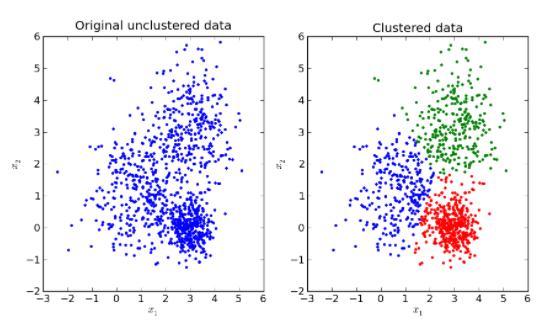
비지도 학습은 지도학습과 다르게 훈련데이터에 정답(label)이 없는 학습방법이다.
그래서 클러스터링 기법을 사용해서 데이터가 유사한 것 끼리 묶어준다.
클러스터링이란 명확한 분류 기준이 없는 상황에서 데이터를 분석하여 유사한 것 끼리 묶어주는 작업이다.
1. K-Means
클러스터링의 대표적인 알고리즘이다.
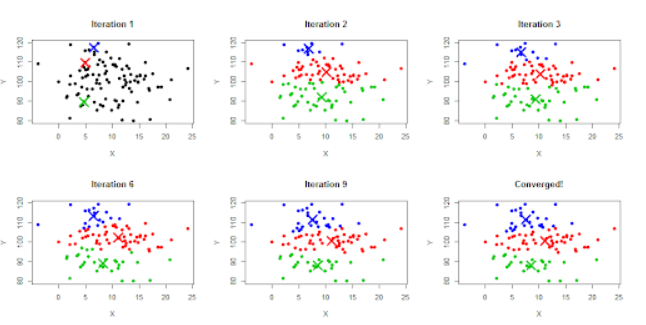
1) 알고리즘 동작 순서
- 원하는 클러스터의 수 (K)를 정한다.
- 무작위로 K개의 중심점을 선정한다.
- 중심점과 점으로 된 데이터간의 l2거리를 계산한 후 가장 가까운 거리를 가지는 중심점의 클러스터에 속하도록 한다.
- k개의 클러스터의 중심점으 재조정한다. 특정 클러스터에 속하는 모든 점들의 평균값이 해당 클러스터의 다음 iteration 의 중심점이 된다.
- 재조정된 중심점을 바탕으로 3-4번 과정을 반복한다.
- 반복 횟수는 사용자가 조절하면되고 특정 iteration이상이 되면 중심점이 더이상 바뀌지않게한다.
2)k-means 알고리즘이 잘 동작하지 않는 예시
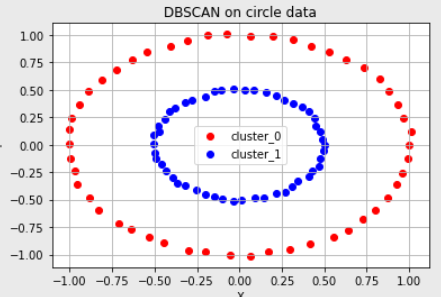
- 원형 분포

- 달 모양 분포

- 대각선 모양 분포
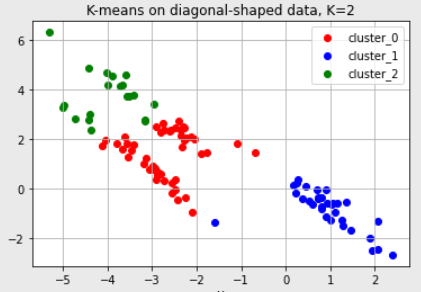
3) k-means 알고리즘 단점
-
k값을 미리 지정해야하므로 이를 알거나 예측하기 어려운 경우 사용하기 어렵다.
-
l2거리가 가까운 데이터끼리 클러스터링이 이루어지기때문에 데이터의 분포에 따라 l2거리가 멀면서 밀접하게 연관되어있는 데이터들은 클러스터링을 하기 힘들다.
2. DBSCAN
또 다른 클러스터링의 알고리즘이다. K-means 알고리즘을 사용해 해결하기 어려웠던 문제들을 DBSCAN 알고리즘을 활용해 해결할 수 있다. DBSCAN 알고리즘은 클러스터링 할 개수 K값을 미리 지정할 필요가 없다. 또 l2 거리 기반으로 클러스터링 하는 것이 아닌 조밀하게 몰려 있는 클러스터를 군집화하는 방식이다. 그래서 불특정한 형태의 군집도 찾을 수 있다.
[DBSCAN 클러스터링 방식](DBSCAN - primo.ai)
1) 알고리즘 동작 순서
알고리즘을 보기전에 변수 및 용어를 알아보자
- epsilon : 클러스터의 반경
- minPts : 클러스터를 이루는 개체의 최솟값
- core point : 반경 epsilon내에 minPts개 이상의 점이 존재하는 중심점
- border point : 군집의 중심이 되지는 못하지만, 군집에 속하는 점
- noise point : 군집에 포함되지 못하는 점
- 임의의 점 p를 설정하고, p를 포함하여 주어진 epsilon안에 포함되어있는 점들의 개수를 센다.
- 만약 해당 원에 minPts개 이상의 점이 포함되어있으면, 해당 점p를 core point로 간주하고 원에 포함된 점들을 하나의 클러스터로 묶는다.
3.해당 원에 minPts개 미만의 점이 포함되어있으면, 일단 pass한다. - 모든 점에 대해 돌아가면서 1~3 번의 과정을 반복하는데, 만약 새로운 점 p'가 core point가 되고, 이 점이 p를 core point로 하는 클러스터에 속한다면 , 두개의 클러스터는 연결되어있다고하며, 하나의 클러스터로 묶어준다.
- 모든 점에 대하여 클러스터링 과정을 끝낸다.
- 어떤 점을 중심으로 하더라도 클러스터에 속하지 못하는 점이 있으면 noise point로 간주한다.
2) DBSCAN으로 k-means가 못한 군집화 가능


3) DBSCAN 단점
데이터 수가 적을때는 K-means 알고리즘이 더 느리지만, 군집화할 데이터의 수가 많아질수록 DBSCAN의 알고리즘 수행시간이 급격하게 늘어나게 된다.
또한 클러스터의 수 K를 지정해줄 필요가 없지만 데이터분포에 맞는 epsilon과 minPts의 값을 지정해줘야한다.
정리

