과대적합과 과소적합
https://www.tensorflow.org/tutorials/keras/overfit_and_underfit
- 과대적합
- 일정 epoch 동안 validation set이 최고점을 찍고 감소하는 경향
- 과소적합
- test set의 성능이 향상될 여지가 있을 때 발생
- 원인
- 모델이 너무 단순
- 규제가 너무 많을 때
- 충분히 오래 훈련하지 않은 경우
- 과대적합 및 과소적합 방지
- 적절한 epoch로 훈련
- 과대적합 방지에는 더 많은 train data 추가하는 게 best(일반화 성능 향상)
- 차선책으로는 regulization 기법을 추천 → 가중치 규제, dropout등
👉 regulization
모델이 저장할 수 있는 정보의 양과 종류에 제약을 부과하는 방법.
네트워크가 적은 패턴만 기억 할 수 있으면 최적화 과정 동안 일반화 가능성이 가장 중요한 패턴에 초점을 맞추기 때문
과대적합 예제
- 가중치 규제
- 모델의 규모 축소(= parameter 축소)
- 많은 parameter = 많은 기억 용량(mapping)
- 딥러닝 모델이 train set에서는 학습이 잘되지만, 문제는 일반화
- 적은 parameter → 손실을 최소화 하기 위해 더 많은 압축된 표현 학습이 필요
- 가이드: 알맞은 모델의 크기를 찾으려면 비교적 적은 수의 층과 파라미터로 시작해서 검증 손실이 감소할 때까지 새로운 층을 추가하거나 층의 크기를 늘리는 것이 좋습니다.
기준 모델 만들기
baseline_model = keras.Sequential([
# `.summary` 메서드 때문에 `input_shape`가 필요합니다
keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(16, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
baseline_model.summary()
baseline_history = baseline_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512, # batch_size : 몇 개의 샘플로 가중치를 갱신할 것인지 지정
validation_data=(test_data, test_labels),
verbose=2)작은 모델 만들기
smaller_model = keras.Sequential([
keras.layers.Dense(4, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(4, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
smaller_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
smaller_model.summary()
smaller_history = smaller_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)큰 모델 만들기
bigger_model = keras.models.Sequential([
keras.layers.Dense(512, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(512, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
bigger_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
bigger_model.summary()
bigger_history = bigger_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)훈련 손실과 검증 손실 그래프 그리기
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
plot_history([('baseline', baseline_history),
('smaller', smaller_history),
('bigger', bigger_history)])
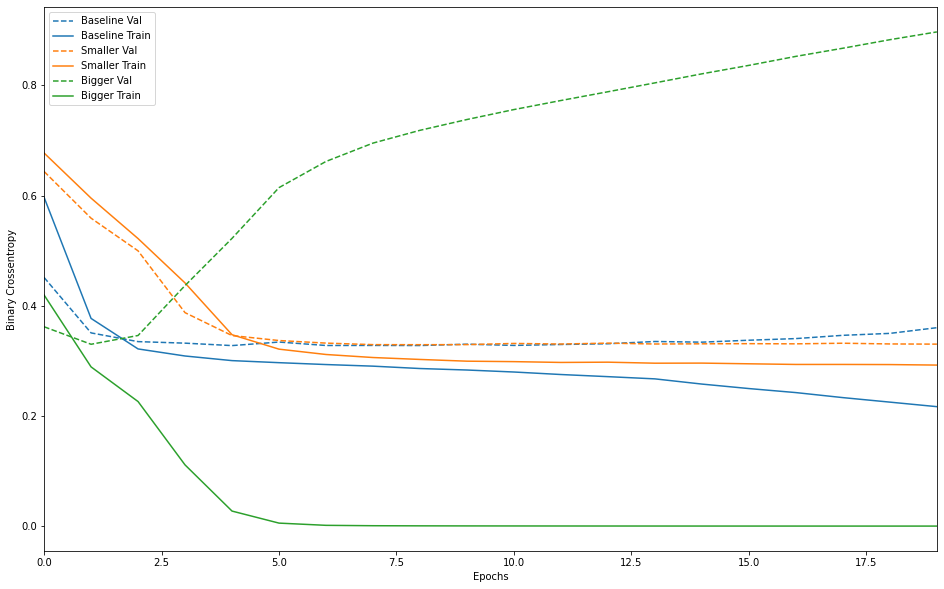
- 실선은 train loss, 점선은 validation loss
- validation loss가 낮다면 더 좋은 모델
- 작은모델이 기준모델보다 더 늦게 overfitting 시작, 성능도 비교적 천천히 감소
- 큰 모델은 첫 번째 epoch이후 overfitting 시작되고, 전체적으로 크게 overfitting
- 큰 모델이 더 빠르데 모델링 진행(=train loss 감소)
- 그러나 더 쉽게 overfitting(=train loss와 validation loss 사이에 큰 차이 발생)
과대적합을 방지하기 위한 전략
가중치를 규제하기(weight regularization)
🪒 오캄의 면도날 이론(Occam's Razor)
어떤 것을 설명하는 두 가지 방법이 있다면 더 정확한 설명은 최소한의 가정이 필요한 가장 "간단한" 설명일 것이다.
→ 간단한 모델이 더 잘 설명 할 수 있다(=일반화, overfitting 경향이 작을 것)
- 간단한 모델?
- 모델의 parameter 분포의 entropy가 작은 모델
- 적은 parameter를 가진 모델
- 가중치 규제
- 네트워크 복잡도에 제약(적은 가중치를 가지도록)
- 네트워크의 손실 함수에 큰 가중치에 해당하는 비용(cost)을 추가
- 비용함수
- L1 regulatization은 가중치의 절댓값에 비례하는 비용이 추가 (즉, 가중치의 "L1 노름(norm)"을 추가).
- L2 regularization은 가중치의 제곱에 비례하는 비용이 추가(즉, 가중치의 "L2 노름"의 제곱을 추가)
- L1 규제는 일부 가중치 파라미터를 0으로 만든다.
- L2 규제는 가중치 파라미터를 제한하지만 완전히 0으로 만들지는 않는다. L2 규제를 더 많이 사용하는 이유 중 하나.
l2_model = keras.models.Sequential([
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
l2_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
l2_model_history = l2_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)- l2(0.001)는 네트워크의 전체 손실에 층에 있는 가중치 행렬의 모든 값이 0.001 * weight_coefficient_value2**만큼 더해진다는 의미입니다. 이런 페널티(penalty)는 훈련할 때만 추가
- 따라서 테스트 단계보다 훈련 단계에서 네트워크 손실이 훨씬 더 크게 만든다.
.png)
결과에서 보듯이 모델 파라미터의 개수는 같지만 L2 규제를 적용한 모델이 기본 모델보다 과대적합에 훨씬 잘 견디고 있다.
드롭아웃 추가하기(Dropout)
- 드롭아웃
- 훈련하는 동안 레이어의 출력 특성을 랜덤하게 끈다(=0으로 만든다)
- [0.2, 0.5, 1.3, 0.8, 1.1] → [0, 0.5, 1.3, 0, 1.1]
- 비율은 보통 0.2에서 0.5 사이 사용
- 테스트 단계에서는 어떤 유닛도 드롭아웃하지 않지만
- 훈련 단계보다 더 많은 유닛이 활성화되기 때문에 균형을 맞추기 위해 층의 출력 값을 드롭아웃 비율만큼 줄인다.
dpt_model = keras.models.Sequential([
keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
keras.layers.Dropout(0.5),
keras.layers.Dense(16, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(1, activation='sigmoid')
])
dpt_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
dpt_model_history = dpt_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2).png)
기준 모델보다 향상된 결과를 확인할 수 있다.
Recap
정리하면 신경망에서 overfitting 방지를 위한 방법은 다음과 같다.
- 더 많은 훈련 데이터를 추가
- 네트워크의 용량을 감소
- 가중치 규제를 추가
- 드롭아웃을 추가
데이터 증식(data-augmentation)과 배치 정규화(batch normalization)는 해당 문서에서 다루지 않았음)

사람을 위한 기술을 공부합니다