30분만에 만드는 학식 스크랩

❗조금 묵혀두었던 글이라 조금 별거 없을수 있습니다.
계기
대학에 입한한지 여언 3년째 1학년 때분터 기숙사에 들어온 나는 지금까지 1번만 제외하고 계절학기 포함하여 계속해서 학교에서 지내고 있는데 계속해서 기숙사 밥만 먹게 되다보니까 약간 기숙사 밥에 질려가게 되었다. 그래서 밥이 맛이 없는 날이면 사먹게 되는 날이 늘어가게 되었는데 내가 생각하기에 대충 맛이 없을것 같던 밥이 친구들의 말을 들어보니 맛있었던 적이 종종 있었다. 이런 경험에서 출발하여 급식 후기를 남기고 공유할수 있는 웹사이트를 개발하기 위해서 먼저 간단한 식단을 스크랩 하는 코드를 간단하게 적어보았다.
스크랩
우선 학교밥에 대한 후기를 남기기 위해서는 학교 급식에 대한 데이터 들이 필요했다. 그렇기에 학교 기숙사 사이트에 존재하는 식단 데이터를 가져와서 데이터 베이스에 저장하는 방향으로 가게 되었다.
우선 학교 사이트의 경우에는 자주 바뀌는 데이터도 아니기도 하고 크롤링 해야하는 범위도 적기 때문에 간단하게 css 태그를 이용하여 크롤링 하게 되었다.
뷰티플수프 문서
크롤링을 할때 뷰티플수프나 셀레리움을 사용할 수 있는데
학교 사이트는 정적인 웹사이트 이기 때문에 bs4를 사용하게 되었다.
bs4의 사용법을 공부할때에는 기본적인 웹사이트 관련 지식이 있다면 공식 문서를 참고하여 개발하는것이 가장 좋은 선택이다.
# 사용할 라이브러리 import
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
import unicodedata
import json
import pandas as pd
import lxml
import re교내 웹사이트의 모습
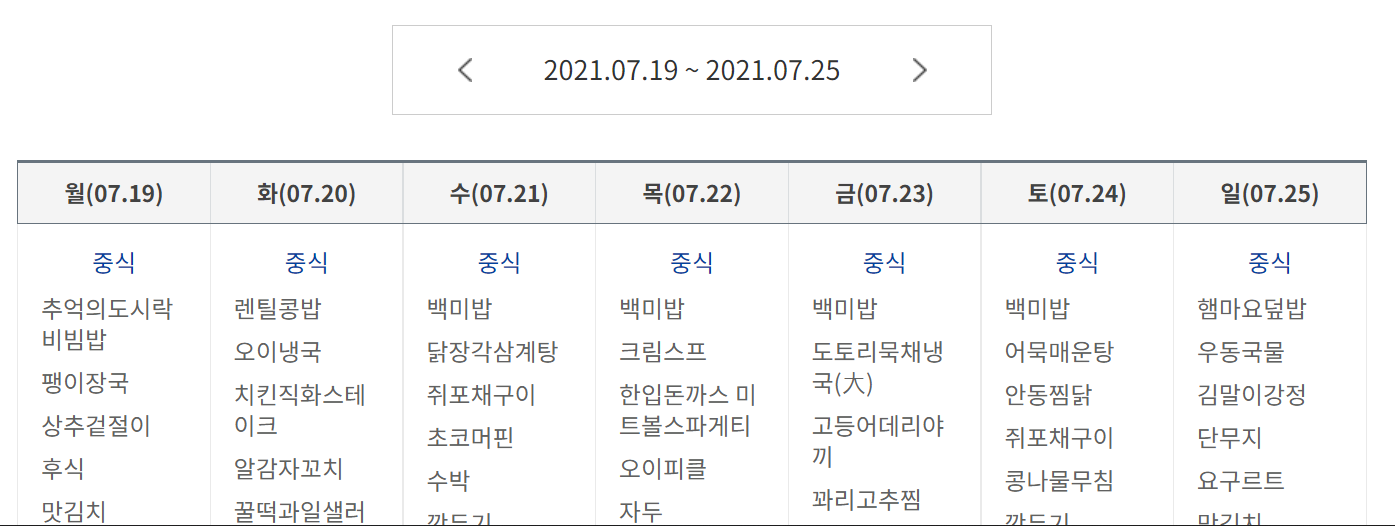
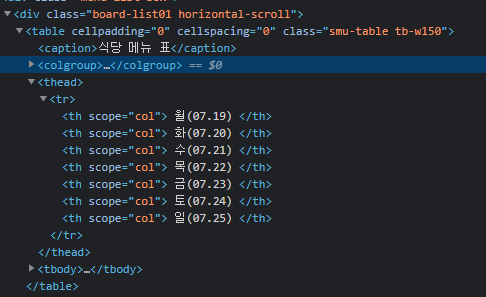
다들 흔하게 하는 방식으로 css 태그를 확인한뒤 해당하는 부분에서 데이터를 가져오게 되었다.
#requests를 이용하여 학교 사이트에서 가져온뒤 bs4를 이용하여 파싱
webpage = requests.get(
"https://dorm.kumoh.ac.kr/dorm/restaurant_menu01.do")
soup = BeautifulSoup(webpage.content, "html.parser")tableSoup = soup.find(attrs={'class': 'board-list01 horizontal-scroll'})
tableSoup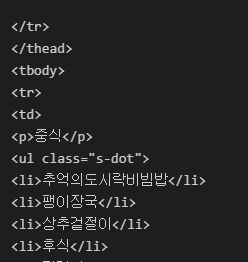
중간 결과를 확인해 본 결과 p태그 내부에 점심과 저녁을 기입하게 되어있는데 데이터 베이스에 저장할때에는 필요없는 정보이기 때문에 p태그를 제거하게 되었다.
tableSoup = soup.find(attrs={'class':'board-list01 horizontal-scroll'})
for tag in tableSoup.find_all('p'):
tag.decompose()table_html = str(soup).replace("\n", " ")
table_df_list = pd.read_html(table_html)[0]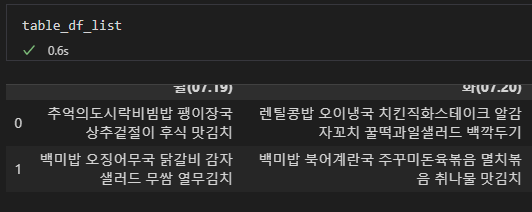
판다스 라이브러리를 이용하여 표 형태로 저장하여 확인해 보았는데 원하던 모습으로 깔끔하게 결과가 나타난 것을 볼수 있었다.
주피터 노트북을 이용하여 크롤링 코드의 기본을 잡았으니 함수로 묶어서 깔끔하게 리팩토링 하였다.
# 기숙사 코드를 얻는 함수
def get_dorm_code(dorm_name):
dorm_code = "menu01"
if dorm_name == "푸름관":
dorm_code = "menu01"
elif dorm_name == "오름관1동":
dorm_code = "menu02"
elif dorm_name == "오름관3동":
dorm_code = "menu03"
return dorm_code
# url를 얻는 함수
def get_dorm_url(dorm_name):
return "https://dorm.kumoh.ac.kr/dorm/restaurant_"+ get_dorm_code(dorm_name)+ ".do"
def get_dorm_soup(url):
webpage = requests.get(url)
soup = BeautifulSoup(webpage.content, "html.parser")
return soup.find(attrs={'class': 'board-list01 horizontal-scroll'})
def clean_soup(soup):
for tag in soup.find_all('p'):
tag.decompose()
return str(soup).replace("\n", " ")
def get_meal(dorm_name):
dorm_url = get_dorm_url(dorm_name)
soup = get_dorm_soup(dorm_url)
html = clean_soup(soup)
res = pd.read_html(html)[0]
return res간단한 웹페이지로
간단하게 flask로 서버로 만들어서 사용해 보았다.
from flask import Flask
app = Flask(__name__)
@app.route("/")
def pu():
return get_meal("푸름관").to_html()
if __name__ == "__main__":
app.run()

웹사이트를 접속하면 위와 같은 스크랩된 결과를 볼 수 있다.
