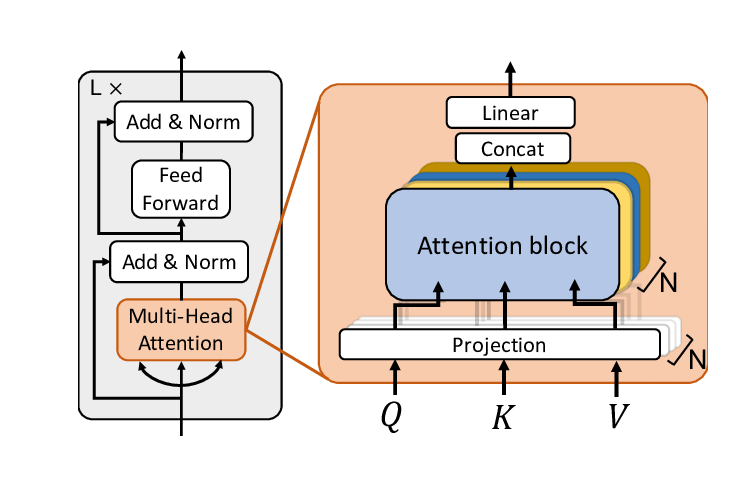
MSA 는 MHA 라고도 불리우는 것 같지만 이 글에서는 MSA 라고 하겠다. 그리고 MSA에 대한 설명을 진행하기 전에, 내 글보다 더 좋은 글을 찾아서 공유하려고한다. Transformer 에 대한 전반적인 설명이 들어가 있는 좋은 글이다. Transformer 파헤치기 - Multi-Head Attention
어찌 되었든 위의 MSA 수식을 이제부터 천천히 풀어가겠다.
Self-Attention for MSA
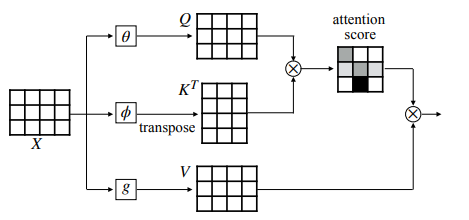
[q,k,v]=zUqkv,Uqkv∈RD×3Dh
A=softmax(Dhq⋅kT),A∈RN×N
SA(z)=A⋅v,A⋅v∈RN×Dh
Dh=kD ( 왼쪽의 k 는 위의 k(key) 가 아니라 attention head 의 개수를 의미한다)
A 는 Attention Score
kT 의 T는 Transpose 는 전치를 의미하며 행으로 늘어선 배열과 열로 늘어선 배열의 내적을 구하기 위함이다.
TMI ) 수학적 표현으로 벡터의 내적은 일(W)를 구하기 위해 사용된다.
SA 는 MSA의 Self-Attention
v 는 Query, Key, Value 에서의 Value(v)
RD×3Dh 에서 D×3Dh
Dh( kD ) 는 헤더들이 수행해야하는 총 수행량이라고 보면 되고, 그 앞의 3은 세 군데(각 q,k,v) 전부에 대한 연산을 해야함 암시한다. 마지막으로 D 는 위에서 언급한 것들이 총 Dimension 에 대해 연산이 수행되어야 함을 의미한다.
q=z⋅wq,wq∈RD×Dh
k=z⋅wk,wk∈RD×Dh
v=z⋅wv,wv∈RD×Dh
[q,k,v]=z⋅Uqkv,Uqkv∈RD×3Dh
softmax(Dhq⋅kT)
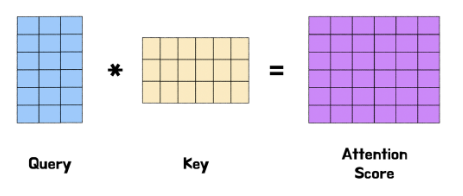
q⋅kT 는 q, kT 두 벡터의 행렬곱이자 "행렬 벡터의 내적" 이다. 또한, 내적( 행렬곱 )을 사용하는 이유는 벡터 행렬간의 유사도를 계산하기 위함이다. 머신러닝에서는 두 벡터의 내적을 통해 유사도를 계산하는 것은 일반화 되어있다( 코사인 유사도와 같이 언급됨 ).
위 이미지를 보면 Key 가 이미 Transpose( 전치 ) 되어 있는 상태로 행렬곱이 되었다. 이는 내적을 계산하려면 두 벡터의 차원이 일치해야 하기 때문이다.
왜 차원이 일치해야하는지, 행렬곱의 특성에 대해 알고있다면 바로 수긍 가능하다.
여기 A와 B라는 행렬이 있다. A와 B 는 각각 아래와 같은 행과 열을 갖는다. A=m×n B=p×n
에서, A×B 는 성립할 수가 없다. 그래서 우리는 B를 전치해서 아래와 같이 만들어 줘야한다.
A=m×n BT=n×p
A×BT=m×p
Dh 로 q⋅kT 내적을 나눠주는 이유는 내적의 결과를 안정적으로 만들기 위함이다. 즉, Dh 는 내적의 결과를 스케일링 해주는 값이다. 이 스케일링을 통해 그라디언트가 과도하게 커지거나 작아지는 것을 방지한다.
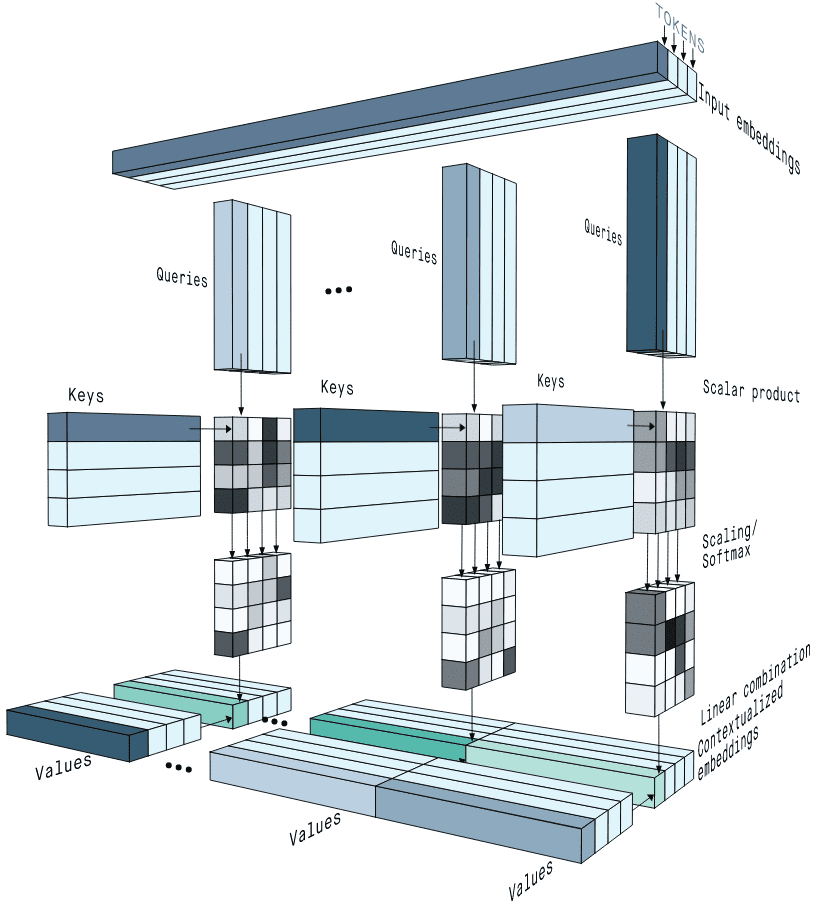
softmax 는 위 연산을 거친 점수들을 확률적으로 변환시킨다. 그리고 output 은 'Attention Weights' 라고도 불리운다. 즉, 각 입력에 대한 출력의 가중치를 의미한다. 이 과정을 거치면 Attention Score 의 유사도는 0 ~ 1사이가 된다.
마지막으로 여기 softmax 를 거쳐서 나온 Attention Score 에 Value(v) 를 곱하면 Self-Attention ( SA ) 이 된다.
MSA 는 Transformer 기반 모든 모델에서 연산량이 가장 많이 요구되는 부분이기도 하다.
MSA 는 'head' 의 개수만큼 독립적인 SA 를 갖고있고, 각각의 head 가 SA 를 병렬로 계산한다. 그러므로, MSA는 여러 'head' 들이 각각 주어진 SA의 Query, Key, Value 행렬을 계산하고, Attention 가중치를 병렬로 계산한다. 그리고, 이 가중치들은 최종적으로 concat 되어서 통합된 인사이트를 제공해준다.
추가로 위 수식 Rk⋅Dh×D 을 덧붙여 말하자면, SA 연산을 수행하면 차원이 줄어든다. 그렇기에 Rk⋅Dh×D 에서 k(head 의개수) 가 곱해진 것이다. 이로써, SA 연산으로 줄어든 차원이 복구된다.