
CS231n 6강
활성화 함수
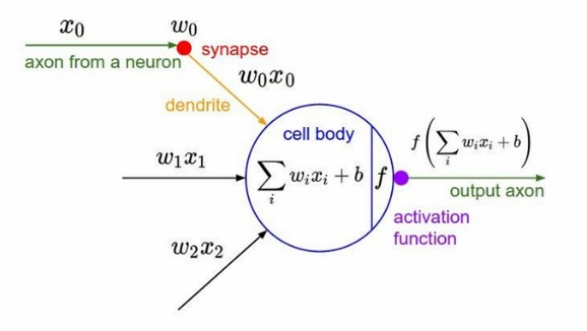
f = Wx 에 대해 input값이 linear하게 들어오면 활성화함수를 거쳐서 non-linear하게 output을 출력한다. linear한 값을 사용하면 수식이 많아져도 1개의 layer로 처리되기때문에 non-linear한 값을 사용한다.
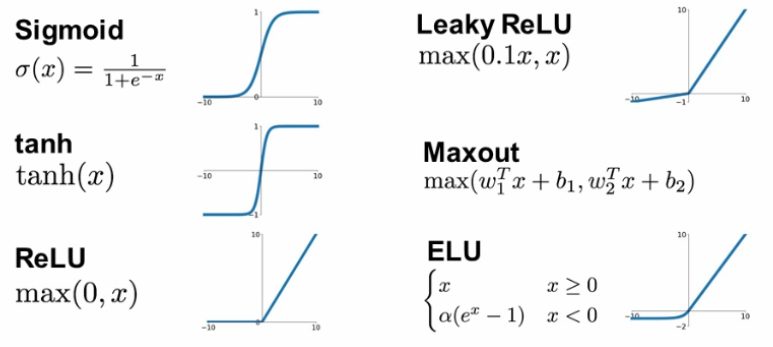
활성화 함수는 이렇게나 다양하다. 하나하나 살펴보도록 하자
1. Sigmoid
시그모이드 함수는 최종 출력 이진분류에서 사용한다.
과거에는 은닉층에서도 사용했지만 3가지 문제점 때문에 더이상 은닉층에서는 사용하지않는다.
어떤 문제때문에 히든 레이어에서는 사용하지않는지 살펴보자
1) gradient vanishing 문제
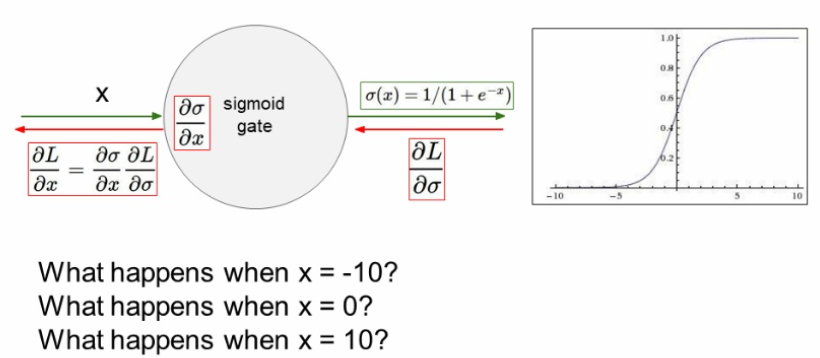
x=0일때 문제가 되지않지만
x=10,-10 일때는 saturation되어 gradient를 없앤다.
saturation 된다는 것은 입력값이 아무리 커지고 작아져도, 함수의 출력은 1이상으로 높아지지않고 0이하로 떨어지지않는다는 의미이다. 이렇게 포화가 되면 gradient가 0과 아주 가까워진다는 문제점이 생긴다.
0과 가까워진 gradient가 역전파와 곱해지면 그 이후로 전파되는 역전파 값이 0에 근접하게 되어 가중치 업데이트가 일어나지않는다. 아무리 에포크를 많이 돌려도 훈련이 되지않는다는 말이다.
2) zero-centered 가 아님
0이 중심이 아니면 훈련의 시간이 오래 걸린다.
입력값으로 들어오는 데이터의 값이 모두 양수라고 가정하자
노드의 가중치 업데이트를 위해 구해야하는 gradient는 다음과 같다

입력으로 들어오는 x가 언제나 양수이면 sigmoid를 거친 X도 언제나 양수가 된다.
결국 의 부호는 global gradient가 결정하게 된다.
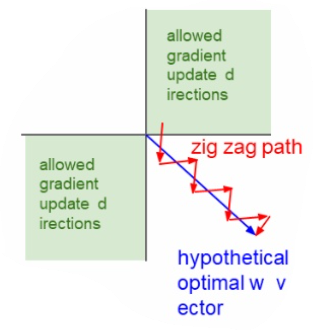
즉, global gradient의 부호에 따라 노드의 가중치는 모두 양의 방향으로 업데이트되거나, 모두 음의 방향으로 업데이트가 된다. 이런식으로 업데이트가 이루어지면 zigzag path가 되어 최적값을 향해 직선적으로 업데이트 되는 것 보다 훨씬 시간이 오래 걸려 비효율적이다.
3) exp는 비싼 연산
2. tanh(x)
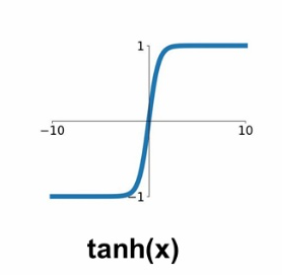
시그모이드 함수를 zero-centered 한 것이다. 하지만 기울기 소실문제와 비싼 exp연산이 남아있다.
3. ReLU
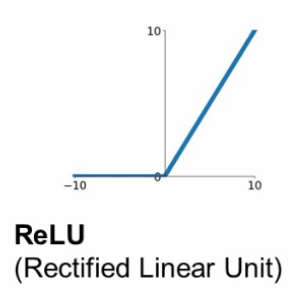
가장 대중적으로 사용하는 활성화 함수이다.
렐루함수는 비용이 높은 exp 연산을 사용하지않아서 sigmoid, tanh보다 처리속도가 훨씬 더 빠르다.
f(x) = max(0,x) 의 식으로 매우 단순하지만 잘 동작하는 활성화함수이다.
시그모이드 함수처럼 곡선이 포함되어있지않은데도 비선형 데이터의 특징을 잘 잡아낸다고한다.
[참고]( ReLU Deep Neural Networks and Linear Finite Elements)
하지만 렐루함수도 문제가 있다.
1) zero-centered 가 아님
출력값이 0이상의 값들을 가지기때문에!
2) dead ReLU
0이하의 값들은 gradient가 0이 되어 문제가 생긴다.
이를 Dead ReLU라고도 한다.

x=10의 경우 문제가 없지만
x=-10 의 경우 local gradient가 0이 되어 kill gredient
x=0 의 경우 극한이 존재하지않아서 undifined gradient
어떤 모델에 있는 한 노드의 출력값이 라고 하자.
그럼 이 노드의 가중치 업데이트를 위해 구해야하는 그래디언트는 다음과 같다.
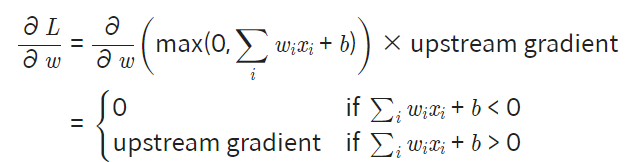
만약, 이전 훈련 스텝에서 이 노드의 가중치가 업데이트되어 가 가중치 w값에 의해 입력값 x와 상관없이 0이하로 나오게 되었다면, 이 이후의 업데이트에서는 gradient가 항상 0이 되어 가중치 업데이트가 일어나지 않는다.
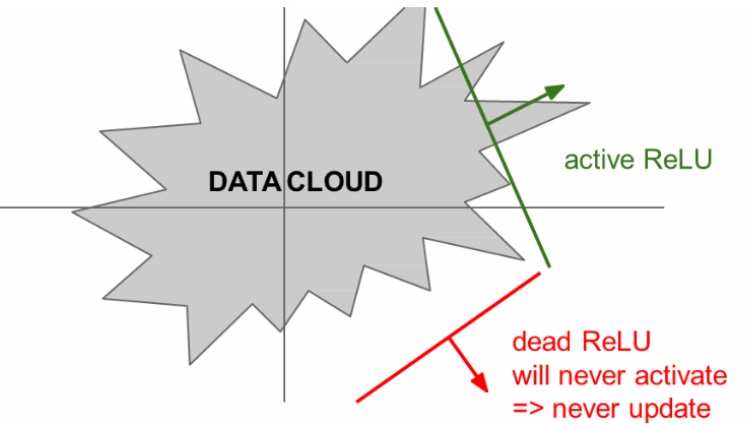
Dead ReLu가 되는 경우는
- 가중치 초기화를 잘못해서
- learning rate가 지나치게 커서
대부분 zero-bias를 사용하는데 Dead ReLU를 방지하기위해서 아주 작은 bias(0.01)를 추가한다. 아직까지는 논란이 있다.
4. Leaky ReLU
Dead ReLU를 해결하기 위한 시도 중 하나가 Leaky ReLU이다.
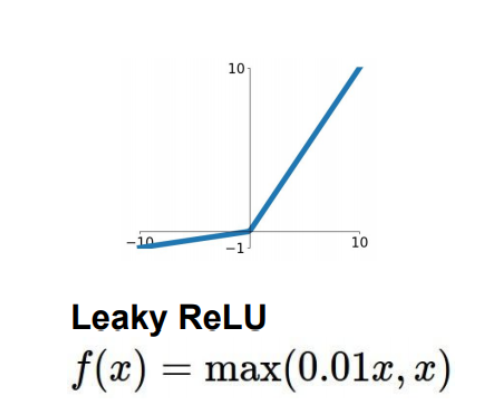
dead ReLU를 발생시켰던 0을 출력하는 부분을 아주 작은 음수값을 출력하게 만들어주어 해결하였다.
5. PReLU
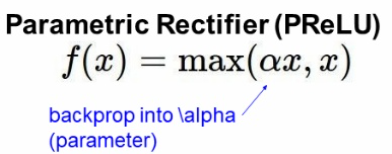
PReLU는 Leaky ReLU와 비슷하지만 새로운 파라미터를 추가하여 0 미만일때의 기울기가 훈련되게 하였다.
α 가 훈련과정에서 업데이트된다.
6. ELU
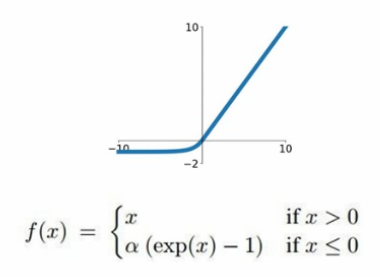
ReLU의 변형한 것으로 ELU도 있다.
ReLU의 모든 장점을 포함하며, 0이 중심점이 아니었던 단점과, Dead ReLU문제를 해결한 활성화 함수이다.
비싼 exp연산이 있다는것이 단점이다.
6. Maxout Neuron
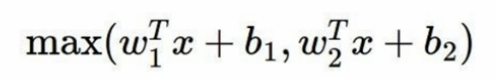
연산량이 2배 늘어나서 사용을 잘 안한다.
