Antwarg, Liat, et al. "Explaining anomalies detected by autoencoders using SHAP." arXiv preprint arXiv:1903.02407 (2019).
How to explain Autoencoder anomalies
-
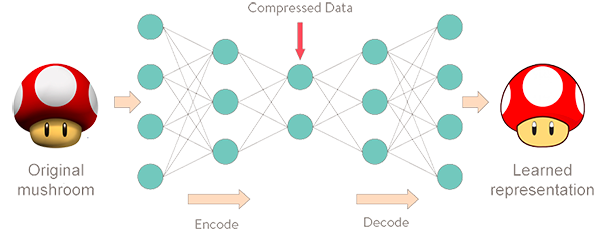
Input values와 Autoencoder를 통해 얻은 Reconstructed output values 사이의 차이 (Reconstruction Error)를 설명하는 방법을 제시
- 만약 Anomaly가 존재한다면 Reconstruction error가 높은 것이고, 어떠한 설명 모델을 이용하여 왜 높은지 설명해줘야 함
- 따라서 제안하는 방법은 Reconstructed feature의 SHAP values를 계산하고 이를 실제 Input values와 연관지음
-
Notations
- Given input instance with a set of features
- Corresponding output and reconstructed values
- Autoencoder model
- Reconstruction Error of the instance
- A reordering of the features which are in
errorListsuch that topMfeatures= contains a set of features for which the total corresponding errorstopMerrors: represent an adjustable percent of .
-
논문에서 제안하는 방법은
topMFeatures내에 높은 Reconstruction errors의 영향을 받은 Feature들을 SHAP value를 이용해 설명하는 것
Algorithm
Calculate SHAP values for topMfeatures
-
Input
- : An instance we want to explain
- : Instances that kernel SHAP uses as background examples
ErrorList: An ordered list of error per feature- : Autoencoder model
-
Output
-
shaptopMfeatures: SHAP values for each feature withintopMfeatures -
Algorithm
topMfeatures<- top values fromErrorListfor each
iintopMfeaturesdoexplainer<-shap.KernelExplainer(f, X1..j)shaptopMfeatures[i]<-explainer.shap_values(X, i)return
shaptopMfeatures
Divide SHAP values into those contributing and offsetting an anomaly
-
Input
shaptopMfeatures: SHAP values for each features- : An instance we want to explain
- : The prediction for
-
Output
shapContribute,shapoffset
-
Algorithm
for each
iinshaptopMfeaturesdoif then
shapContribute[i]<-shaptopMfeatures[i] < 0shapOffset[i]<-shaptopMfeatures[i] > 0else
shapContribute[i]<-shaptopMfeatures[i] > 0shapOffset[i]<-shaptopMfeatures[i] < 0return
shapContribute,shapOffset
Comments
-
논문을 아무리 보아도 Top-m Features를 선정하되, 전체 변수에 대해서도 충분히 유의미한 결과인지에 대한 내용을 찾기가 어려움
-
Anomaly를 설명하는 내용을 다루고 있기 때문에, 철저하게 inlier 값들은 배제하고 있음
-
관련한 Repository는 있음
- 라이브러리는 아니고 Notebook 형식으로 예제 다루듯 설명하고 있음
- https://github.com/liuyilin950623/SHAP_on_Autoencoder
Updates (April 26, 2021)
-
SHAP 라이브러리에
DeepExplainer를 활용하는 것이 더 나을 것으로 보임- Top-m Features를 선정할 필요 없이 전체 변수에 대해서 계산할 수 있음
