정렬
Today we're going to study binary search. 내 가능성이 어디까지 열려있는지 잘 모르겠지만 난 개발자로서 커리어를 마감하고 싶지 않다. 일단 개발자를 달고 PM으로 전직해 사람들을 이끌어 나가고 싶다. 다양한 사람들과 함께 일하고 싶다. 그래도 일단 당장 할 것은 이진 탐색을 정리하는 것이다!
05-3 이진 탐색
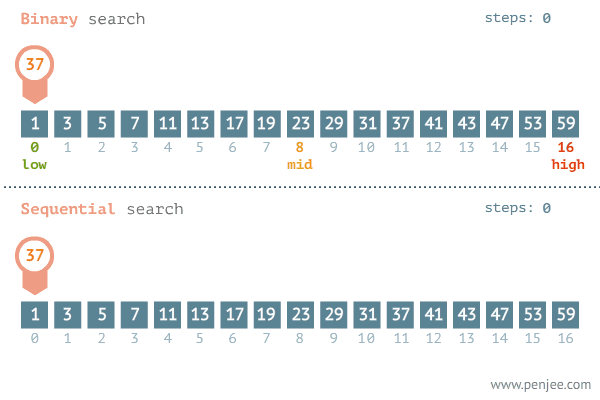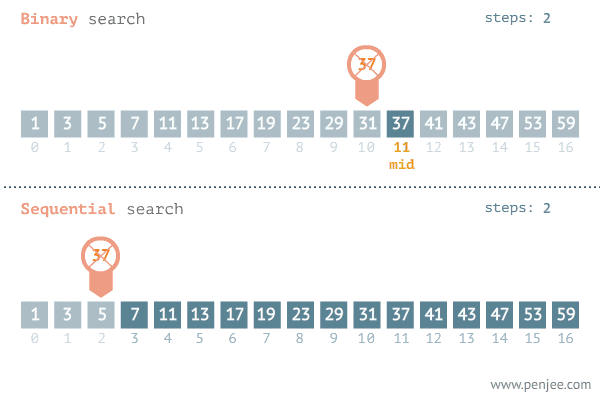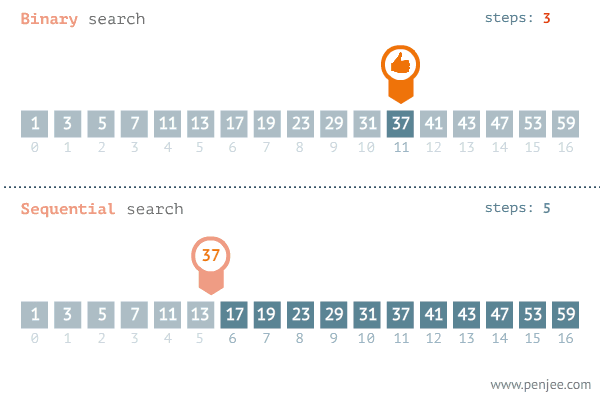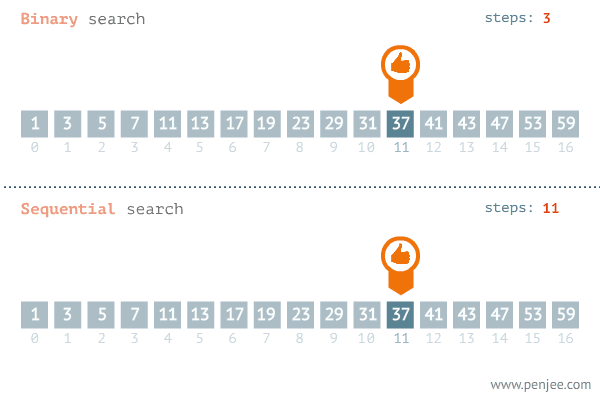
이진 탐색(binary search)은 데이터가 정렬돼 있는 상태에서 원하는 값을 찾아내는 알고리즘이다. 대상 데이터의 중앙값과 찾고자 하는 값을 비교해 데이터의 크기를 절반씩 줄이면서 대상을 찾는다.
| 기능 | 특징 | 시간 복잡도 |
|---|---|---|
| 타깃 데이터 탐색 | 중앙값 비교를 통한 대상 축소 방식 | O(logN) |
이진 탐색은 정렬 데이터에서 원하는 데이터를 탐색할 때 사용하는 가장 일반적인 알고리즘이다. 구현 및 원리가 비교적 간단하므로 많은 코딩 테스트에서 부분 문제로 요구하는 영역이다.
이진 탐색의 핵심 이론
이진 탐색은 오름차순으로 정렬된 데이터에서 다음 4가지 과정을 반복한다.
이진 탐색 과정
-
현재 데이터셋의 중앙값(median)을 선택한다.
-
중앙값 > 타깃 데이터일 때 중앙값 기준으로 왼쪽 데이터셋을 선택한다.
-
중앙값 < 타깃 데이터일 때 중앙값 기준으로 오른쪽 데이터셋을 선택한다.
-
과정 1. ~ 3.을 반복하다가 중앙값 == 타깃데이터일 때 탐색을 종료한다.
문제 029 원하는 정수 찾기
문제
N개의 정수 A[1], A[2], …, A[N]이 주어져 있을 때, 이 안에 X라는 정수가 존재하는지 알아내는 프로그램을 작성하시오.
입력
첫째 줄에 자연수 N(1 ≤ N ≤ 100,000)이 주어진다. 다음 줄에는 N개의 정수 A[1], A[2], …, A[N]이 주어진다. 다음 줄에는 M(1 ≤ M ≤ 100,000)이 주어진다. 다음 줄에는 M개의 수들이 주어지는데, 이 수들이 A안에 존재하는지 알아내면 된다. 모든 정수의 범위는 -231 보다 크거나 같고 231보다 작다.
출력
M개의 줄에 답을 출력한다. 존재하면 1을, 존재하지 않으면 0을 출력한다.
예제 입력 1
5
4 1 5 2 3
5
1 3 7 9 5
예제 출력 1
1
1
0
0
1
N의 최대 범위가 100,000이므로 단순 반복문으로는 이 문제를 풀 수 없다. 이진 탐색을 적용하면 데이터 정렬까지 고려하여 O(nlogn) 시간 복잡도로 해결할 수 있으므로 이진 탐색을 적용한다.
import sys
sys.stdin = open("input.txt", 'rt')
n = int(input())
a = list(map(int, input().split()))
a.sort()
m = int(input())
target_list = list(map(int, input().split()))
for i in range(m):
find = False
target = target_list[i]
s = 0
e = len(a)-1
while s <= e:
midi = (s+e) // 2
midv = a[midi]
if midv > target:
e = midi - 1
elif midv < target:
s = midi + 1
else:
find = True
break
if find:
print(1)
else:
print(0)