
- kinesis Data Firehose 생성
[경로] Amazon Kinesis → 전송 스트림 → 전송 스트림 생성
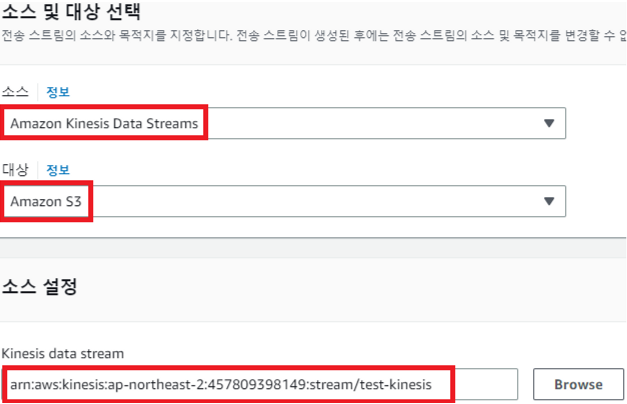
소스 - Amazon Kinesis Data Streams
대상 - Amazon S3 (목적지)
Kinesis Data Stream - test-kinesis

전송 스트림 이름 - wsi-kinesis-firehose
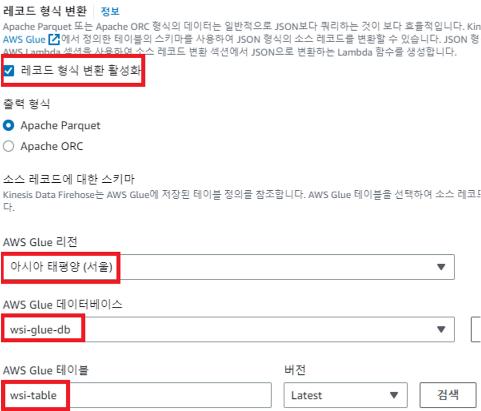
레코드 형식 변환 활성화 (데이터 즉 레코드를 변환해줄 수 있는 구간(Data Firehose의 기능)
AWS Glue 리전 - 아시아 태평양 (서울)
AWS Glue 데이터베이스 - wsi-glue-db
AWS Glue 테이블 - wsi-table
이때 출력 형식을 Output format은 과제기에서 Parquet(파케이), 또는 ORC 형식으로 저장하시오 라고 적혀 있으면 이에 맞춰서 진행하면 된다.
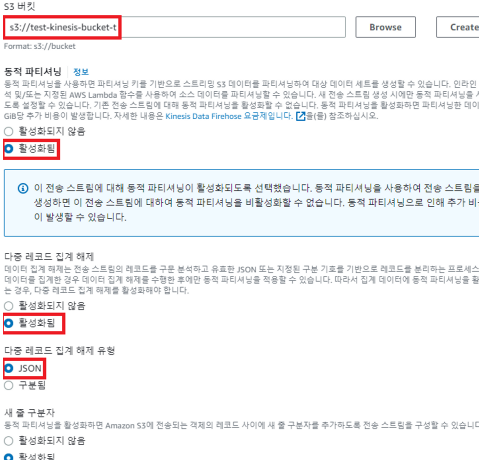
도착지에 대한 설정
s3 버킷 - test-kineiss-bucket-t
동적 파티셔닝 - 활성화 (파티션 키를 기반으로 나눠서 데이터를 저장할 수 있다)
다중 레코드 집계 해제 - 활성화
다중 레코드 집계 해제 유형 - json

JSON을 위한 인라인 구문 분석 - 활성화됨
동적 파티셔닝 키
키 이름 - app_id
JQ 표현식 - .app_id
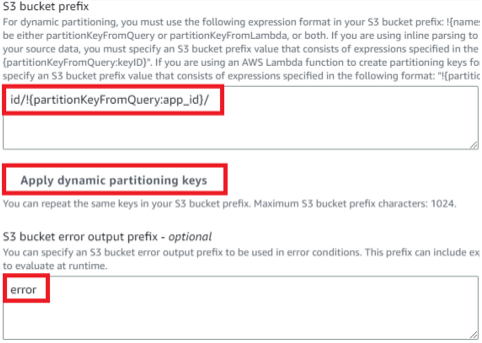
동적 파티셔닝 키 적용 클릭 후 id/붙이기 (s3 파일을 지정할 수 있다 error에 대한 것만 넣어 놓는 것도 있다)
s3 버킷 오류 출력 접두사 - error
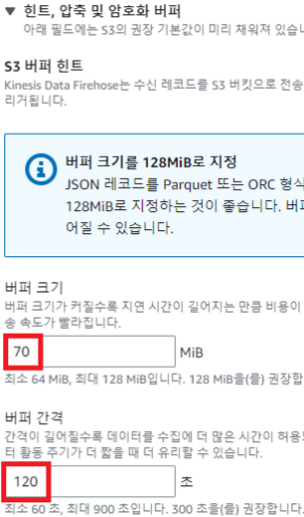
위와 같이 수정해줘야한다. 여기서 Buffer size는 Kinesis Data Firehose의 메모리에 70MiB 이상의 데이터가 쌓이면 데이터를 S3에 전송하도록 하고, 또한 70MiB를 다 사용하지 못하더라고 120초 뒤에 그냥 전송하라는 옵션이다. 그리고 생성한 다음 API를 전송해보자.
이때 3분인데 왜 180초로 안하고 120초로 설정하는지 의문을 가질 수 있다. 왜냐하면 채점 시 3분 타이머를 키고 채점을 진행할 수도 있다. 이때 딱 180초로 설정하면 방대한 데이터가 들어을 때 변환하는데 시간이 걸릴 수 있기에 넉넉하게 1분 감소해서 interval에 추가해준 것이다.
