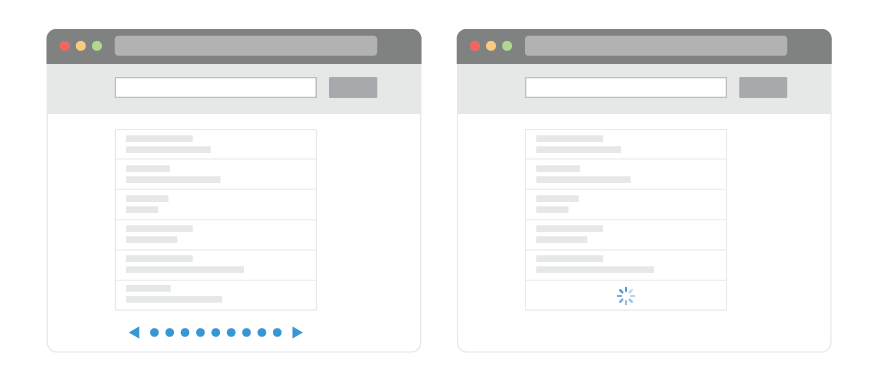
무한스크롤과 페이지네이션
페이지네이션이란?
콘텐츠를 여러 페이지로 나누고, 이전 혹은 다음 페이지로 넘어가거나 특정 페이지로 넘어갈 수 있는 링크를 페이지 상단이나 하단에 배치하는 방법
쇼핑몰 하단, 검색 결과 하단에서 익숙하게 찾아보실 수 있습니다.
무한스크롤이란?
브라우저 또는 스마트폰에서 스크롤 막대가 하단에 도달하는 것을 방지하는 것을 말합니다. 사용자가 페이지를 더 아래로 스크롤 할 때마다 새로운 콘텐츠가 추가됩니다.
인스타그램 피드, 쇼핑몰 상품 리스트를 아래로 스크롤하다 보면 잠깐의 로딩을 거치고 컨텐츠가 추가되는 경험을 하신적 있죠?! 무한스크롤을 적용한 경우입니다.
커서 기반이 뭔데? 🧐
흔히 무한 스크롤을 구현할 때 두 가지 방법을 사용합니다.
1. 오프셋 기반 페이지네이션
2. 커서 기반 페이지네이션
오프셋 기반 페이지네이션은 MySQL 기준으로 offset, limit 을 사용한 쿼리를 이용합니다.
하지만 이는 성능 저하 문제가 있는데, 바로 offset 값이 클 때 문제가 발생합니다.
select * from item
order by created_at desc
limit 10
offset 100000000;위와 같은 쿼리의 경우 offset 값이 1억이기 때문에 앞의 1억개의 데이터를 모두 읽은 뒤에,
다음 10개의 데이터를 조회하여 응답합니다.
이는 뒤로 갈수록 읽어야 하는 데이터가 많아진다는 걸 뜻하고 점점 느려질 수 밖에 없습니다.
커서 기반 페이지네이션은 이러한 문제점을 해결해줍니다.
커서 기반 페이지네이션
- Cursor 개념을 사용합니다.
- 사용자에게 응답해준 마지막 데이터의 식별자 값을 Cursor로 사용합니다.
예를 들어보겠습니다.
# 1 페이지
select * from item
order by id asc
limit 10;
# 2 페이지
select * from item
where id > 10 # 1 페이지 조회 결과 cursor 값이 10
order by id asc
limit 10;1 페이지의 요청으로 조회된 item 들의 id 는 1 ~ 10 입니다.
이 때 마지막 식별자인 id 10이 cursor가 되고 이를 다음 페이지 요청 시 사용합니다.
오프셋 기반 페이지네이션과 비교해보면 마지막으로 읽은 데이터 (id 10) 의 다음 데이터 (id 11) 부터 10개를 조회하기 때문에 매번 원하는 데이터 개수만큼만 조회한다는 이점이 있습니다.
커서 기반 무한스크롤 구현
이제 Spring 으로 무한스크롤을 구현해보겠습니다.
스크롤 페이지네이션을 편리하게 구현하기 위한 클래스입니다.
@RequiredArgsConstructor(access = AccessLevel.PRIVATE)
public class ScrollPaginationCollection<T> {
private final List<T> itemsWithNextCursor; // 현재 스크롤의 요소 + 다음 스크롤의 요소 1개 (다음 스크롤이 있는지 확인을 위한)
private final int countPerScroll;
public static <T> ScrollPaginationCollection<T> of(List<T> itemsWithNextCursor, int size) {
return new ScrollPaginationCollection<>(itemsWithNextCursor, size);
}
public boolean isLastScroll() {
return this.itemsWithNextCursor.size() <= countPerScroll;
}
public List<T> getCurrentScrollItems() {
if (isLastScroll()) {
return this.itemsWithNextCursor;
}
return this.itemsWithNextCursor.subList(0, countPerScroll);
}
public T getNextCursor() {
return itemsWithNextCursor.get(countPerScroll - 1);
}
}List<T> itemsWithNextCursor: 현재 스크롤의 데이터 + 다음 스크롤의 데이터 1개
다음 스크롤이 있는지 확인하기 위해 다음 스크롤의 요소 1개를 더 포함합니다.int countPerScroll: 스크롤 1회에 조회할 데이터의 개수입니다.boolean isLastScroll(): 현재 스크롤이 마지막 스크롤인지 확인하기 위한 메소드입니다.
쿼리로 데이터를 조회한 결과countPerScroll의 숫자 이하로 조회되면 마지막 스크롤이라고 판단합니다.List<T> getCurrentScrollItems(): 마지막 스크롤일 경우itemsWithNextCursor를 return 하고
마지막 스크롤이 아닐 경우 다음 스크롤의 데이터 1개를 제외하고 return 합니다.T getNextCursor(): 현재 스크롤의 데이터 중 마지막 데이터를 cursor로 사용하고 이를 return 합니다.
실제 서비스 로직에서
ScrollPaginationCollection<T>클래스를 사용한 예시입니다.
public GetFeedsResponse getFeeds(String userEmail, Long roomId, int size, Long lastFeedId) {
User user = FeedServiceUtils.findUserByEmail(userRepository, userEmail);
Room room = FeedServiceUtils.findRoomByRoomId(roomRepository, roomId);
PageRequest pageRequest = PageRequest.of(0, size + 1);
Page<Feed> page = feedRepository.findAllByRoomAndIdLessThanOrderByIdDesc(room, lastFeedId, pageRequest);
List<Feed> feeds = page.getContent();
ScrollPaginationCollection<Feed> feedsCursor = ScrollPaginationCollection.of(feeds, size);
GetFeedsResponse response = GetFeedsResponse.of(feedsCursor, FeedImageCollection.of(feeds, feedImageRepository), feedRepository.countAllByRoom(room));
return response;
}현재 서비스 로직에서 String userEmail, Long roomId, int size, Long lastFeedId 를 인자로 받고 있는데 여기서 int size, Long lastFeedId 에 집중해야 합니다.
int size: 스크롤 1회에 조회할 데이터의 개수Long lastFeedId: 커서로 사용하는 데이터 식별자입니다.
id 내림차순으로 데이터를 조회하기 때문에 다음 스크롤은lastFeedId보다 작은 id의 데이터만 확인합니다.
다음은 Page<T> 인터페이스, Pageable 인터페이스, PageRequest 클래스에 대한 이해가 필요합니다.
Page<T>인터페이스는 페이지 정보를 담습니다.Pageable인터페이스는 페이지 처리에 필요한 정보를 담고 있습니다.PageRequest클래스는Pageable의 정보가 담겨 객체화 된 클래스입니다.
JpaRepository 가 상속된 인터페이스의 파라미터로 PageRequest 를 전달하면 Page<T> 를 return 합니다.
다시 getFeeds 메소드를 살펴봅시다.
PageRequest pageRequest = PageRequest.of(0, size + 1):PageRequest객체의of메소드는 인자로 조회할page와 한 페이지당 조회할 데이터의 개수size를 받습니다. 커서 기반 페이지네이션이기 때문에 항상lastFeedId이후의id로만 조회하므로 첫번째 페이지의 정보를 받으면 됩니다.size에는 다음 스크롤이 있는지 판단하기 위해 다음 스크롤의 요소 1개를 포함한size + 1을 입력합니다.Page<Feed> page = feedRepository.findAllByRoomAndIdLessThanOrderByIdDesc(room, lastFeedId, pageRequest):JpaRepository를 상속한feedRepository에 파라미터로 커서로 사용하는lastFeedId와PageRequest를 담아서 데이터를 조회합니다.List<Feed> feeds = page.getContent():Page<T>가 제공하는getContent메소드로 조회한 데이터를 가져옵니다.
클라이언트에게 전달할 dto인
GetFeedsResponse클래스입니다.
@ToString
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class GetFeedsResponse {
private static final long LAST_CURSOR = -1L;
private List<FeedsInfoResponse> contents = new ArrayList<>();
private long totalElements;
private long nextCursor;
private GetFeedsResponse(List<FeedsInfoResponse> contents, long totalElements, long nextCursor) {
this.contents = contents;
this.totalElements = totalElements;
this.nextCursor = nextCursor;
}
public static GetFeedsResponse of(ScrollPaginationCollection<Feed> feedsScroll, FeedImageCollection feedImages, long totalElements) {
if (feedsScroll.isLastScroll()) {
return GetFeedsResponse.newLastScroll(feedsScroll.getCurrentScrollItems(), feedImages, totalElements);
}
return GetFeedsResponse.newScrollHasNext(feedsScroll.getCurrentScrollItems(), feedImages, totalElements, feedsScroll.getNextCursor().getId());
}
private static GetFeedsResponse newLastScroll(List<Feed> feedsScroll, FeedImageCollection feedImages, long totalElements) {
return newScrollHasNext(feedsScroll, feedImages, totalElements, LAST_CURSOR);
}
private static GetFeedsResponse newScrollHasNext(List<Feed> feedsScroll, FeedImageCollection feedImages, long totalElements, long nextCursor) {
return new GetFeedsResponse(getContents(feedsScroll, feedImages), totalElements, nextCursor);
}
private static List<FeedsInfoResponse> getContents(List<Feed> feedsScroll, FeedImageCollection feedImages) {
return feedsScroll.stream()
.map(feed -> FeedsInfoResponse.of(feed, feedImages.getImagesByFeedId(feed.getId())))
.collect(Collectors.toList());
}
}List<FeedsInfoResponse> contents: 클라이언트에게 최종적으로 전달될 데이터들입니다.
FeedsInfoResponse는 서비스 로직에서 조회한Feed를 가공한 형태입니다.long totalElements: 조회 가능한 데이터의 총 개수입니다.long nextCursor: 다음 스크롤에서 사용할 커서의 값입니다.long LAST_CURSOR = -1L: 다음 스크롤이 존재하지 않을 경우nextCursor에 넣어주기 위한 값입니다.
nextCursor = -1L일 경우 해당 스크롤이 마지막 스크롤임을 뜻합니다.List<FeedsInfoResponse> getContents(List<Feed> feedsScroll, FeedImageCollection feedImages):contents로 전달할 데이터로 가공하기 위한 메소드입니다.GetFeedsResponse newScrollHasNext(List<Feed> feedsScroll, FeedImageCollection feedImages, long totalElements, long nextCursor): 다음 스크롤이 존재하는 경우nextCursor에 다음 커서 값을 담아서 객체를 생성하기 위한 메소드입니다.GetFeedsResponse newLastScroll(List<Feed> feedsScroll, FeedImageCollection feedImages, long totalElements): 다음 스크롤이 존재하지 않을 경우nextCursor에-1L을 담아서 객체를 생성하기 위한 메소드입니다.GetFeedsResponse of(ScrollPaginationCollection<Feed> feedsScroll, FeedImageCollection feedImages, long totalElements): 서비스 로직에서는 해당 메소드를 사용해서 조회한 데이터를 클라이언트에게 전달할 데이터로 가공합니다.ScrollPaginationCollection클래스의isLastScroll메소드를 사용해서 해당 스크롤이 마지막 스크롤인지 확인합니다. 이후에 마지막 스크롤인지 여부에 따라newLastScroll또는newScrollHasNext메소드를 호출합니다.
마지막으로 getFeeds 메소드로 돌아가서 마무리 해보겠습니다.
ScrollPaginationCollection<Feed> feedsCursor = ScrollPaginationCollection.of(feeds, size): 위에서 소개한ScrollPaginationCollection<T>클래스의of메소드의 인자로ScrollPaginationCollection객체를 생성합니다.GetFeedsResponse response = GetFeedsResponse.of(feedsCursor, FeedImageCollection.of(feeds, feedImageRepository), feedRepository.countAllByRoom(room)): 클라이언트측에 전달할 Response 형식으로 변환해준 뒤 이를 return 합니다.
실제 Response 확인
스크롤 페이지네이션 최초 요청의 cursor 값으로는 long 의 최댓값인 9223372036854775807 를 담아서 요청합니다.
GET localhost:8080/v1/feed?roomId=1&size=1&lastFeedId=9223372036854775807
{
"status": 200,
"message": "OK",
"data": {
"contents": [
{
"createdAt": 1662647379,
"updatedAt": 1662647379,
"feedId": 20,
"userId": 1,
"title": "title",
"content": "content",
"imageUrls": [
"image.png"
]
}
],
"totalElements": 20,
"nextCursor": 20
}
}그러면 위와 같이 data 에 GetFeedsResponse 형태로 가공된 데이터를 확인할 수 있습니다.
다음 요청으로는 lastFeedId 에 nextCursor 값인 20 을 담아서 요청합니다.
GET localhost:8080/v1/feed?roomId=1&size=1&lastFeedId=20
{
"status": 200,
"message": "OK",
"data": {
"contents": [
{
"createdAt": 1662647378,
"updatedAt": 1662647378,
"feedId": 19,
"userId": 1,
"title": "title",
"content": "content",
"imageUrls": [
"image.png"
]
}
],
"totalElements": 20,
"nextCursor": 19
}
}cursor 값으로 입력했던 20보다 작은 id 중 1개를 조회했기 때문에 feedId 가 19 인 데이터가 조회된 모습을 확인할 수 있습니다.
마지막 요소가 id = 1 이기 때문에 lastFeedId 에 2를 담아서 요청을 보내보겠습니다.
GET localhost:8080/v1/feed?roomId=1&size=1&lastFeedId=2
{
"status": 200,
"message": "OK",
"data": {
"contents": [
{
"createdAt": 1662647366,
"updatedAt": 1662647366,
"feedId": 1,
"userId": 1,
"title": "title",
"content": "content",
"imageUrls": [
"image.png"
]
}
],
"totalElements": 20,
"nextCursor": -1
}
}더 이상 조회할 데이터가 남지 않았기 때문에 다음과 같이 nextCursor 에 -1 이 담긴 모습을 확인할 수 있습니다.
주의사항
위에서 소개한 방법은 커서로 데이터의 id 값을 사용했습니다. MySQL 기준으로 id 에 auto increment 옵션을 주면 데이터가 생성될 때마다 id 값이 1씩 증가하기 때문에 위와 같은 방법으로 데이터를 조회하면 데이터는 최신순으로 조회됩니다.
❗️ 하지만 다른 조건으로 데이터를 정렬해서 무한스크롤로 조회한다면 어떻게 될까?
아래와 같은 테이블이 있다고 가정해보겠습니다.
| id | index |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 1 |
id 가 아닌 index 기준 내림차순으로 정렬하면 다음과 같은 순서가 됩니다.
| id | index |
|---|---|
| 3 | 4 |
| 2 | 3 |
| 1 | 2 |
| 4 | 1 |
최초 커서 값으로 lastFeedId = 9223372036854775807 를 담아서 요청을 보내게 되면
첫번째 순서인 id 3 이 아니라 id 4 가 조회됩니다.
위와 같은 이유로 커서 기반 페이지네이션을 활용하려면 조건에 맞는 커서 선정이 중요합니다.
커서 선정이 어렵다면 성능은 커서 기반 페이지네이션보다 떨어지지만 위에서 언급했던
오프셋 기반 페이지네이션을 활용하면 쉽게 구현할 수 있습니다.
다음 글에서는 오프셋 기반 페이지네이션을 활용하는 방법에 대해 다뤄보겠습니다.
