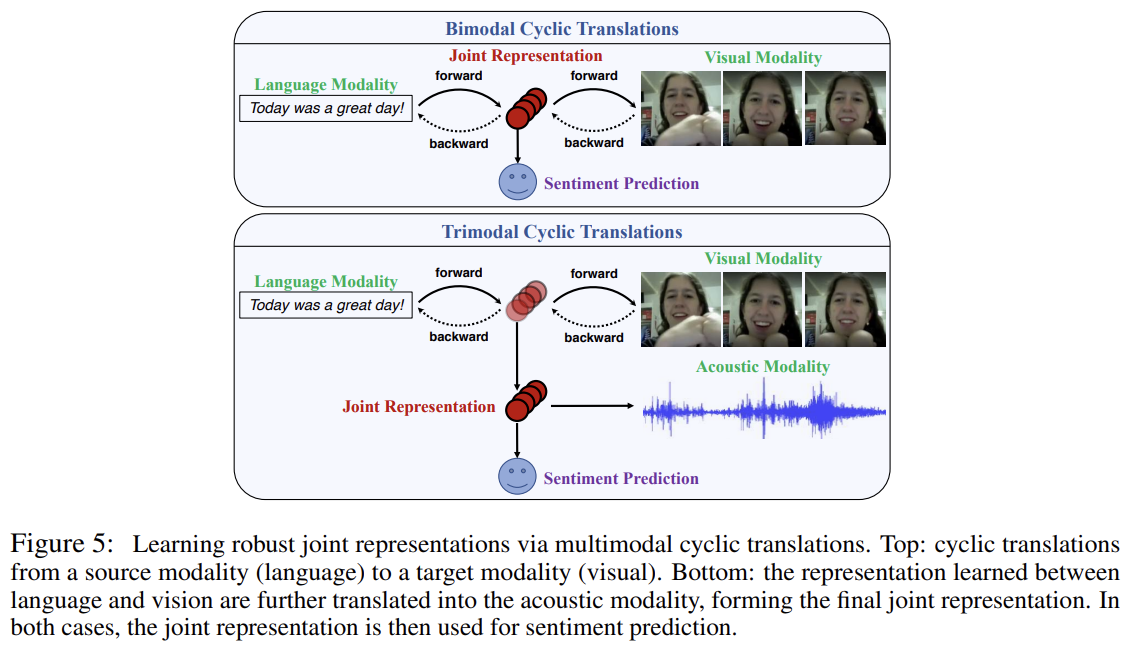
Pham et al. [2019]은 modalities 간 translating을 통해 robust joint representations을 학습하는 방법을 제안한다. 이 방법은 source에서 target modality로의 변환이 오직 source modality만을 input으로 사용하고도 joint representations를 배울 수 있다는 통찰에 기반한다. joint representation이 모든 modality로부터 최대 정보를 가지게 하기 위해 cycle consistency loss를 사용한다. test time에는 source modality 데이터만 있으면 된다.
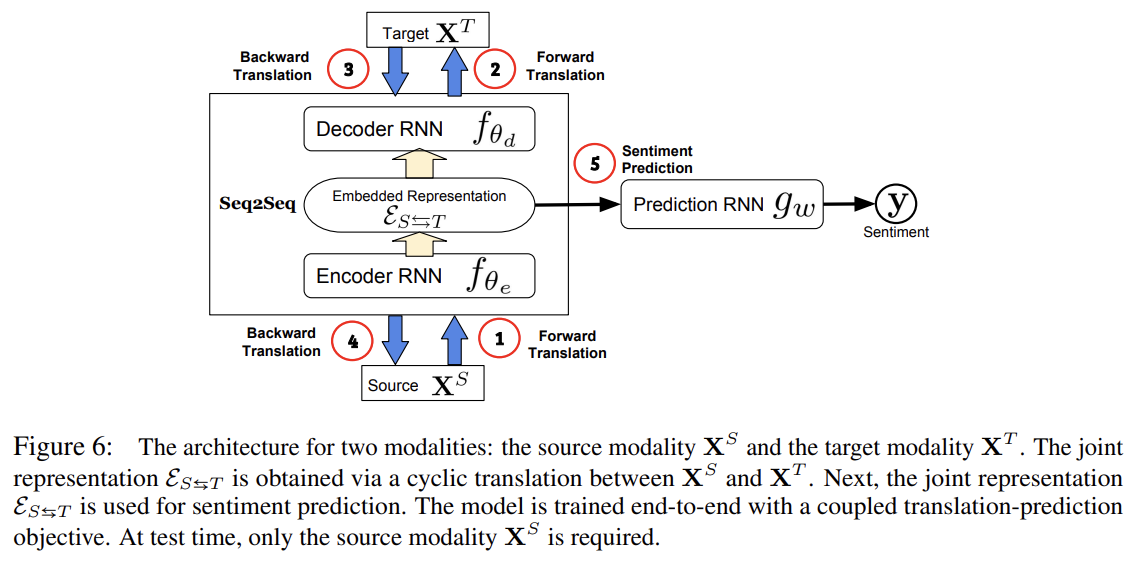
source modality에서 target modality로 translation하는 중 intermediate representation가 두 modalities 간 joint information을 포착한다는 통찰에 기반한다. 원본 논문은 source modality와 multiple target modalities 간 joint representation을 배우기 위해 hierarchical setting을 제안하기도 한다.
- Self supervised unimodal label prediction and Multi-task for better representation
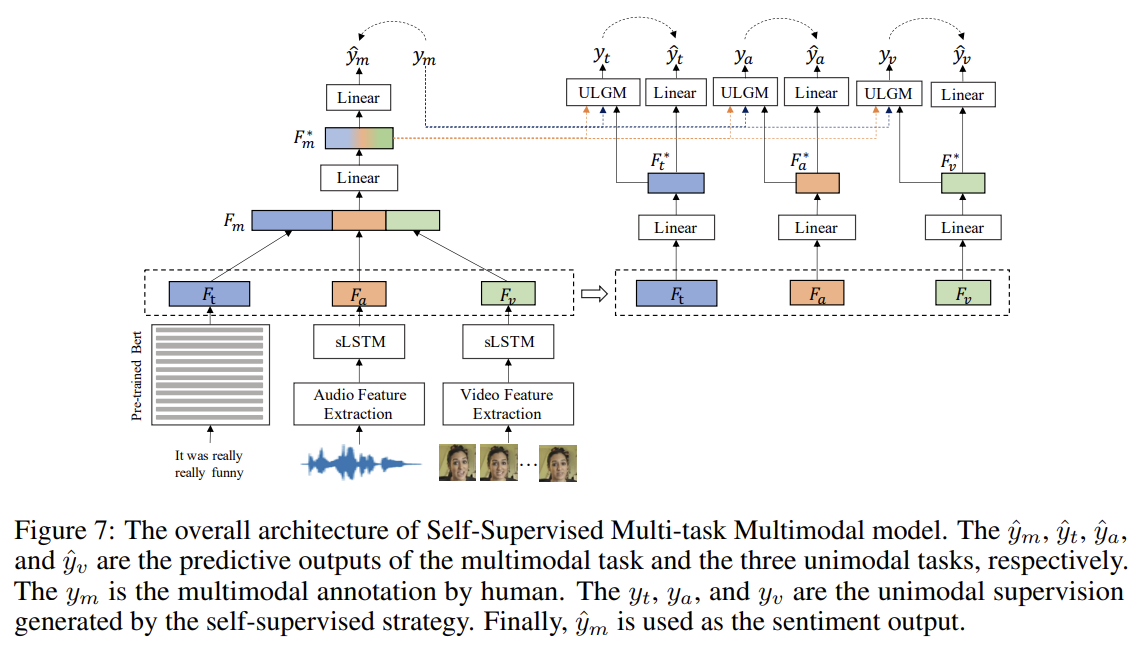
Unimodal Label Generation Module (ULGM)은 multimodal annotations과 modality representations에 기반해 uni-modal supervision values를 생성한다.