🔎 집합 자료형
: 숫자, 문자열 등의 모음을 단일의 변수로 저장하는 자료형
🏷️ 집합 자료형 기본 내장함수
my_var = [10, 20, 50, 80, 40]| 내장함수,연산자 | 설명 | 예 | 결과 |
|---|---|---|---|
| len() | 길이 계산 | len([1, 2, 3]), len(my_var) | 35 |
| + (set,dict 사용불가) | 2개의 시퀀스연결 | [2, 3] + [4, 5, 6] | [2, 3, 4, 5, 6] |
| * (set,dict 사용불가) | 반복 | ['Python'] * 2 | ['Python', 'Python'] |
| in | 소속 | 3 in [1, 2, 3] | True |
| 40 in my_var | True | ||
| not in | 소속하지 않음 | 5 not in [1, 2, 3] | True |
| 50 not in my_var | False | ||
| min() | 최소값 요소 | min([1, 2, 3]) | 1 |
| min(my_var) | 10 | ||
| max() | 최대값 요소 | max([1, 2, 3]) | 3 |
| max(my_var) | 80 | ||
| sum() (문자열 제외) | 합산 | sum([1, 2, 3]) | 6 |
| sum(my_var) | 200 | ||
| reversed() (set 사용불가) | 역순 | list(reversed([1, 2, 3])) | [3, 2, 1] |
| sorted(reverse 선택) | 정렬 (기본은 오름정렬) | sorted([3, 2, 1]) | [1, 2, 3] |
🔎 집합 자료형 구분
🏷️ 시퀀스 타입
: 각 데이터에 암묵적인 위치값(index)을 갖는 자료형
- 인덱스는 0부터 부여
단, 시작방향에 따라 번호부여 방식이 다름
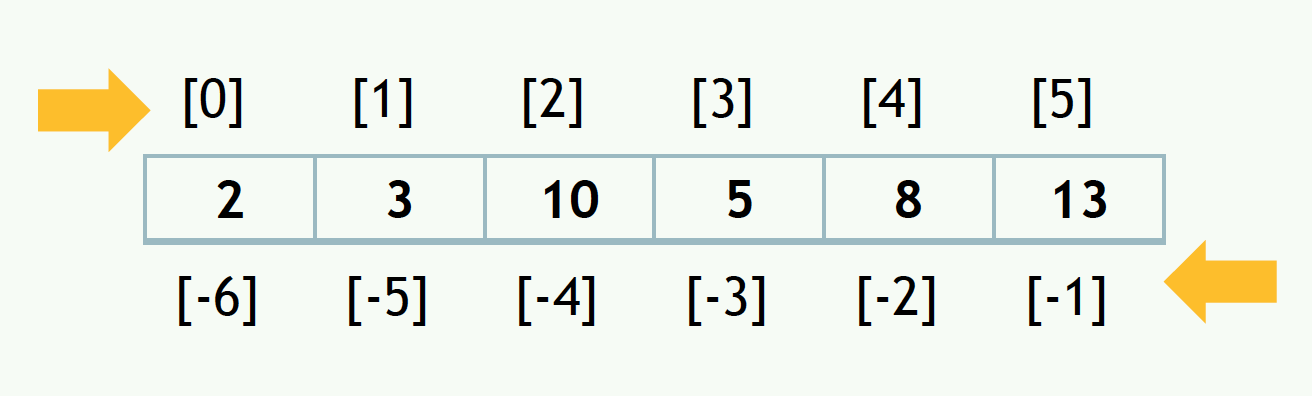
리스트 list
모든 자료형을 하나의 변수로 묶을 수 있으며,
읽기 / 쓰기 모두 가능items = [1, 3, 4.5,'python']
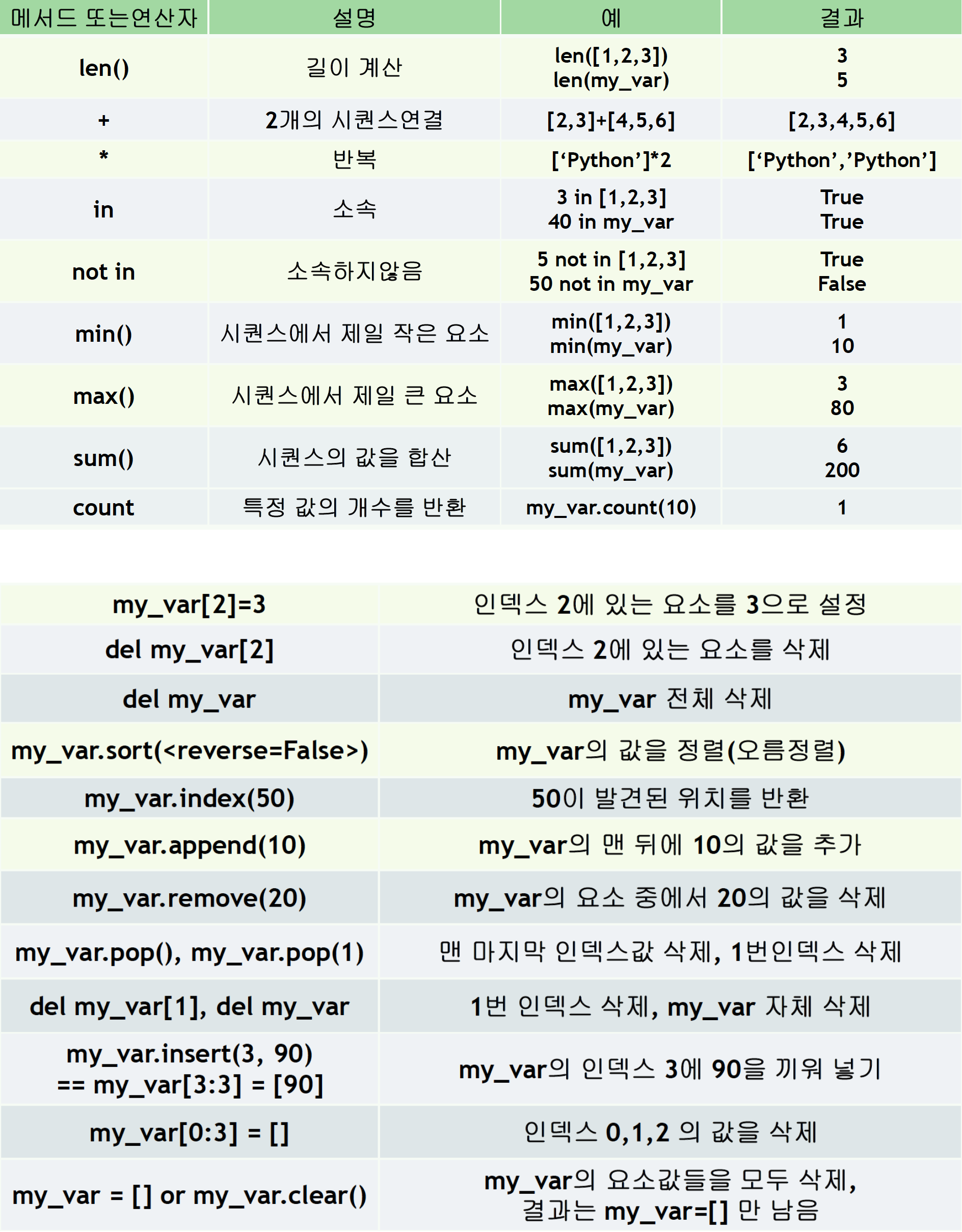
📍 .extend()
a = [1,2,3,4,5]
b = [6,7,8,9]
a.extend(b)
print(a)
>>> [1, 2, 3, 4, 5, 6, 7, 8, 9]📍 .sort()
🔻 기본은 오름차순
🔻 reverse = True, 내림차순
🔻 리스트만 적용 가능
🔻 입력함수 사용 불가 ( append, insert, extend 등 )
a = [3, 5, 2, 8]
a.sort()
print(a) >>> [2, 3, 5, 8]
a.sort(reverse=True)
print(a) >>> [8, 5, 3, 2]📍 sorted()
🔻 기본은 오름차순
🔻 reverse = True, 내림차순
🔻 집합 자료형 모두 적용 가능
a = [3, 5, 2, 8]
b = sorted(a) >>> [2, 3, 5, 8]
print(b)
b = sorted(a, reverse=True)
print(b) >>> [8, 5, 3, 2]문자열 string
: 기본 자료형이면서, 문자 상수들의 집합형
- '' 또는 "" 로 표현
names = 'python' names = "python"
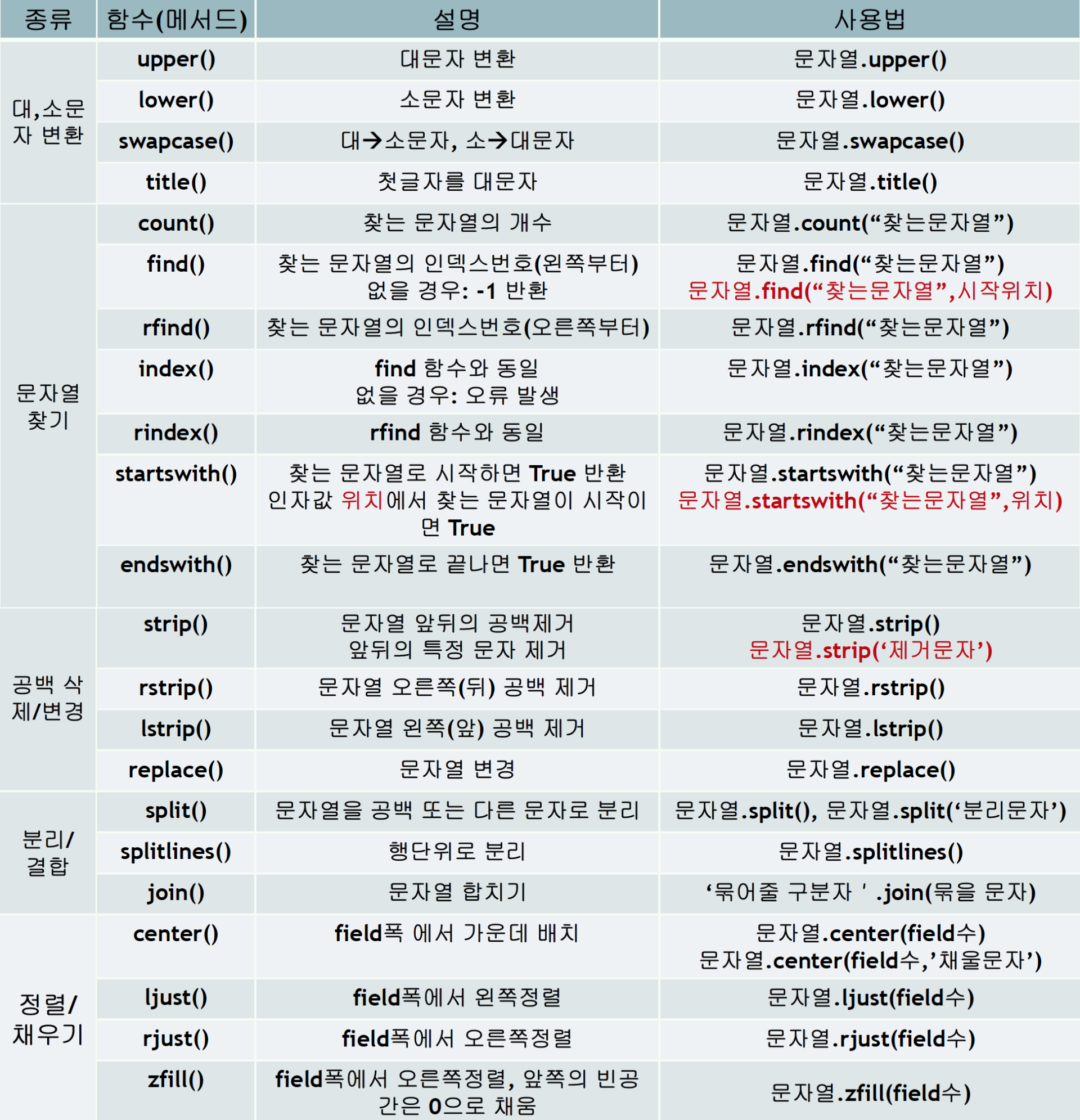
📍 index()
s = "봄이 가면, 여름이 오고, 여름이 가면, 가을이 옵니다"
print(a.index('가을'))
>>> 22📍 index slicing
🔻 서식문자 이용
fruit = "strawberry"
print(f'{fruit:.2s}')
print('%.5s' % fruit)
>>> st
>>> straw🔻 [ start : end : step ] 적용
🔻 step 생략 시, 1
🔻 [ :3 ] 이면 [ 0~2 ] 까지 출력
#전체 문자열 출력
fruit = "strawberry"
print('%s' % fruit[:]) #[::]
>>> strawberry#역순 출력
fruit = "strawberry"
print('%s' % fruit[-1::-1])
print(f'{fruit[::-1]}')
>>> yrrebwarts
>>> yrrebwarts📍 replace()
b = "***대*한*민*국***"
print(b.replace('*',''))
korea = b.replace('*','')
print(korea)
>>> 대한민국
>>> 대한민국📍 split()
year = input('날짜(연/월/일)입력 >> ')
year_split = year.split('/')
print("입력한 날짜의 10년 후 -> ", end='')
print(str(int(year_split[0])+10),'년', end=' ')
print(year_split[1],'월', end=' ')
print(year_split[2],'일',end=' ')
>>>
날짜(연/월/일)입력 >> 2023/03/30
입력한 날짜의 10년 후 -> 2033 년 03 월 30 일📍 join()
myString = input("문자열 입력 :: ").split()
myString_j = ','.join(myString)
print(myString_j)
>>>
문자열 입력 :: happy python
happy,python딕셔너리 dictionary
: 키 (key) / 값 (value) 형식으로 표현키 (key) : 숫자, 문자열, 튜플 값 (value): 숫자, 문자열, 리스트, 튜플
- 키의 중복성을 허용하지 않음
- 각 값은 인덱스 번호가 아닌 키를 이용하여 표현
profile = {'name':'Alice'} print(profile['name']) >> Alice
📍 get()
: 딕셔너리 내 키가 존재한다면, 키에 해당되는 value, 그 외 None 반환
dict = {'name':'건조망고', 'type':'절임'}
value1 = dict.get('origin')
if value1 == None:
print('키가 딕셔너리에 없습니다')
print('origin : ', value1)
>>> origin : None
value2 = dict.get('name')
if value2 == None:
print('키가 딕셔너리에 없습니다')
print('name : ', value2)
>>> name : 건조망고📍 keys()
: keys의 반환값은 iterable 객체이므로 연산자 in에 사용 가능
jelly = {'name' : "Mango", 'type':'절임',
'ingredient':['mango','sugar','yellow dye'],
'origin':'필리핀'}
keys = list(jelly.keys())
print(keys)
>>> ['name', 'type', 'ingredient', 'origin']📍 update()
: 키-값 쌍 추가 및 값 수정, 딕셔너리 확장 및 기존 값 변경
jelly = {'name' : 'Mango',
'ingredient':['mango','yellow dye'],
'origin':'필리핀'}
items = {1:'한국', 2:'스페인'}
#jelly가 items를 업데이트하여 확장됨
jelly.update(items)
print(jelly)
>>>
{'name': 'Mango', 'ingredient': ['mango', 'yellow dye'],
'origin': '필리핀', 1: '한국', 2: '스페인'}
- {} 의 형태가 아닌 쌍으로 수정 및 추가 시
🔻 따옴표 없는 문자열
🔻 : → =
🔻 키가 숫자인 경우, 딕셔너리 형태로 입력
jelly.update({1:'korea’})
jelly.update(name='Cherry')Python에서 dictionary(딕셔너리) 타입은 immutable한 키(key)와 mutable한 값(value)으로 맵핑되어 있는 순서가 없는 집합입니다. 일반적인 딕셔너리 타입은 중괄호로 되어 있고 키와 값으로 이루어져 있습니다.
test_dict = {'0': 'AA',
'1': 'BB',
'2': 'CC',
'3': 'DD'}
test_dict
{'0': 'AA', '1': 'BB', '2': 'CC', '3': 'DD'}
key를 이용하여 value를 찾는 방법은 다음과 같습니다.
test_dict.get('3')
'CC'
test_dict['3']
'CC'
반대로 value를 이용해 key를 찾는 방법은 다음과 같습니다.
[k for k, v in test_dict.items() if v == 'DD']
['3']
또는 {key: value} 를 뒤집어 {value: key} 찾을 수도 있습니다.
convert_test_dict = {v:k for k,v in test_dict.items()} # {'0': 'AA', '1': 'BB', '2': 'CC', '3': 'DD'}
convert_test_dict.get('DD')
'3'
set
: 중복성이 없는 데이터 집합
수학의 집합개념과 동일하며, 집합연산자를 가짐(합집합, 교집합, 차집합 등)dice = {1,2,3,4,5,6,3,2} -> {1,2,3,4,5,6} 으로 저장
📒 집합 자료형 복습 예제
a = [ 'Korea', 'Univ', 'Engineering', 2019 ]
b = [ ]
1️⃣
b = a[::2]
print(b) >>> ['Korea', 'Engineering']
2️⃣
b = a[::-1]
print(b) >>> [2019, 'Engineering', 'Univ', 'Korea']
3️⃣
a.extend(b)
print(a) >>> ['Korea', 'Univ', 'Engineering', 2019, 2019, 'Engineering', 'Univ', 'Korea']
4️⃣
b = set(a)
print(b) >>> {'Korea', 'Engineering', 'Univ', 2019}다음 딕셔너리에서 가장 큰 key 값과 작은 key 값을 가진 value 를 출력하는 프로그램을 작성하시오.
students = { 50:["Alice",21], 20:['Anna',22], 60:['Michle',21], 10:['Jane',22], 80:['John',20], 30:['Tom',23], 90:['Helen',22] }
#코드 예시
keys1 = list(sorted(students, reverse=True))
key_max = keys1[0]
print(students.get(key_max))
>>> ['Helen', 22]
keys2 = list(sorted(students))
key_min = keys2[0]
print(students.get(key_min))
>>> ['Jane', 22]icecreams = [ ('melon', 1000), ('world', 2000), ('coco', 1200), ('hagan', 2500) ]
1️⃣ 제일 비싼 아이스크림의 이름과 가격 출력
#딕셔너리로 변경
dic1_ice = dict(icecreams)
#가격 출력
value_list = sorted(dic1_ice.values(),
reverse=True)
max_value = value_list[0]
print(max_value)
#이름 출력
dic2_ice = {v:k for k,v in dic1_ice.items()}
max_name = dic2_ice.get(max_value)
print(max_name)2️⃣ 아이스크림 종류만 리스트로 저장 후 출력
dic_ice = dict(icecreams)
name_ice = list(dic_ice.keys())
print(name_ice)3️⃣ 새로운 아이스크림인 'eng', 가격은 1800원 추가 후 출력
dic_ice = dict(icecreams)
new_ice = {'eng':1800}
dic_ice.update(new_ice)
print(dic_ice)