
CS231n 6강
learning process를 어떻게 관리해나가야하는지 살펴보자
1. 데이터 전처리
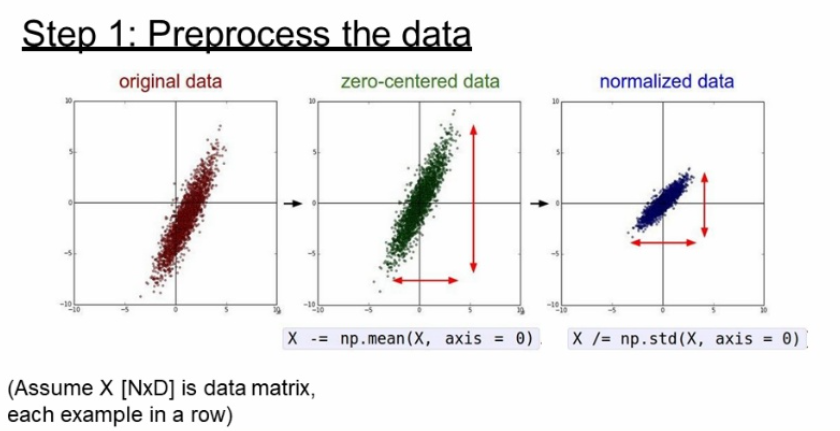
첫번째 단계로는 데이터를 전처리 해야한다.
이미지에서는 이미 0-255의 값으로 되어있기때문에 정규화할 필요는 없고, zero centered만 하면 된다.
2. 구성 잡아놓기
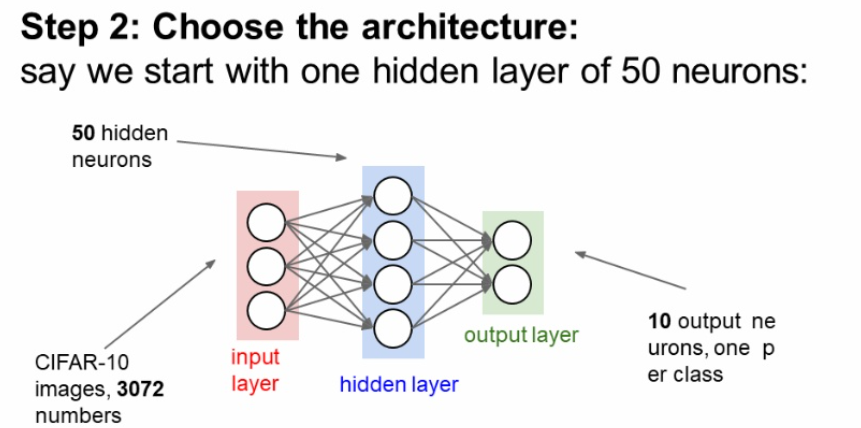
히든 레이어의 구성 등을 일단 잡아 놓는다. 물론 최적의 architecture을 한번에 찾긴 힘들겠지만..
3. 모델이 잘 동작되는지 확인
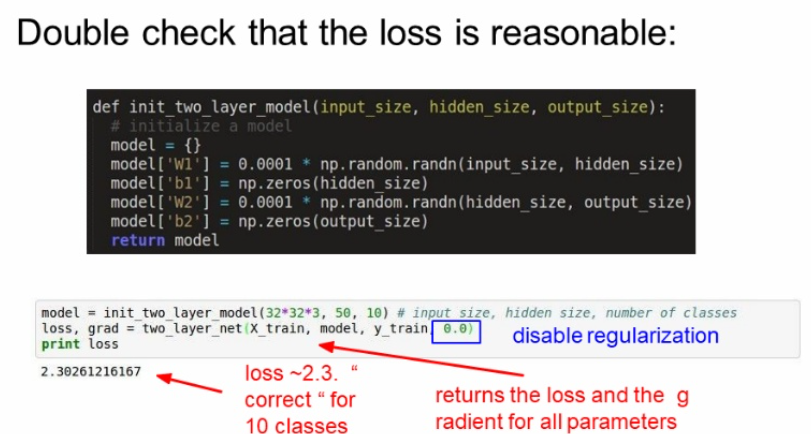
구상한 architecture로 초기 loss값이 잘 나오는지 확인한다.
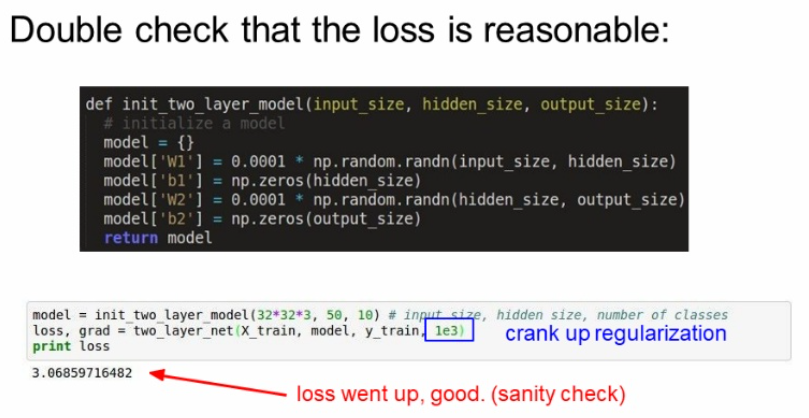
regularization을 살짝 올렸을 때도 loss가 증가가 되었으니 잘 동작한다고 보면 된다.

훈련하기 전에, 일부 작은 데이터만 취해 규제는 하지않고 sgd 방법으로 훈련시켜본다.
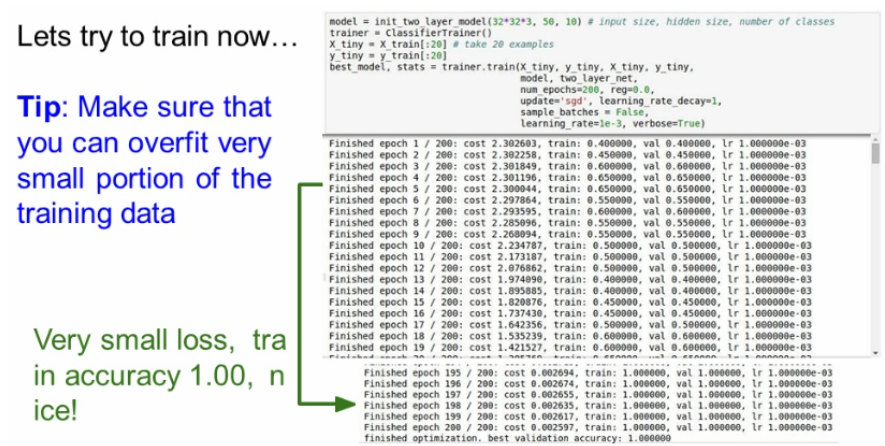
데이터 수가 작기때문에 무조건 오버피팅이 일어나야한다.
오버피팅이 일어나지 않으면 모델이 잘 동작하지 않는다는 것을 의미한다.
learning rate

우선 learning rate에 아주 작은 값 1e-6 을 주었더니 cost 값의 변화가 아주 조금씩 일어난다. 그래도 훈련은 되고 있으니 accuracy는 증가하고 있다.

learning rate를 1e6으로 올렸더니 cost값이 NaN이 되었다.
학습률이 너무 커져서 튕겨나가버린것이다.

3e-3도 마찬가지이다.
학습률이 1e-3 ~ 1e-5값이 적당하다는 것을 추측할 수 있다.
이제 본격적으로 훈련을 시키면서 적절한 하이퍼파라미터를 찾아보자
4. 하이퍼파라미터 조절

값을 넓은 범위에서 좁은 범위로 줄여나가는 방법을 사용한다.
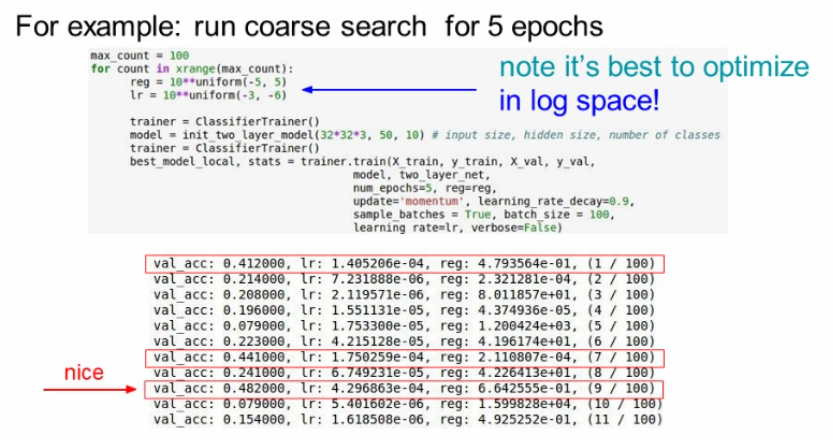
넓은 범위를 주어서 훈련을 시키고 결과를 확인한다.
val_acc가 best인 48%를 살펴보면 lr값은 4.3e-4, reg값은 6.64e-1이다.
이 범위를 기준으로 좁혀가는 것이다.

reg는 (-4,0) , lr 은 (-3,-4)로 좁혔더니 best는 53%로 올랐다.
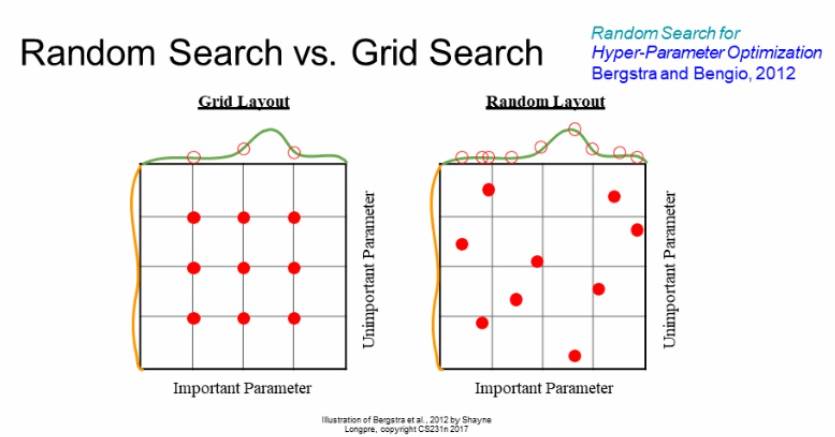
위의 방법은 그리드 서치로 최적의 값을 찾지 못할 수도 있다.
왜냐면 일정한 간격으로 하이퍼파라미터를 조정하기에 못찾는 값들이 있다는 것이다.
그래서 보통 랜덤으로 찾는 랜덤서치의 방법을 사용한다고 한다.
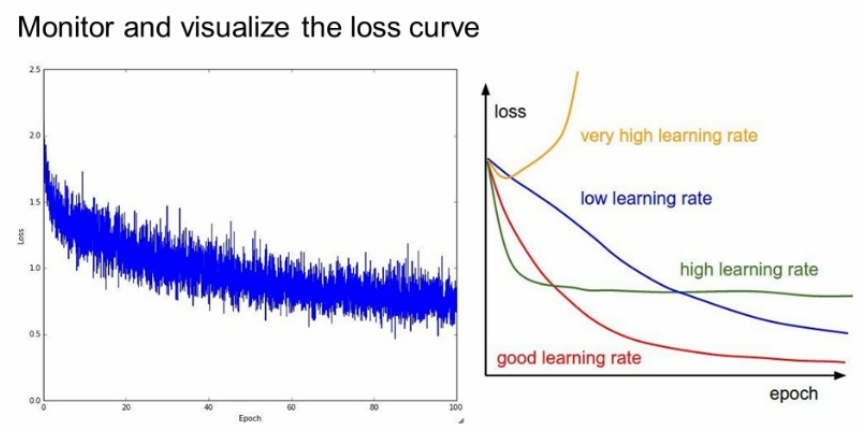
loss 그래프를 보고 학습률을 조절할 수도 있다.
우리가 원하는 빨간색이 되게끔
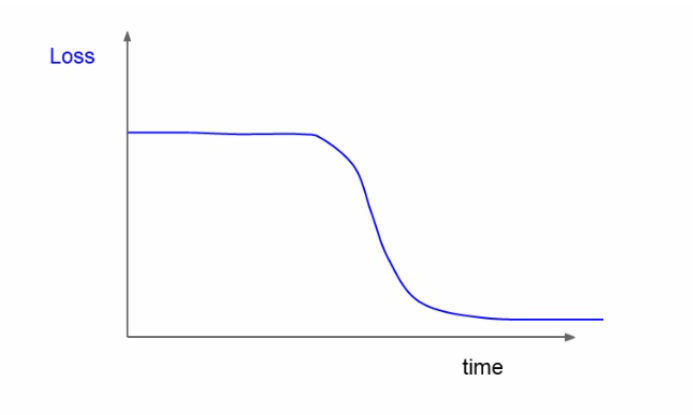
만약 이런 커브를 가졌다면 초기화에 문제가 생긴 것이다.
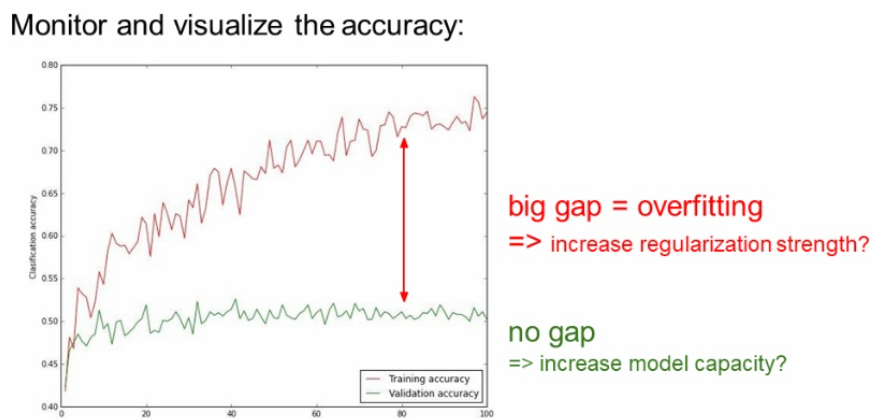
그리고 이렇게 gap 차이가 크면 regularization의 강도를 높여야한다.
