네이버는 작년 9월 20일 생성형 AI 검색 서비스 ‘Cue(큐):’의 베타 서비스를 시작하여, 11월 30일 포털 통합 검색에 적용했으나 현재 포털에서는 배너만 제공하고 공식 페이지에서만 사용이 가능하다.
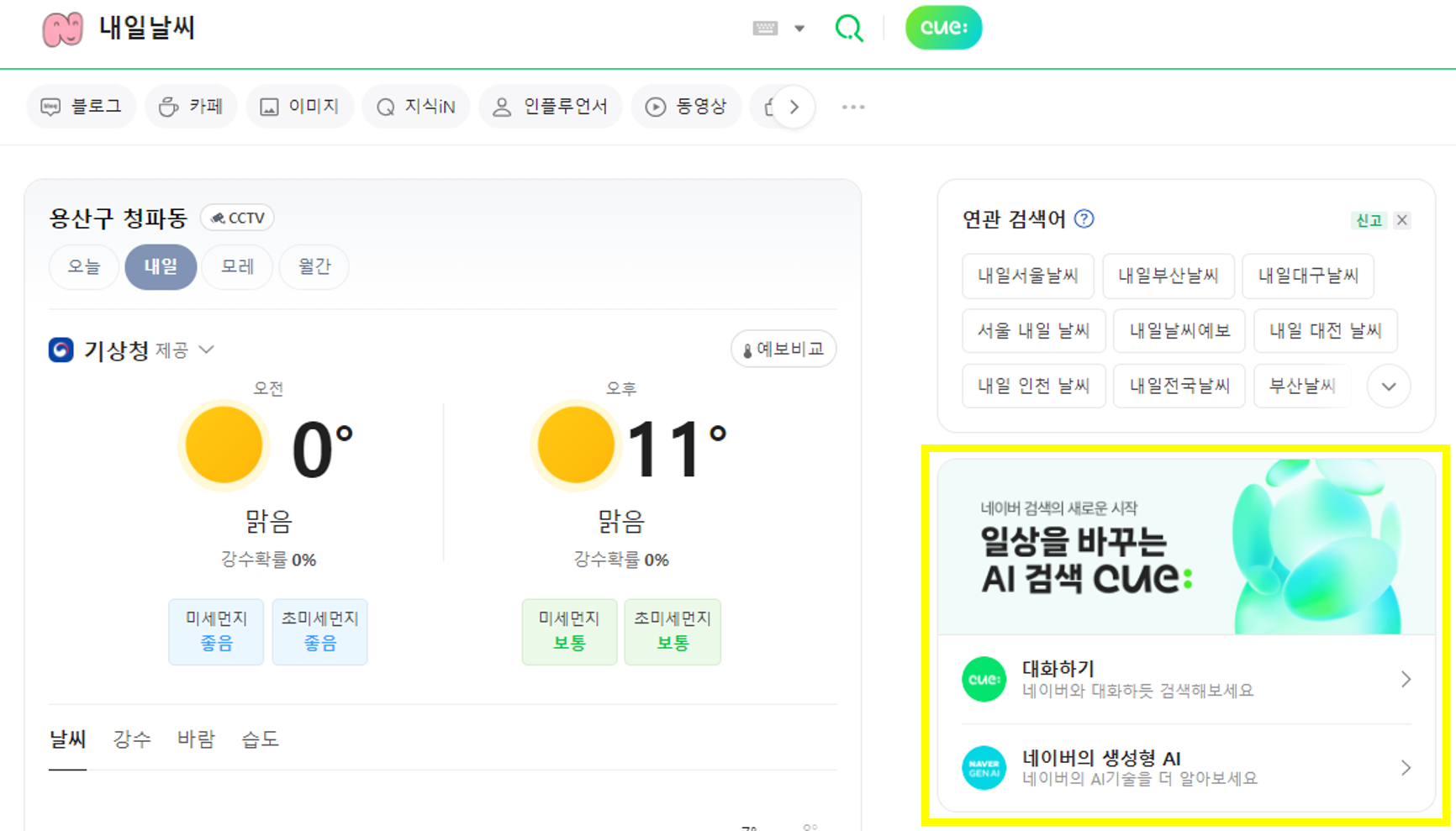
로그인 시 검색바 우측에 cue:가 활성화 되고, 입력하는 검색어에 따라 필요시 cue: 검색 결과가 상단에 표출된다.


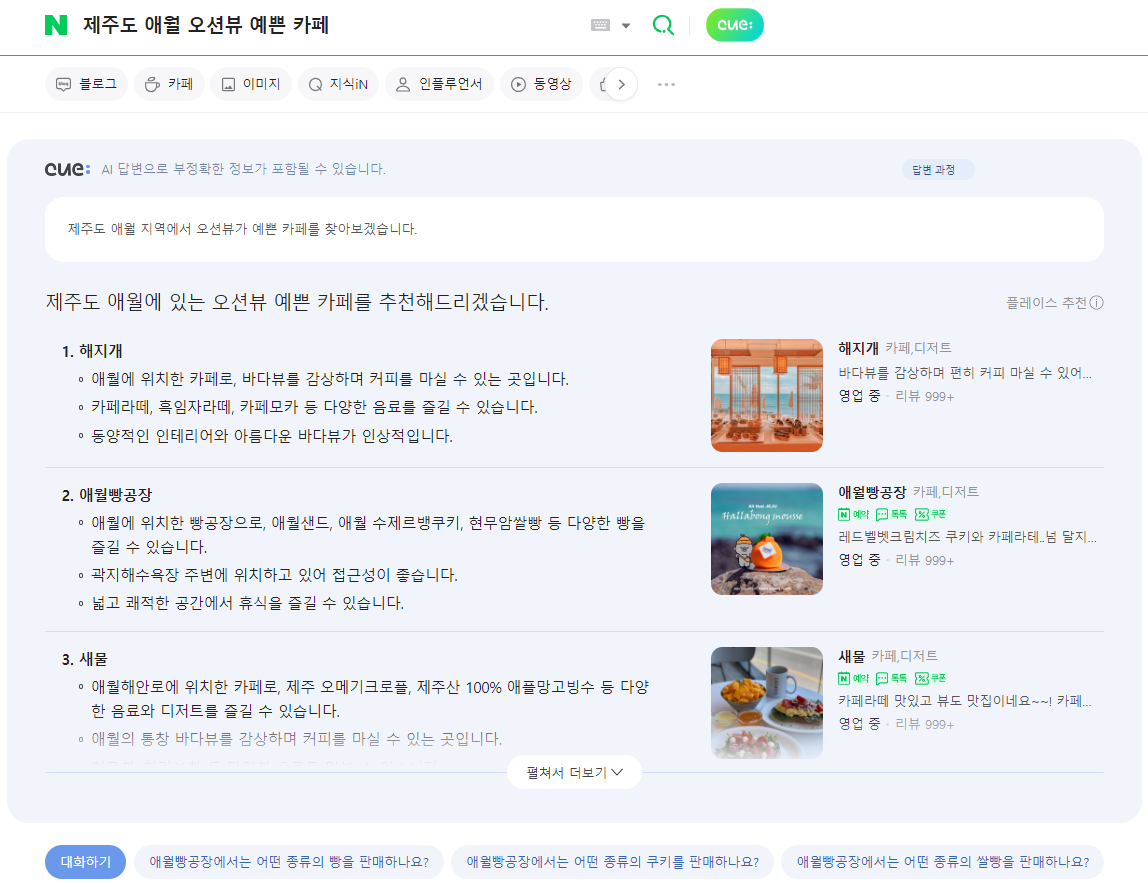
올해 중에 모바일 환경에 적용하고, 멀티모달 기술을 지원할 예정이다.
서비스 소개
Cue:는 네이버의 생성형 AI 모델HyperCLOVA X를 검색 서비스에 특화 시킨 생성 AI 서비스다.HyperCLOVA XVSCue:VSCLOVA XHyperCLOVA X는 네이버의 초대규모(Hyperscale) 언어모델로, OpenAI의 GPT나 구글의 Gemini와 비교할 수 있으며, 고품질의 한국어 데이터를 학습하여 한국어에 대해 높은 성능과 효율적인 언어 처리 능력을 제공함.CLOVA X는HyperCLOVA X기술을 바탕으로 만들어진 대화형 인공지능 서비스로 플로그인 시스템인 '스킬'을 통해 네이버의 내부 서비스뿐만 아니라, 다양한 외부 서비스와 연동됨.
주요 기능
-
사용자의 질문과 관련된 정보를 검색한 후 내용을 요약하여 유용한 답변을 생성한다.
-
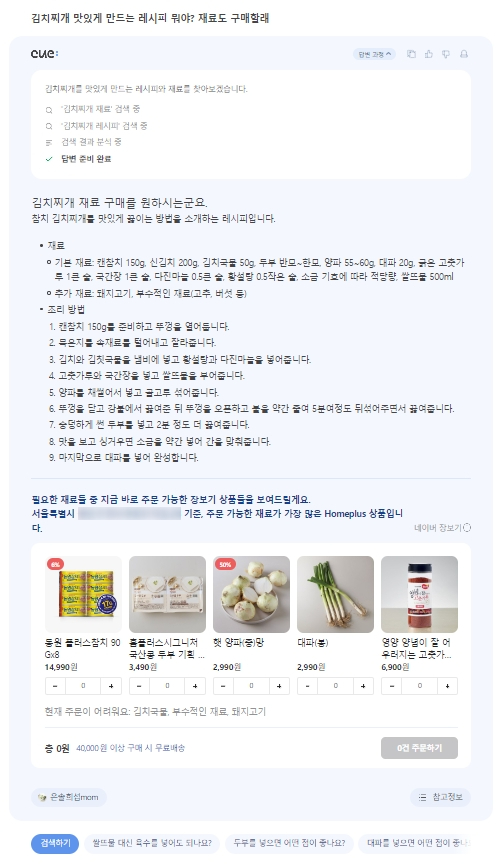
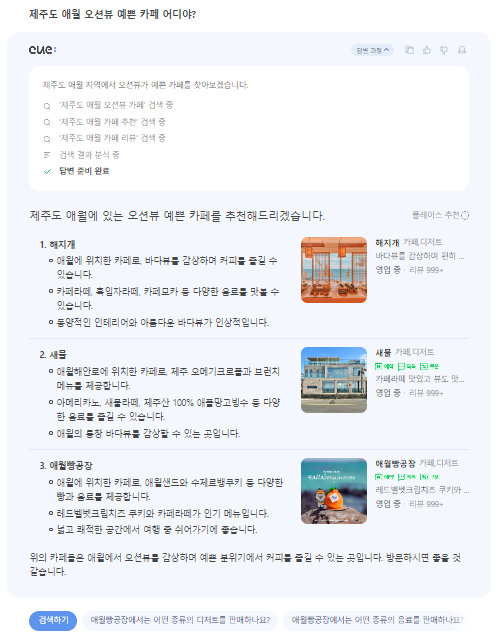
가장 큰 강점은 단순한 검색 결과 제공을 넘어, 네이버 생태계 내 여러 서비스 (쇼핑, 위치, 웹 검색 등 Cue:에는 50개 이상의 서비스에 연결되어 있다.)와 자연스럽게 연결되어 제품을 검색하면 구매까지, 숙소를 검색하면 예약까지 한 번에 해결할 수 있다.
기술적 특징
-
네이버에서는 아래와 같은 특징으로 플러그인(Plug-in)을 사용하는 타 생성형 LLM 서비스와는 차별화된다고 설명한다.
- 하나의 LLM을 사용하는 것이 아니라, 크기와 기능이 다른 여러 언어 모델을 조합하여 모듈화된 LLM 플랫폼(Modularized LLM Platform)이다. 따라서, 사용자의 요청에 대해 사용자의 검색 의도를 만족시키는데 필수적인 부분만 활성화시켜 효율성을 향상시키고 응답 속도를 높였다.
- 그리고 이런 모듈화된 LLM(Modularized LLM)들은 사용자 만족도를 보상 신호(Reward Signal)로 사용하여 End-to-End로 Platform-Level에서 학습시켰다.
-
cue:는 검색된 결과를 바탕으로 답변을 생성(Retrieval-Augmented Generation, RAG)하며, 아래 그림과 같은 과정을 거쳐 답변한다.
-
Reasoning
멀티 스텝 추론(Multi-Step Reasoning)을 통해 네이버의 서비스들을 어떻게 사용하여 사용자의 검색 목적을 달성할 수 있는지 계획(Planning)하며, 정답이 포함된 검색 결과를 가져오는 것이 중요하다.이러한 추론 과정을 사용자에게 보여줌으로써 사용자는
cue:가 어떤 이유로 해당 답변을 제공하는지 논리의 흐름을 명확히 알 수 있다.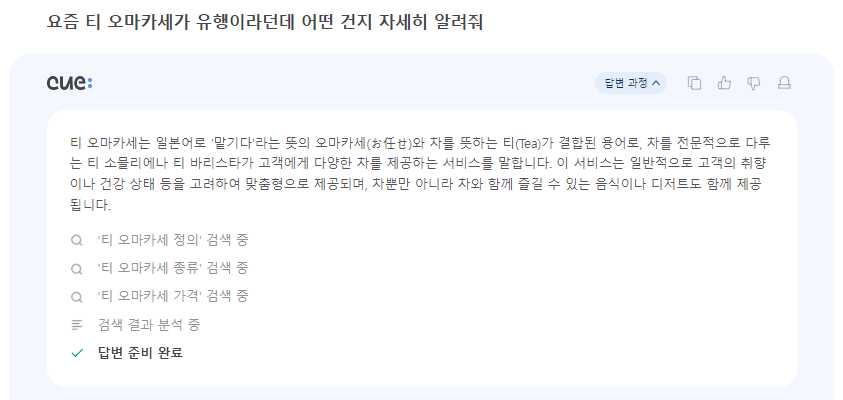
위 예시와 같이 추론에서 검색 계획만 세우는 것이 아니라, 주제와 관련된 사전 학습된 지식을 생성하는 것을 확인할 수 있다.
💡 RAG의 부작용(외부 정보에만 의존하거나 유창성이 저하되는 등)을 보완할 수 있는 방법으로 볼 수 있다.
또한, 단순히 '티 오마카세'를 검색하지 않고 '티 오마카세 정의', '티 오마카세 종류', '티 오마카세 가격'과 같이 구체적인 Query를 여러 개 생성(MultiQueryRetriever와 유사)하여 모호한 질문을 구체화한다.
-
Searching

네이버의 서비스들을 툴로 사용하면서 수립된 검색 계획을 수행(Tool Usage)한다.
Search Planning 된 질의를 활용해 반복적인 검색을 수행해 답변 생성에 충분한 문서들을 확보한다.
통합검색 결과를 참고하고 있으나, 검색 사용자의 질의 의도에 가장 적합한 정보를 제공하기 위해 이용 패턴 데이터를 학습하여 동일한 질의에 대해서도 사용자에 따라 동일한 답변이 제공되지 않을 수도 있다.
-
Evidence Selector
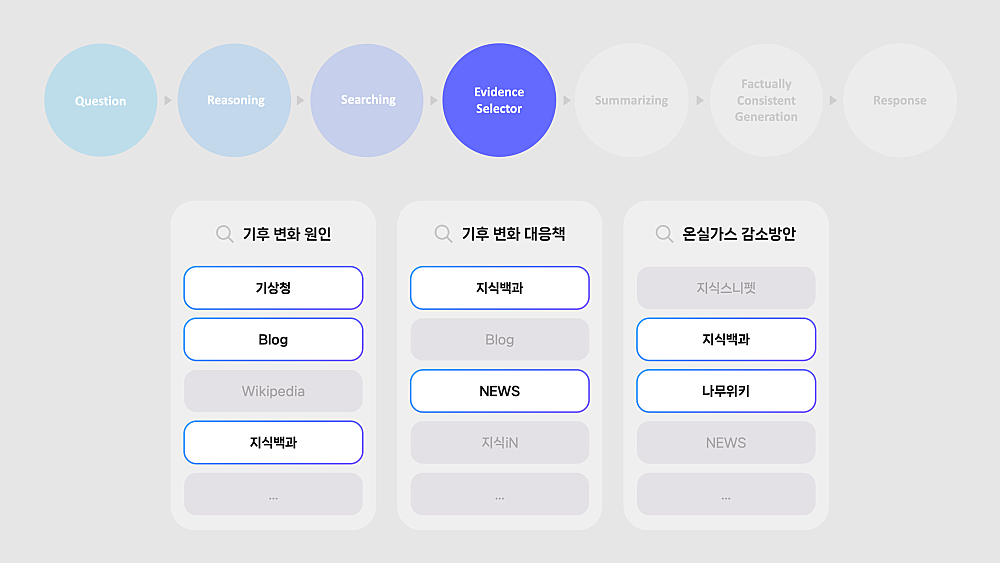
답변 생성 과정에서 Hallucination을 줄이기 위해 보다 신뢰성 있는 결과(검색 결과 속 많은 문서들 중 정답이 포함된 문서)를 선택(Evidence Selection Process)한다.
선택 문서의 판단 기준은 세 가지, ‘질문에 대한 내용이 포함되어 있는가?’, ‘지식베이스, 지식백과, 쇼핑 API 결과 등 신뢰성 있는 문서인가?’, ‘최신 정보인가?’이다.
❓ MRC? LLM을 활용한 Re-ranking?
-
Summarizing
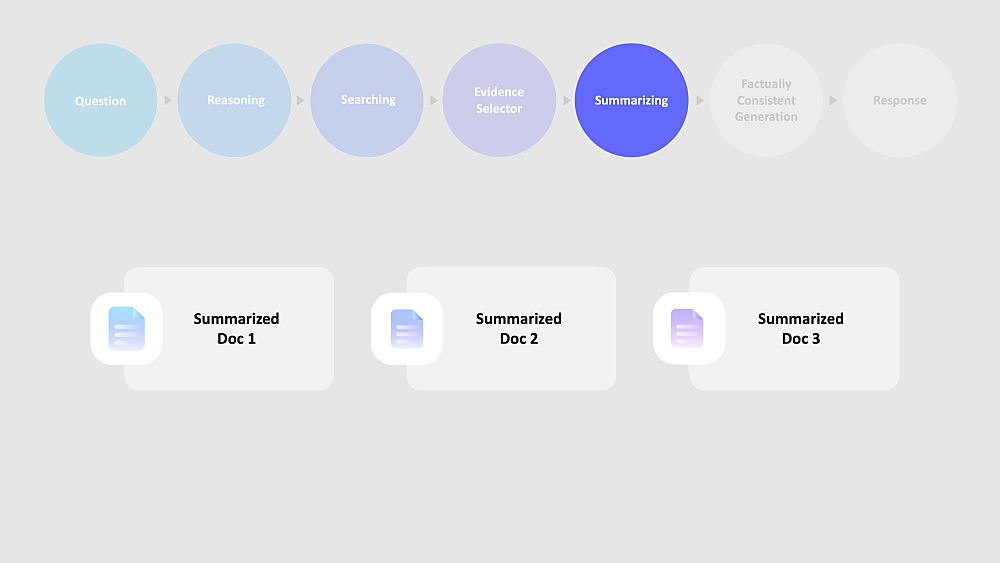
선택된 문서들을 Summarize Model을 사용해 요약한다.
❓ CLOVA Studio 익스플로러의 요약?
-
Factually Consistent Generation
검색 결과와 답변의 사실성이 일치되도록 답변을 생성(Entailment-Based Factually Consistent Generation)하며, 사실적 일관성의 확인을 위해 모델이 자신의 답을 점검하는 자기 성찰(Self-Reflection)기법을 사용하여 사용자에게 사실적 일관성이 비약적으로 향상된 검색 결과에 기반한(Grounding) 답변을 제공한다.
-
-
네이버에서는 세 가지 핵심 기능(
Reasoning,Evidence Selector,Factually Consistent Generation)을 이용해 신뢰할 수 있는 답변을 생성하여, 내부 평가 결과 Hallucination이 72%가 감소했다고 한다. -
답변 생성을 위해 참고한 웹페이지는 답변 하단에 참고정보로 표시하며, 질의응답 주제와 관련된 후속 질문을 추천한다.
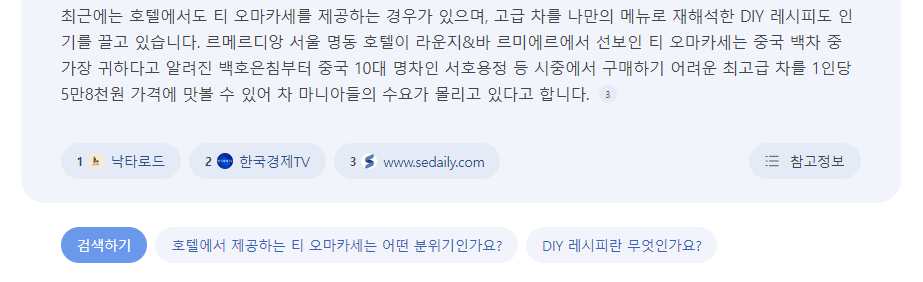
문제점
-
홈플러스와 연동된 장보기가 실제로는 동작하지 않고, 네이버 플레이스를 통한 장소 추천 역시 예약 등의 기능이 바로 진행되지 않아 결국 해당 페이지로 넘어가야 하는 불편함이 있어, 네이버의 콘텐츠를 기반으로 답변을 생성하는 점 외에는 특징이 약화되었다.
-
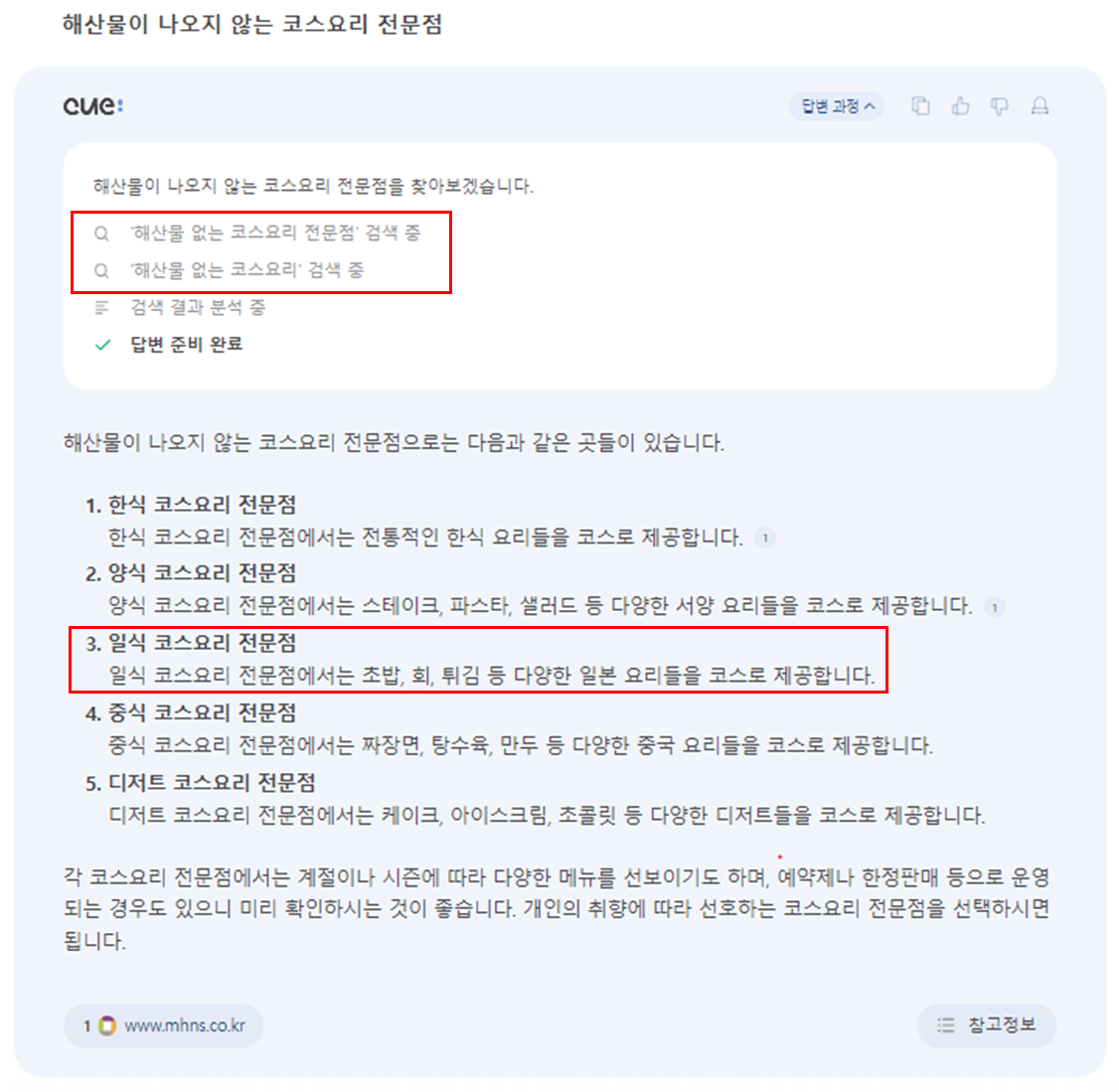
cue:출시 초기에 한 언론사에서 문제로 제기한 '해산물이 나오지 않는 코스요리 전문점' 질의에 대해서 테스트했다.
이전에 해산물을 전문으로 하는 음식점을 추천하던 것과 달리 한식 코스요리 등을 추천하며 답변의 성능은 개선되었지만, 초밥과 회가 포함된 일식 코스요리를 답변해 아직까지 한국어 이해에 한계를 보였다.
또한, '해산물 없는 코스요리 전문점' 같이 추론을 통해 생성한 검색 질의에 '해산물' 키워드가 포함되어 검색 엔진의 특성상 의도와 달리 '해산물'이 포함된 결과가 상위에 있어 답변의 내용이 빈약한 문제가 있다.
Reference
- https://cue.search.naver.com/
- https://code.naver.com/contentDetail/61
- https://channeltech.naver.com/contentDetail/43
- https://channeltech.naver.com/contentDetail/46
- https://channeltech.naver.com/contentDetail/61
- https://seo.tbwakorea.com/blog/what-is-naver-cue/
- https://www.greened.kr/news/articleView.html?idxno=307400
- https://help.naver.com/service/5626/contents/22415?lang=ko
