몇몇 영상 처리 분야는 20Mpx(2천만화소) 이상의 고해상도 이미지를 다루게 된다. 이는 픽셀 단위의 순회가 필요할 경우 2천만회의 반복이 필요하다는 의미이다. (실제로는 RoI 를 사용하지만, 때때로 이미지 전역을 대상으로 검사가 필요한 경우도 있다.)
이에 더해 필터(or 마스크)라도 적용한다면 NxN배 반복문이 증가하게 된다.
24M(6K x 4K) 해상도의 이미지에 5x5 사이즈의 필터를 예시로 들자면 '6k x 4k x 5 x 5 = 6억'이라는 막대한 반복문을 순회하게 된다.
때문에 이러한 반복문 순회시간을 단축시키기 위해 멀티스레드를 도입하여 소요시간 단축을 기대할 수 있다.
(GPGPU를 활용하는 등 영상처리를 가속화 시키기 위한 다른 방법도 많지만 본 포스트에서는 CPU만으로 처리하는 경우를 다룬다.)
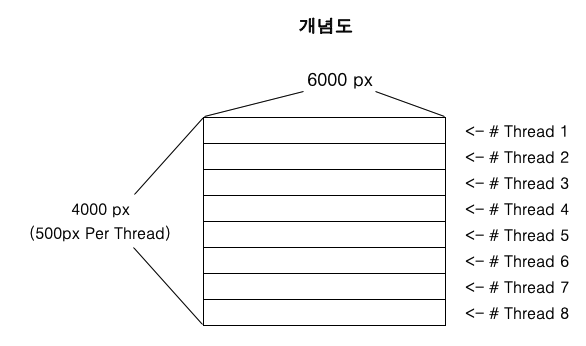
기본적인 개념은 위 사진과 같이 이미지의 행을 스레드 수만큼 슬라이스하여 분산처리한다.
그러나 실제로 이미지를 슬라이스 할 필요는 없고 이미지의 각 행을 스레드 수만큼 건너뛰면서 처리하되, 각 스레드에 시작 인덱스를 전달하여 순회를 시작하는 것으로 구현할 수 있다.
아래는 이번에 사용할 예제 이미지이다.

먼저 C++ 표준의 thread 라이브러리를 include 하여 하드웨어 스레드의 개수를 반환받는다.
#include <thread>
const int TOTAL_THREAD = std::thread::hardware_concurrency();그리고 전달받은 이미지를 픽셀단위로 순회한다.
순회하는 최상위 반복문의 초기식과 증감식이 핵심인데, thread의 순서대로 0부터 n-1을 초기식으로 주고 thread 수량만큼 가산하며 대입연산을 진행하는 방식이다.
#include <opencv2/opencv.hpp>
void distFilter(const cv::Mat &srcImage, cv::Mat *dstImage, int blockSize, int index)
{
// 이 반복문이 핵심
for (int i = index; i < srcImage.rows; i += TOTAL_THREAD)
{
// 이하의 나머지 코드는 단일스레드로 동작하는 코드와 동일하다.
for (int j = 0; j < srcImage.cols; j++)
{
int sum = 0;
int count = 0;
for (int di = -blockSize / 2; di <= blockSize / 2; di++)
{
for (int dj = -blockSize / 2; dj <= blockSize / 2; dj++)
{
int ni = i + di; // 이미지 픽셀 좌표 ± 필터 좌표
int nj = j + dj; // 이미지 픽셀 좌표 ± 필터 좌표
if (ni < 0 || ni >= srcImage.rows || nj < 0 || nj >= srcImage.cols)
continue; // 이미지 영역을 벗어나면 skip
// 필터 중심의 값과 필터 영역 내의 값의 차를 절대값으로 합산한다.
sum += abs(srcImage.at<uchar>(i, j) - srcImage.at<uchar>(ni, nj));
count++;
}
}
// 합산된 차이값을 평균내어 픽셀의 밝기값으로 사용한다.
dstImage->at<uchar>(i, j) = sum / count;
}
}
}위에서 사용한 distFilter는 특정 좌표의 픽셀이, 인근 영역(=필터 사이즈)과의 대비가 얼마나 강한지를 구하는 필터이다.
때문에 어느정도의 그라데이션에는 내성을 갖게 되고, 급격한 밝기 변화가 존재하는 픽셀은 높은 값을 갖게 된다. (절댓값을 취했기 때문)
실제로 distFilter를 호출하는 메인함수는 아래와 같다.
#include <iostream>
int main()
{
cv::Mat image = cv::imread("defect.png", cv::IMREAD_GRAYSCALE);
// 유효성 검사
if (image.empty())
return -1;
cv::Mat dstImage;
image.copyTo(dstImage);
// 실제 업무 코드는 스레드 풀을 사용해야겠지만 예제는 간략화를 위해 vector 사용
std::vector<std::thread> worker;
int blockSize = 3;
// 시간 측정을 위한 함수 호출
auto startTime = std::chrono::high_resolution_clock::now();
for (int index = 0; index < TOTAL_THREAD; index++)
worker.push_back(std::thread(distFilter, image, &dstImage, blockSize, index));
for (int index = 0; index < TOTAL_THREAD; index++)
worker[index].join();
auto endTime = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(endTime - startTime).count();
std::cout << "process time : " << duration << " milliseconds" << std::endl;
cv::imwrite("result.png", dstImage);
return 0;
}TOTAL_THREAD 의 수만큼 스레드를 생성하여 worker vector 에 push 하고 이후 join 하여 스레드 종료까지 대기한다.
마지막으로 종료 시간을 측정하여 소요시간을 구한다.
이렇게 생성된 이미지는 아래와 같다.

좌상단과 우상단의 스크래치와 달리 우하단의 스크래치는 육안으로 선명해 보이지 않는다.
이는 우하단의 스크래치 내부의, 인접 픽셀들의 밝기 대비가 0 이기 때문에 검은색으로 채워졌기 때문이다.
이를 개선하기 위해서는 필터 사이즈를 키우거나 blob 의 내부를 밝은색으로 채우는 것으로 해결할 수 있다.
또한 수식에서 abs() 함수가 아닌, pow() 함수를 사용하여 sum 값을 크게 얻어내는 방법으로 밝기를 증폭시킬 수 있으나 overflow 에는 유의해야 한다.
스레드 수와 필터 크기별 소요시간은 아래와 같았다.
-
3x3 사이즈 필터 사용
반복문 수행 횟수 약 2.16억회
1스레드 소요시간 1546ms
4스레드 소요시간 429ms
8스레드 소요시간 363ms -
5x5 사이즈 필터 사용
반복문 수행 횟수 약 6억회
1스레드 소요시간 3571ms
4스레드 소요시간 960ms
8스레드 소요시간 831ms
이와 같이 4스레드까진 유의미한 소요시간 감소가 있었으나, 8스레드는 그렇지 못한 이유는
애플 맥 M1 제품의 CPU를 기준으로
4코어 Apple Firestorm 3.2 GHz + 4코어 Apple Icestorm 2.06 GHz
와 같은 bigbig.LITTLE 아키텍쳐를 사용하기 때문이다.
인텔의 X86 아키텍쳐는 Hyper-Threading 기술로 물리 코어 대비 논리 스레드를 2배로 동작하는 기술이 있기 때문에 애플 칩셋의 경우와 비슷하게 전체 스레드의 절반까지만 쓰는것이 스윗스팟일 수 있다.
