파일 관리 테이블을 설계하면서 느낀 점을 정리해보았다.
최종적으로는 위와 같은 구조를 가지게 될 것인데,
이러한 구조를 가질때까지의 변화를 순차적으로 정리해본다.
Type A
최초의 파일 테이블 구조는 아래와 같다.
file table
| file_id | file_name |
|---|---|
| 1 | myFile.jpg |
| 2 | myFile.png |
| 3 | myFile.bmp |
가장 단순한만큼 여러 문제점을 내포하고 있다.
만일 여러 업로더가 같은 이름의 파일을 올리고자 한다면 문제가 발생할 것이다.
이 문제점을 개선해보자.
Type B
file table
| file_id | org_name | cvt_name |
|---|---|---|
| 1 | myFile.jpg | 550e8400-e29b-41d4-a716-446655440000.jpg |
| 2 | myFile.jpg | 280a8a4d-a27f-4d01-b031-2a003cc4c039.jpg |
| 3 | myFile.jpg | 35f86ed0-c7ef-11eb-bf10-b42e99073dab.jpg |
이런식으로 원본 파일명을 보관하되 실제로 저장하기 위해 변환시킨 파일명도 함께 보관하는 구조로 할 수 있다.
이런식으로 작성된 이유는 중복될 가능성이 거의 없는 UUID로 파일명을 변환하여, 원본 파일명이 중복되더라도 업로드가 가능하도록 만들기 위함이다. (때문에 기본적으로 원본파일의 중복을 허용한다.)
이러한 방식은 각 파일이 계층구조를 이루지 않고 단일 디렉토리 내에서 모든 파일이 관리될 때 적합하다. 대표적으로 썸네일용 이미지 관리 등이 있을 것이다.
Type C
file table
| file_id | path | name |
|---|---|---|
| 1 | / | myFile.jpg |
| 2 | /myFolder/ | myFile.jpg |
| 3 | /myFolder/innerFoler/ | myFile.jpg |
이제는 path 컬럼이 추가되면서 경로를 표현할 수 있도록 하였다.
이 버전부터는 중복 업로드를 백엔드단에서 신경써서 처리해야한다.
INSERT 하기 전에 SELECT 하여 (path와 file_name 이 동시에)중복이 있다면 덮어쓸(delete 후 insert 할)지, 쓰지 않고 무시(업로드를 안)할지 결정해야 한다.
대신에 경로(path)만 다르다면, 중복파일을 허용한다.
지금까지 알아본 Type A 와 B 의 방식은 file 을 포현하기에는 적절하지만 folder 를 표현하기에는 적절하지 않다.
자식 파일을 갖고 있지 않은, 빈 폴더를 구현할 방법이 없다.
Type D
folder table
| file_id | path | name |
|---|---|---|
| 1 | / | myFolder |
| 2 | /myFolder/ | innerFoler |
| 2 | /myFolder/ | emptyFoler |
file table
| file_id | path | name |
|---|---|---|
| 1 | / | myFile.jpg |
| 2 | /myFolder/ | myFile.jpg |
| 3 | /myFolder/innerFoler/ | myFile.jpg |
별도의 folder 테이블을 추가하면서 빈 폴더를 구현할 수 있게 되었다.
그러나 이 방식에도 여전히 한가지 아쉬운 부분이 있다.
바로 path 컬럼 내에 중복 정보를 갖고 있다는 점이다.
여기서 나는 파일이 소속된 폴더를 절대경로가 아닌, 상대경로와 같은 방식으로 표현하고 싶었다.
Type E
folder 테이블
| folder_id | name | parent_folder_id |
|---|---|---|
| 1 | myFolder | null |
| 2 | innerFoler | 1 |
| 2 | emptyFoler | 1 |
file 테이블
| file_id | name | folder_id |
|---|---|---|
| 1 | myFile.jpg | null |
| 2 | myFile.jpg | 1 |
| 2 | myFile.jpg | 2 |
file 테이블에서 path 컬럼 대체할 목적으로 folder_id 컬럼을 추가하였다.
또한 folder 테이블은 parent_folder_id 테이블을 외래키로 갖고, 부모 폴더를 표현할 수 있다.
parent_folder_id 폴더가 null 이면 부모 폴더가 root 폴더임을 표현하는 방식이다.
또한 이러한 방식은 부모/자식 간의 계층 이동 및 조회에 장점을 가지고 있다.
그러나 folder 테이블과 file 의 구조가 동일함을 알 수 있다.
리눅스 커널 시스템에서 폴더는 일종의 파일이다.
즉, 파일의 특수화된 케이스 중 하나이다.
다른 예로는 소켓과 장치-device 도 파일로 관리한다.
실제로 아래 명령어를 실행하면 에러가 발생한다.
touch myFolder
mkdir myFolder
mkdir: myFolder: File exists먼저 myFolder 라는 빈 파일을 생성했다.
그리고 같은 이름의 폴더의 생성을 시도했으나 이미 파일이 존재한다며 실패했다.
즉, 폴더 또한 일종의 파일이라는 점을 확인할 수 있다.
정말 폴더가 파일이라면 하나의 파일시스템 테이블로 표현해보자.
Type F
filesystem 테이블
| filesystem_id | name | parent_id |
|---|---|---|
| 1 | proc | null |
| 2 | 8935 | 1 |
| 3 | fd | 2 |
| 4 | mySocket | 3 |
| 5 | dev | null |
| 6 | by-id | 5 |
| 7 | ata-ST4000DM004 | 6 |
| 8 | myFolder | null |
| 9 | innerFoler | 1 |
| 10 | myFile.jpg | 8 |
| 11 | myFile.jpg | 9 |
사실 위의 구조도 여전히 문제가 있다.
만약에 폴더 이름이 'myFile.jpg'라면?
만약에 파일 이름이 확장자가 없는, 'myFolder'라면?
또한 아무리 폴더가 일종의 파일이라지만 두 요소는 엄연히 별개의 역할을 갖고 있고 이 두 요소를 구분할 수 있어야 한다.
Type G
filesystem 테이블
| filesystem_id | name | type | parent_id |
|---|---|---|---|
| 1 | proc | dir | null |
| 2 | 8935 | dir | 1 |
| 3 | fd | dir | 2 |
| 4 | mySocket | socket | 3 |
| 5 | dev | dir | null |
| 6 | by-id | dir | 5 |
| 7 | ata-ST4000DM004 | device | 6 |
| 8 | myFolder | dir | null |
| 9 | innerFoler | dir | 1 |
| 10 | myFile.jpg | file | 8 |
| 11 | myFile.jpg | file | 9 |
여기까지 하면 구조적으로는 이상적인 것처럼 보인다.
그러나 실제 백엔드 서비스에서 어려움이 있다.
특정 경로의 파일을 표현하기 위해서는 folder 테이블을 여러번 self join 하고 마지막으로 file 테이블과 join 하면서 성능상의 이슈가 될 수 있다.
하여 기존의 절대경로까지 포함시켜 표현할 수 있다.
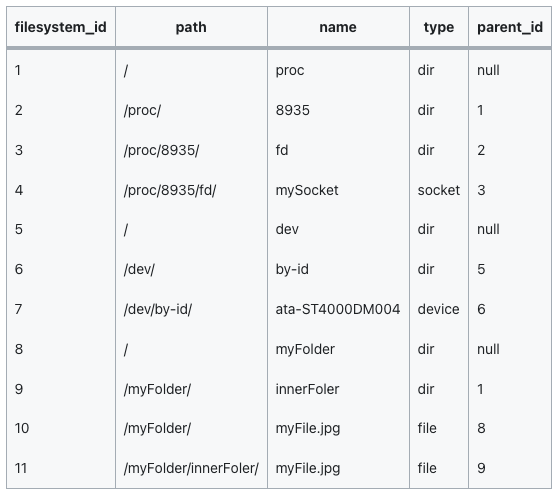
Type H
| filesystem_id | path | name | type | parent_id |
|---|---|---|---|---|
| 1 | / | proc | dir | null |
| 2 | /proc/ | 8935 | dir | 1 |
| 3 | /proc/8935/ | fd | dir | 2 |
| 4 | /proc/8935/fd/ | mySocket | socket | 3 |
| 5 | / | dev | dir | null |
| 6 | /dev/ | by-id | dir | 5 |
| 7 | /dev/by-id/ | ata-ST4000DM004 | device | 6 |
| 8 | / | myFolder | dir | null |
| 9 | /myFolder/ | innerFoler | dir | 1 |
| 10 | /myFolder/ | myFile.jpg | file | 8 |
| 11 | /myFolder/innerFoler/ | myFile.jpg | file | 9 |
path를 생성하는 시간에 대한 성능 최적화를 위해 결국에 다시 path 컬럼을 추가하였다.
이로써 절대경로에 대한 조회와 상대경로에 대한 조회를 모두 빠르게 할 수 있게 되었다.
경로 정보에 대한 데이터 중복이 발생하였으나 공간과 속도의 Trade off이므로 신중한 선택이 요구된다.
사실 가장 신경써야 할 부분은 path의 정보와 parent_folder의 name의 정합성이 유지되어야 한다는 것이다. 이 정합성을 유지하기 위한 비용까지 고려해서 도입에 더더욱 신중을 기해야 한다.

공감하며 읽었습니다. 좋은 글 감사드립니다.