
이펙티브 코틀린(Effective Kotlin Best Practices) 책을 통해 스터디 진행하면서 정리한 글입니다.
1. 가변성을 제한하라
Kotlin에서는 var, val 키워드를 통해 기본적으로 가변성을 제한하고 있습니다. 하지만 val 키워드를 사용하더라도 변수가 가리키는 참조 객체가 변하지 않을 뿐 객체 내부의 값은 변할 수 있습니다.
class BankAccount {
var balance = 0.0
private set
fun deposit(depositAmount: Double){
balance += depositAmount
}
@Throws(InsufficientFunds::class)
fun withdraw(withdrawAmount: Double){
if (balance < withdrawAmount) {
throw InsufficientFunds()
}
balance -= withdrawAmount
}
}
class InsufficientFunds : Exception()
fun main(){
val account = BankAccount()
println(account.balance) // 0.0
account.deposit(100.0)
println(account.balance) // 100.0
account.withdraw(50.0)
println(account.balance) // 50.0
}다음 코드를 보시면 손쉽게 이해하실 수 있으실 겁니다. BankAccount라는 클래스에는 balance라는 가변변수가 존재하고 deposit 메소드와 withdraw 메소드로 balance의 값을 변경시킬 수 있습니다. 저 역시 이와 같이 코드를 주로 사용하였고 특정 변수를 통해 상태 관리를 하도록 하였습니다. 하지만 BankAccount에 돈이 얼마나 있는지를 나타내는 상태가 있도록 코드를 작성하는 것은 장단점이 명확히 존재합니다.
-
다양한 곳에서 가변변수를 상태 변경을 할 수 있기에 프로그램을 이해하고 디버깅하는 것이 어려울 수 있습니다.
-
비슷한 맥락으로 가변성으로 인해 코드의 실행을 예상하기가 어려워질 수도 있습니다.
-
가변변수의 최대 약점인 멀티스레드 프로그램일 때는 동기화가 필수적으로 필요합니다.
-
또한, 상태를 관리하는 변수가 많으면 많을수록 다양한 테스트 케이스가 존재하여 테스트의 어려움도 존재합니다.
-
상태변경으로 인해 변경 전이가 필요한 부분에 대해서는 모두 알려줘야 합니다.
// Case 1 : Multi Thread
var num = 0
for(i in 1..1000){
thread {
Thread.sleep(10)
num += 1
}
}
Thread.sleep(5000)
print(num) // 1000이 아닐 확률이 높음// case 2: Multi Coroutine
suspend fun main(){
var num = 0
coroutineScope {
for(i in 1..1000) {
launch {
delay(10)
num += 1
}
}
}
}
print(num) // 실행할 때마다 다른 숫자위 예시는 멀티 스레드, 멀티 코루틴을 활용하여 가변변수의 값을 변경하고 있습니다. 본연의 목적은 num 값을 1을 증가시켜 1000을 출력하고 싶지만 동기화가 처리가 되어 있지 않아 원하는 결과를 받지 못할 가능성이 큽니다.
val lock = Any()
var num = 0
for(i in 1..1000){
thread {
Thread.sleep(10)
synchronized(lock) {
num += 1
}
}
}
Thread.sleep(1000)
print(num) // 1000다음 코드는 동기화를 처리하여 원하는 결과를 받을 수 있습니다. 이처럼 가변변수를 사용하기에는 여러 제약사항이 존재할 수 있으며 동기화를 잘 구현하는 일은 매우 어려운 일입니다. 절차형 프로그래밍에서 가변변수 사용으로 동기화 이슈가 존재하고 이러한 단점으로 인해 함수형 프로그래밍이 등장한 배경이기도 합니다.
1.1 Kotlin에서 가변성 제한하기
Kotlin에서는 가변성을 제한할 수 있게 설계되어 있고 다양한 방법이 존재하지만 대표적인 방법 위주로 정리하겠습니다.
1) 읽기 전용 프로퍼티(val)
Kotlin을 조금이라도 사용해보신 분들은 읽기 전용 프로퍼티가 일반적으로 값이 변하지 않는다는 것을 알고 있을 것입니다. 또한, 참조 객체를 가리킬 경우에는 객체 자체는 변하지는 않지만 객체 내부의 값은 변할 수 있다는 것도 알고 있을 것입니다.
var name: String = "Marcin"
var surname: String = "Moskala"
val fullName
get() = "$name $surname"
fun main(){
println(fullName) // Marcin Moskala
name = "Maja"
println(fullName) // Maja Moskala
}읽기 전용 프로퍼티는 위의 코드처럼 다른 프로퍼티를 활용한 사용자 정의 Getter를 만들 수 있습니다. 이를 Backing Property라고도 하는데 추후에 배우는 내용이라고 하니 나중에 정리하도록 하겠습니다.
궁금증
Kotlin에 Property는 Field + Getter/Setter로 정의되고 있는데 위의 코드를 자바로 디컴파일 해보면 Field는 존재하지 않고 Getter만 존재한다. 이럴 경우도 프로퍼티라고 부를 수 있을까..?
혹시 좋은 혜안을 가지고 있으신 분들은 댓글로 남겨주세요 🥺
interface Element{
val active: Boolean
}
class ActualElement: Element{
override var active: Boolean = false
}Kotlin의 프로퍼티는 클래스의 필드를 캡슐화하고 Getter와 Setter를 통해 접근합니다. var 키워드는 가변성이 있기에 Getter와 Setter 모두 제공하고 val 키워드는 불변성이기에 Getter만 제공합니다. 이러한 특성으로 인해 val을 var로 오버라이딩 할 수 있습니다. 단순 코드만 보면 이해가 안가니 Java로 디컴파일 해보면 조금 더 이해가 빠르게 됩니다.
public interface Element {
boolean getActive();
}
public final class ActualElement implements Element {
private boolean active;
public boolean getActive() {
return this.active;
}
public void setActive(boolean var1) {
this.active = var1;
}
}Element 인터페이스에 val가 존재하여서 getter만 제공이 되고 인터페이스를 구현한 ActualElement는 필드 값을 추가한 후 setter를 추가한 것을 알 수 있습니다. 이와 같은 형태로 val을 var로 오버라이딩을 할 수 있게 되는 것입니다.
val name: String? = "Marton"
val surname: String = "Braun"
val fullName: String?
get() = name?.let { "$it $surname" }
val fullName2: String? = name?.let { "$it $surname" }
fun main() {
if(fullName != null){
println(fullName.length) // 오류
}
if(fullName2 != null) {
println(fullName2.length) // Marton Braun(Smart Casting)
}
}위의 코드처럼 fullName은 Getter로 지정하고 fullName2는 직접 값을 지정하였습니다. 이것도 비슷하게 자바로 디컴파일 해보면 확연히 알 수 있지만 코드는 생략하고 설명만 하도록 하겠습니다.
게터로 지정을 하게 되면 field값은 존재하지 않고 게터 메소드만 존재합니다. 즉, 게터 메소드가 호출할 때마다 name와 surname을 확인하기 때문에 값이 달라질 수 있습니다. 하지만 값을 지정한 경우는 Field값이 존재하고 게터에 현재의 값이 지정됩니다. 이 경우에는 스마트 캐스팅까지 적용할 수 있습니다.
2) 가변 컬렉션과 읽기 전용 컬렉션 구분하기
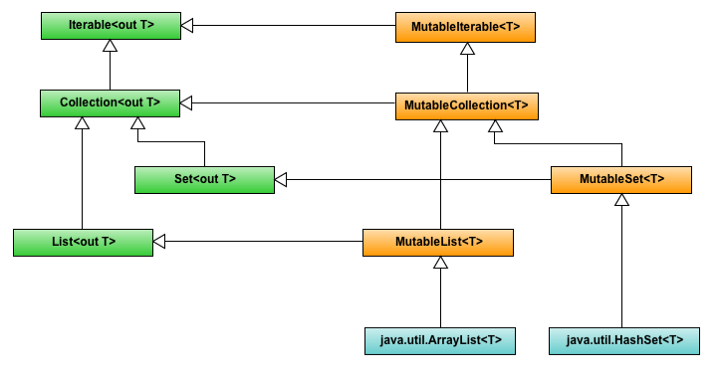
Kotlin에서는 읽기 전용 프로퍼티와 읽고 쓸 수 있는 프로퍼티가 있다고 했습니다. 마찬가지로 컬렉션에서도 읽기 전용 컬렉션과 읽고 쓸 수 있는 컬렉션이 있습니다. 왼쪽에 나와있는 Iterable, Collection, Set, List 인터페이스는 읽기 전용 인터페이스입니다. 즉, 내부 데이터를 변경해주는 메소드는 존재하지 않습니다. 오른쪽에 존재하는 MutableIterable, MutableCollection, MutableSet, MutableList는 왼쪽 인터페이스를 상속받아서 만든 인터페이스로 여기서는 변경을 위한 메소드가 추가되는 것입니다.
정확하게 말하자면 읽기 전용 컬렉션이 자체적으로 변경을 할 수 없는 것이 아닙니다. 변경은 모두 가능하지만 변경을 위한 인터페이스가 존재하지 않기 때문에 변경을 할 수 없다고 생각하시는게 맞습니다!
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}읽기 전용 컬렉션이나 읽고 쓸수 있는 컬렉션의 확장함수는 대부분 읽기 전용으로 설계하여 반환하고 있습니다. toMutableList, toMutableSet 과 같이 강제적으로 바꾸는 메소드가 아닌 이상은 이처럼 설계되고 있는데 이 설계의 이유에는 시스템 안정성에 있습니다. 가변성으로 인한 단점을 언급했듯이 최대한 불변하는 컬렉션을 사용하도록 권장하기 위해 설계가 되지 않았나 싶습니다.
val list = listOf(1,2,3)
if(list is MutableList){
list.add(4)
}읽고 쓸수 있는 인터페이스는 읽기전용 인터페이스를 상속받아서 사용한다고 하였는데 위의 코드는 읽기 전용 인터페이스를 읽고 쓸수 있는 인터페이스로 다운캐스팅을 시도합니다. 컬렉션에서의 다운캐스팅은 추상화를 무시하는 행동이며 코드 자체가 안전하지 않고 예측할 수 없는 결과를 가져오기에 사용하면 안됩니다!!
3) 데이터 클래스의 copy
위에서 가변변수를 사용하면서 단점에 대해서는 설명했었습니다. 그렇다면 불가변변수를 사용하면 장점이 무엇이 있을까요?
- 불가변변수는 한 번 설정이 된 이후에 변경이 되지 않기 때문에 코드 흐름을 파악하기 쉽습니다.
- 멀티 스레드 프로그래밍에서도 공유를 했을 때 모두 동일한 값을 보기에 충돌이 일어나지 않습니다.
- 마지막으로 map, set과 같은 key와 value 형태로 데이터를 가지고 있는 자료구조에서 key 역할로 하기에 유용합니다.
하지만 값을 변경할 수 없다는 큰 단점이 존재하게 되는데 이는 일부를 수정한 객체를 반환해주는 메소드를 만들어서 보완하고 있습니다.예를들면 List에서 filter, map과 같은 메소드로 일부 데이터를 변경한 후 List를 다시 반환해주게 됩니다. 클래스에서도 동일하게 일부를 수정하는 메소드를 각각 정의해주면 되지만 Kotlin에서는 이를 편리하게 해주는 방법이 있습니다.
data class User(
val name: String,
val surname: String
)
var user = User("Maja","Markiewicz")
user = user.copy(surname = "Moskala")
print(user) // User(name = Maja, surname = Moskala)데이터 클래스를 정의한 후 copy 메소드를 사용하면 일부만 수정된 새로운 객체를 손쉽게 만들 수 있습니다.
1.2 다른 종류의 변경 가능 지점
val list1: MutableList<Int> = mutableListOf()
var list2: List<Int> = listOf()
list1 += 1
list2 += 1 위 코드에서는 변경가능한 컬렉션과 변경가능한 프로퍼티를 사용하여 각각 1을 더해주고 있습니다. 결과로만 보면 동일한 역할을 수행하지만 내부적으로는 차이가 존재합니다.
@kotlin.internal.InlineOnly
public inline operator fun <T> MutableCollection<in T>.plusAssign(element: T) {
this.add(element)
}변경가능한 컬렉션에서 호출되는 연산자 메소드는 plusAssign 메소드로 해당 리스트를 직접 값을 추가하고 있습니다. MutableCollection에서 add 메소드가 정의되어 있으며 동기화가 구현되어 있는지는 확실하게 알지 못합니다. 따라서 변경가능 컬렉션을 사용하는데 멀티 스레드 프로그래밍으로 작성이 되어있을 경우 예기치 못한 문제가 발생할 수 있습니다.
public operator fun <T> Collection<T>.plus(element: T): List<T> {
val result = ArrayList<T>(size + 1)
result.addAll(this)
result.add(element)
return result
}변경가능한 프로퍼티에 읽기전용 리스트를 가지고 값을 추가할 때 plus 연산자가 호출됩니다. 내부 코드를 보면 새로운 ArrayList를 생성하고 값을 모두 더한 뒤 새로운 값을 추가적으로 더해주고 있습니다. 즉, plus 메소드를 사용하는 곳 자체가 변경지점이 되는데 이 경우에는 사용하려고 할 때 동기화 처리만 해주면 안정성을 높일 수 있습니다.
따라서 이 책에서는 mutable 컬렉션을 사용하는 것이 처음에는 편할 수도 있지만 변경가능한 프로퍼티를 사용하여 읽기 전용 컬렉션을 사용하는게 객체 변경 제어 측면에서 더 좋다고 서술하고 있습니다.
아직 와닿는 내용은 아니지만.. 조금씩 배우다보면 이해할 날이 올 것이라고 생각합니다.
이 글을 읽으신 분들중에 어떤 면에서 객체 변경 제어가 좋은지 아신다면 댓글 꼭 부탁드립니다. 😢
1.3 변경 가능 지점 노출하지 말기
data class User(val name: String)
class UserRepository{
private val storedUsers: MutableMap<Int, String>
mutableMapOf()
fun loadAll(): MutableMap<Int, String>{
return sotredUsers
}
} 위의 코드를 보면 문제점이 한 눈에 보이시나요? 안드로이드 개발에서는 Backing Property를 사용하여 변경가능한 프로퍼티는 private로 유지하여 클래스 내부에서만 변경하고 외부에는 변경가능하지 않는 프로퍼티를 노출시킵니다. 이 스니펫에서는 loadAll이라는 메소드로 변경가능한 컬렉션을 노출시키는데 어디서든 변경이 가능하기에 정말 위험합니다.
class UserHolder{
private val user: MutableUser()
fun get(): MutableUser{
return user.copy()
}
}data class User(val name: String)
class UserRepository{
private val storedUsers: MutableMap<Int, String>
mutableMapOf()
fun loadAll(): Map<Int, String>{
return sotredUsers
}
}이를 해결하기 위한 2가지 방법으로 copy 메소드 활용과 읽기 전용 타입으로 업캐스팅하여 반환하는 방법입니다. 위에 설명을 잘 이해하셨다면 쉽게 이해하실 것이라고 생각하여 설명은 생략하겠습니다.😘
2. 변수의 스코프를 최소화하라
Kotlin에서 변수와 프로퍼티의 스코프는 최소화하는 것이 좋습니다. 스코프가 넓을 경우는 어디서든 해당 변수와 프로퍼티에 접근하여 변경할 수 있으며 코드 분석 시에 알아야할 요소들이 많아질 수 있습니다.
- 프로퍼티보다는 지역 변수를 사용하는 것이 좋습니다.
- 최대한 좁은 스코프에서 변수가 유효하도록 합니다
- 변수를 정의할 때는 되도록이면 초기화하는 것이 좋으며, 여러 변수들을 초기화 시에 구조분해도 활용하면 좋습니다.
2.1 캡처링
캡처링에 대해서 확실하게 이해하지 못해서 추후에 작성하도록 하겠습니다.
val primes: Sequence<Int> = sequence {
val numbers = generateSequence(2) { it + 1 }
var prime: Int
while(true){
prime = numbers.first()
yield(prime)
numbers = numbers.drop(1)
.filter {it % prime != 0 }
}
}
print(primes.take(1).toList()) // [2,3,5,6,7,8,9,10,11,12]3. 최대한 플랫폼 타입을 사용하지 말라
Kotlin은 자바와 같은 다른 프로그래밍에서 넘어온 타입을 특수하게 다루는게 이 타입을 플랫폼 타입이라고 부릅니다. 플랫폼 타입을 사용할 때는 문제가 없을지 몰라도 미래에는 변경될 수도 있기에 항상 주의를 기울여야 합니다. 가장 좋은 것은 설계자가 @Nullable, @NotNull과 같은 어노테이션으로 표시하거나 주석으로 작성해놓은게 좋습니다.
// Java
public class JavaClass{
public String getValue() {
return null;
}
}
// Kotlin
fun statedType() {
val value: String = JavaClass().value // NPE
// ...
println/(value.length)
}
fun platformType() {
val value = JavaClass().value
// ...
println(value.length) // NPE
}두 가지 모두 NPE(Null Pointer Exception)이 발생하지만 발생한 위치가 다릅니다. statedType 메소드에서는 String 타입을 받아야 하는데 null 값이 들어오기에 값을 가져오는 위치에서 NPE가 발생합니다. platformType 메소드에서는 플랫폼 타입으로 지정하였고 지정된 변수는 nullable 일수도 있고 아닐 수도 있습니다. 따라서 위 코드에서는 값을 사용하는 곳에서 NPE가 발생하고 이와 같은 경우가 복잡해질 경우는 오류를 찾는데 굉장히 어려울 수 있습니다.
4. inferred 타입으로 리턴하지 말라
Kotlin의 타입추론은 JVM에서 가장 널리 알려진 특징입니다. 타입 추론의 장점도 있겠지만 외부 라이브러리를 사용하거나 추후 유지보수성에서 문제가 발생할 수 있기에 명시적으로 타입을 적는 것이 좋습니다.
interface CarFactory{
fun product(): Car
}
val DEFAULT_CAR: Car = Fiat126P()문제가 되는 상황에 대해서 설명하자면 먼저 CarFactory 라는 인터페이스가 존재하고 내부 메소드에서 Car를 반환하도록 명시적으로 지정되어 있습니다. 이와 같을 때는 문제가 없습니다.
interface CarFactory{
fun product() = DEFAULT_CAR
}
val DEFAULT_CAR = Fiat126P()다른 사람이 볼 때 DEFAULT_CAR가 처음에 명시적으로 Car가 지정되어 있기에 타입 추론에 의해 자동 지정될 것으로 생각하여 product 메소드의 반환 값을 DEFAULT_CAR로 수정하였습니다. 또 다른 사람은 DEFAULT_CAR 또한 자동으로 타입이 지정된다고 생각해서 생략을 했다고 하면 이 때 문제가 발생합니다. CarFactory 인터페이스를 구현하더라도 Fiat126P 자동차 외에는 다른 것을 만들지 못합니다. 따라서 리턴 타입을 API를 사용하는 개발자들에게 중요하게 알려주는 정보이기 때문에 확실하게 지정해주는 편이 좋습니다.😉
5. 예외를 활용해 코드에 제한을 걸어라
Kotlin에서 예외를 활용한 코드를 통해 다음 로직으로 실행이 안되게 제한을 걸 수 있습니다. 일반적인 서비스에서 제한을 걸면 서비스 사용자에게는 좋지 않을 수 있으나, 예상치 못하는 동작을 하는 것보다 빠르게 예외를 확인할 수 있다는 측면에서 좋습니다.
- require : Argument 제한
- check : 상태 관련 동작 제한,
- assert : 테스트 모드에서 참/거짓 확인
- return or throw 활용한 Evis 연산자
require vs check
require이나 check 블록 모두 참/거짓을 판단하여 참일 경우 다음 코드를 실행하고 거짓일 경우에는 람다식 호출과 함께 예외가 발생합니다. 또한, require과 check는 모두 상호호환이 가능한데 왜 2가지 메소드로 나누었을까요? 🤔
이 답변에 대해 생각을 해보면 함수형 프로그래밍으로 코드를 작성 시에 메소드 명을 보고 어떤 용도인지 한눈에 확인할 수 있도록 만들기 위함인 것 같습니다. Kotlin의 scope function(apply, let, also, with, run)도 어떤 것들을 사용하더라도 동일하게 수행하도록 만들 수 있지만 메소드 별로 주로 사용되는 용도가 있는 것과 동일한 이유이지 않을까 싶습니다. 개인적인 생각이라 이 부분에 대해서도 피드백 있으시면 부탁드립니다 🤗
nullablity와 스마트 캐스팅
require, check 블록으로 어떤 조건을 확인했다면 이후 코드블록부터는 해당 조건이 이미 만족했다는 것을 가정하고 실행됩니다. 즉, null 여부나 상태를 확인했을 때 스마트 캐스팅이 된다고 보시면 됩니다.
class Person(val email: String?)
fun validateEmail(email: String) {}
fun sendEmail(person: Person, text: String){
val email = requireNotNull(person.email)
validateEmail(email)
}위 코드처럼 requireNotNull로 person.email이 null이 아닌지 확인 후 validateEmail에 스마트 캐스팅된 email 변수를 String처럼 사용할 수 있습니다.
fun sendEmail(person: Person, text: String){
val email: String = person.email ?: return
// ...
}
fun sendEmail(person: Person, text: String){
val email: String = person.email ?: run {
log("Email not sent, no email address")
return
}
}또는 위 코드처럼 return 과 run 블록을 활용한 Evis 연산자를 통해서도 제한을 걸 수 있습니다
정리
다음 글에서 1장의 6~10번 아이템에 대해서 추가로 작성하도록 하겠습니다.
- var보다는 val을 사용하여 가변성 제한
- 변수의 스코프는 최소화
- 플랫폼 타입을 사용하지 말자!
- 명시적으로 추론 타입을 리턴하자
- 예외를 활용하여 코드에 제한을 두자
