- Glue crawler 생성
Glue crawler - 모든 종류의 리포지토리(ex) - s3)에서 데이터를 스캔하고 분류하며, 스키마 정보를 추출하고, AWS Glue Data Catalog에서 자동적으로 메타데이터를 저장하는 크롤러를 설정할 수 있습니다
스키마 - 데이터베이스를 구성하는 데이터 개체(Entity), 속성(Attribute), 관계(Relationship) 및 데이터 조작 시 데이터 값들이 갖는 제약 조건 등에 관해 전반적으로 정의한다.
[경로] AWS Glue → Crawlers → Create crawler
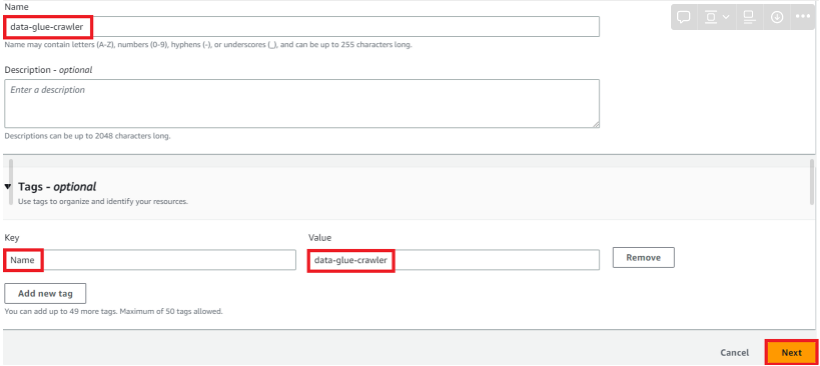
Name - data-glue-crawler
Key - Name
Value - data-glue-crawler
Next 클릭

Add a data soure
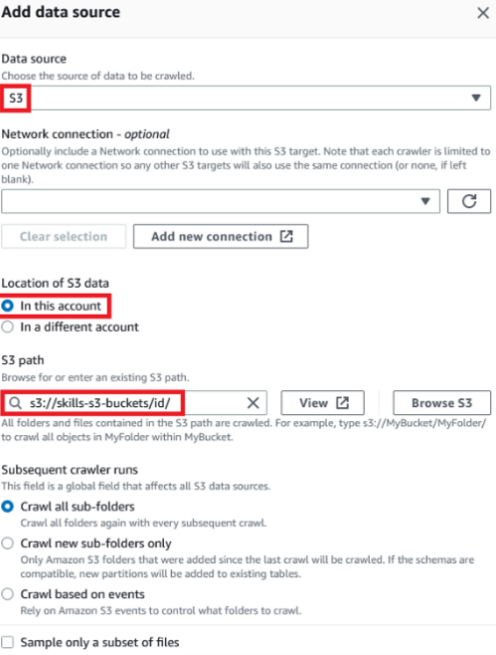
Data soure - S3
S3 path - s3 CRL/id/
S3 경로에 포함된 모든 폴더와 파일이 크롤링됩니다. 예를 들어 s3://MyBucket/MyFolder/를 입력하여 MyBucket 내에서 MyFolder의 모든 객체를 크롤링합니다.
Subsequent crawler runs - Crawl all sub-folders
Add an S3 data source 클릭
크롤링 - 개인 혹은 단체에서 필요한 데이터가 있는 웹(Web)페이지의 구조를 분석하고 파악하여 모두 가져온다

Next 클릭
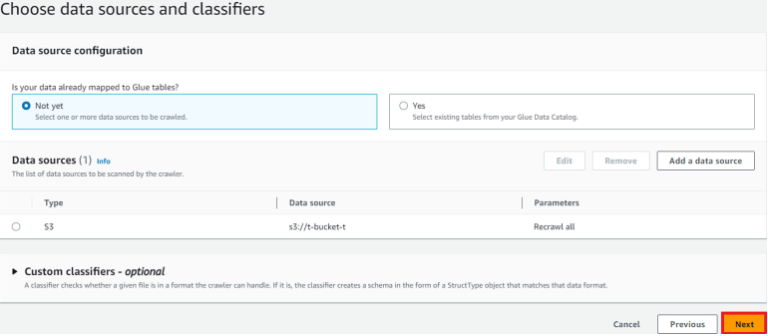
Next 클릭
Enter new IAM role - AWSGlueServiceRole-test
Create 클릭
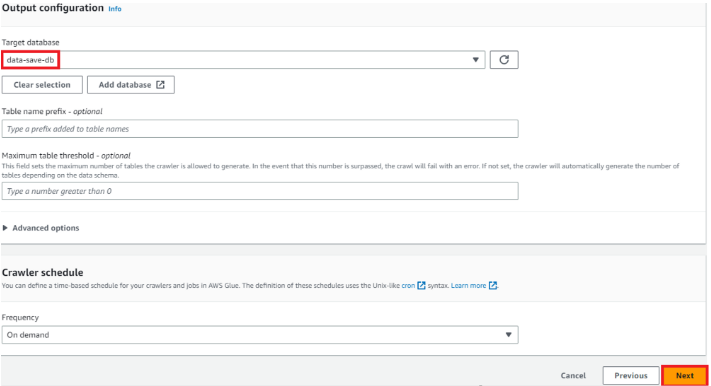
Target database - data-save-db (프로세스 변환에 쓰이는 데이터 저장소)
Next 클릭
Create crawler 클릭
크롤러 실행 클릭
