2023-01-27 금요일
1. 최솟값 구하기
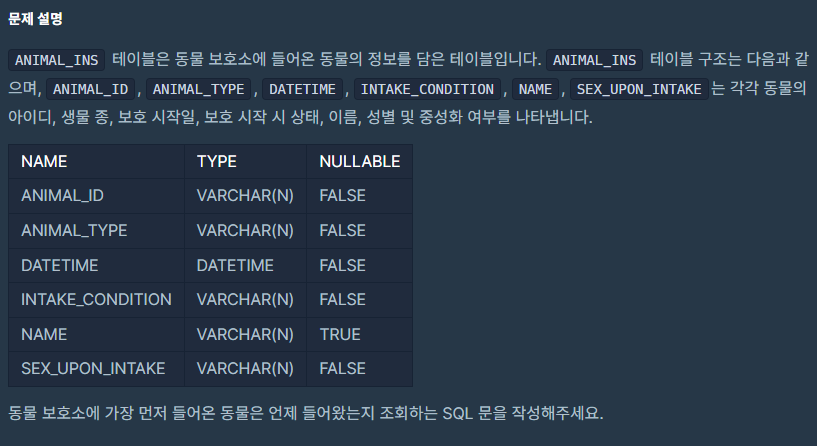
문제
- 들어온 일자 datetime 구하기
- 가장 먼저 들어온 동물 구하기
1. ANIMAL_INS 테이블 전체 조회
SELECT * FROM ANIMAL_INS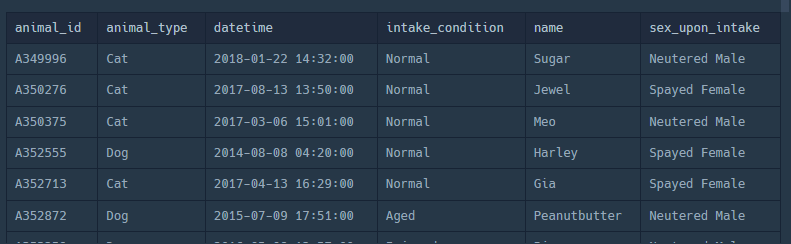
2. datetime 컬럼 출력 (언제 들어왔는지)
SELECT datetime
FROM ANIMAL_INS
3. datetime ASC 차순 출력 (SubQuery사용)
SELECT datetime
FROM ( SELECT *
FROM ANIMAL_INS
ORDER BY datetime ASC )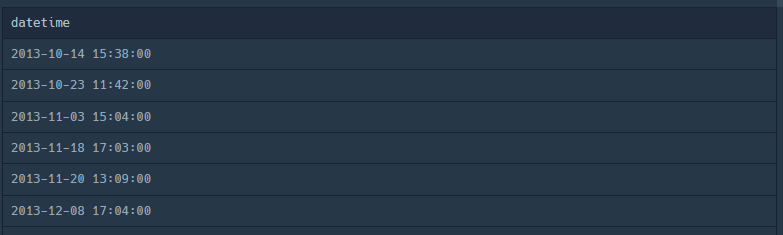
4. 가장 먼저들어온 동물 한 마리 출력
SELECT datetime
FROM ( SELECT *
FROM ANIMAL_INS
ORDER BY datetime ASC )
WHERE ROWNUM <= 1
2. 동물 수 구하기
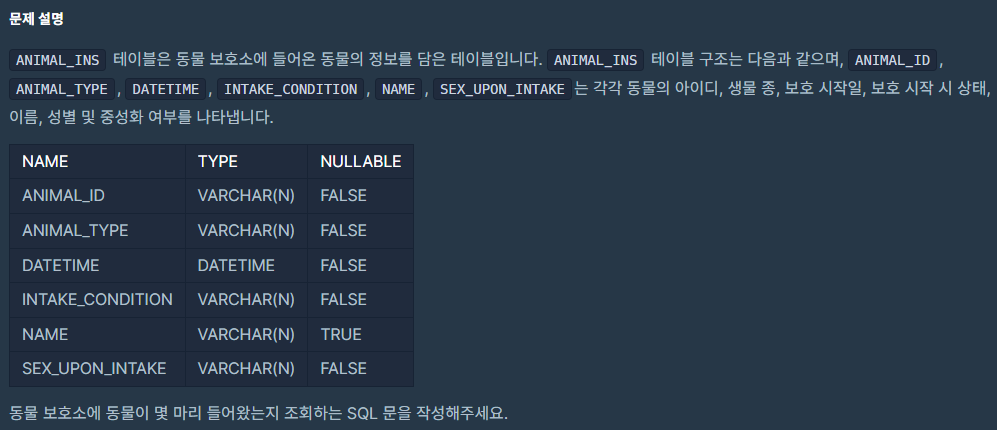
문제
- 몇 마리의 동물이 들어왔는지
1. ANIMAL_INS 테이블 전체 조회
SELECT * FROM ANIMAL_INS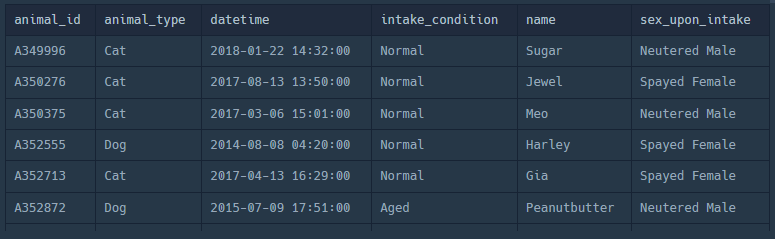
2. 몇 마리가 들어왔는지 출력
SELECT COUNT(*)
FROM ANIMAL_INS
3. 중복 제거하기

문제
- 동물의 이름 개수 구하기
- 이름이 NULL일 경우 미포함
- 중복될 경우 한 개로 칭함
1. ANIMAL_INS 테이블 전체 조회
SELECT * FROM ANIMAL_INS
2. 동물의 이름 출력
SELECT name
FROM ANIMAL_INS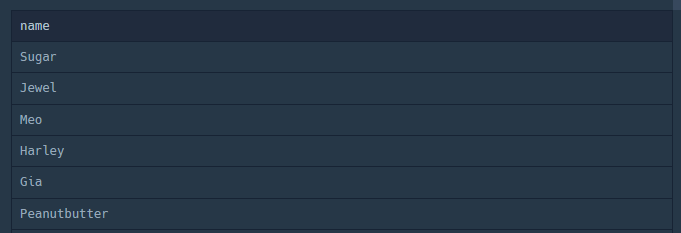
3. 동물의 이름 NULL일 경우 미포함
SELECT name
FROM ANIMAL_INS
WHERE name IS NOT NULL
4. 동물의 이름 중복제외
(1) DISTINCT 사용
SELECT DISTINCT name
FROM ANIMAL_INS
WHERE NAME IS NOT NULL(2) GROUP BY 사용
SELECT name
FROM ANIMAL_INS
WHERE NAME IS NOT NULL
GROUP BY name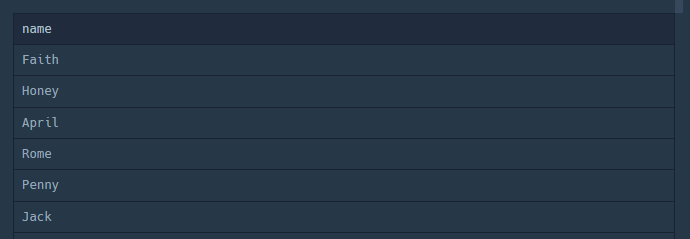
5. 이름의 개수 조회 및 SubQuery 사용
(1) DISTINCT 사용
SELECT COUNT(*)
FROM ( SELECT DISTINCT name
FROM ANIMAL_INS
WHERE name is NOT NULL )(2) GROUP BY 사용
SELECT COUNT(*)
FROM ( SELECT name
FROM ANIMAL_INS
WHERE name is NOT NULL
GROUP BY name )
DISTINCT와 GROUP BY의 차이
1. DISTINCT
- 컬럼 내의 데이터 중복을 제거하여 조회한다.
- 데이터의 중복을 제거할 때 사용
2. GROUP BY
- 컬럼 내의 데이터들의 유니크한 값을 기준으로 결과를 가져온다.
- 데이터 정렬 진행
- 데이터를 그룹화한 후 집계함수를 사용하고자 할 때
3. 결론
- 가독성과 성능(속도)을 위해 중복제거만을 사용한다면 DISTINCT를 사용하는 것을 권장한다.

Back-end이기도 Front-end이기도 한 Full-stack Developer🚀