최적화 방법
- 원론 기법: Gradient Descent(GD)
- 묶음 단위 학습: Mini-batch gradient descent(batch GD)
- 영상 단위 학습: Stochastic gradient descent(SGD)
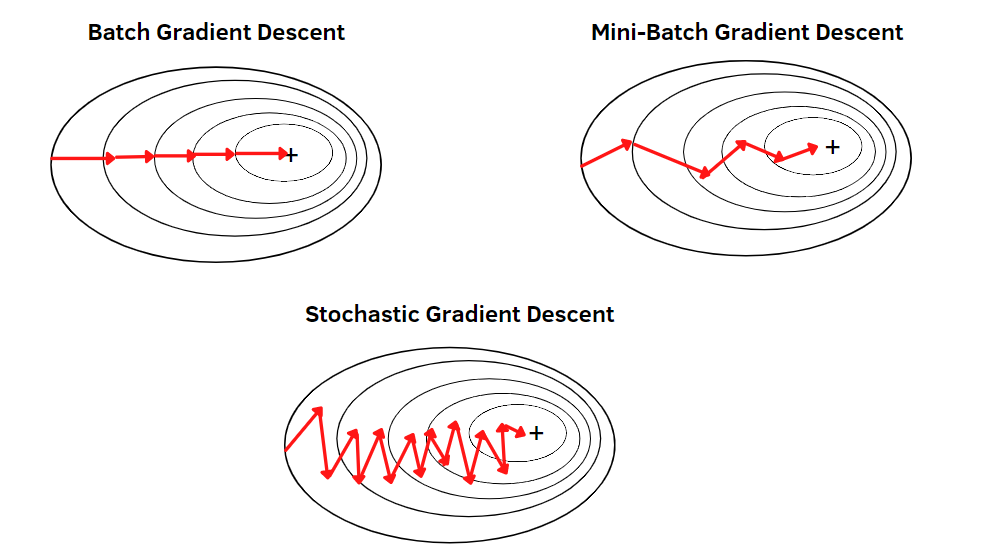
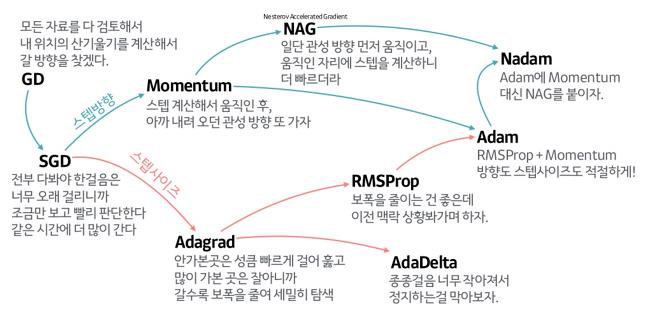
- 최근 가장 많이 쓰는 optimizer: Adam optimization
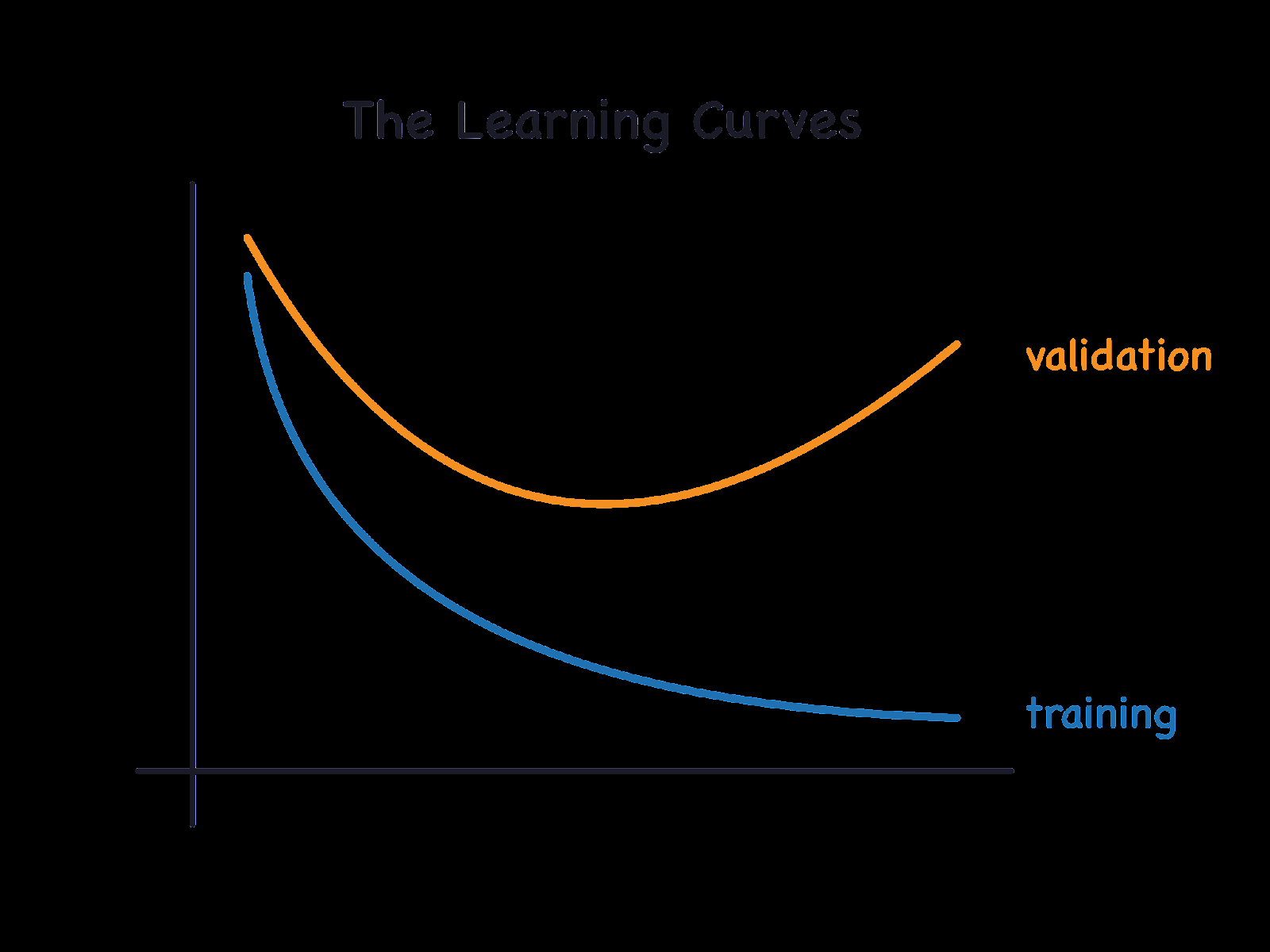
과적합 문제
-
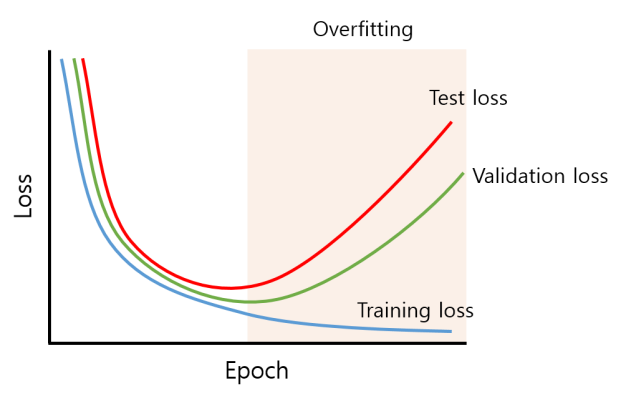
epoch가 크다고 무조건 좋은 건 아님 -> train loss는 점점 낮아지고 validation loss는 어느 순간 증가하는 '과적합' 발생
-
과적합 원인: training 데이터를 억지로 맞추게 됨

-
해결방안
-
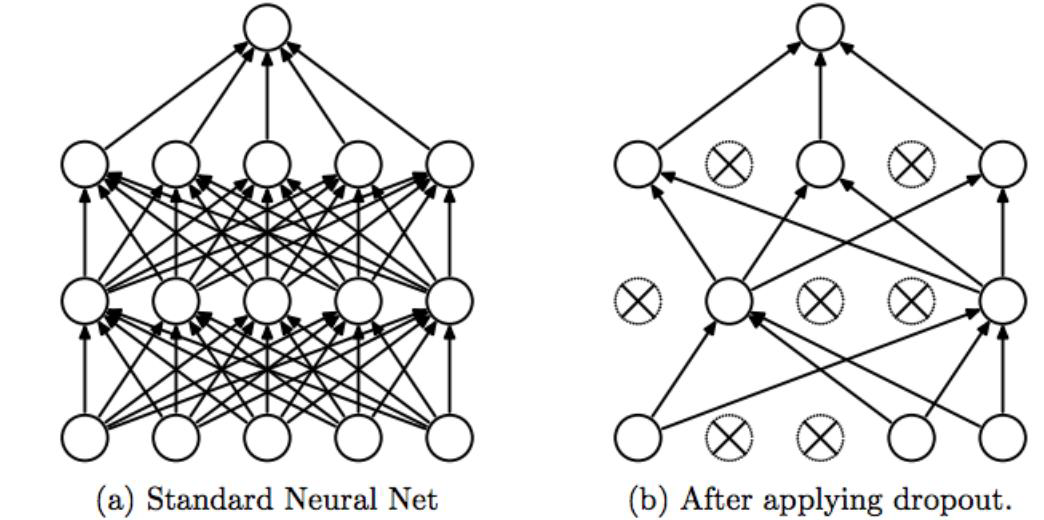
- drop-out layer 추가
- 주어진 확률로 랜덤한 위치의 뉴런 제거
- 매 학습마다 다양한 조합의 뉴런 학습 -> 과적합 방지
-
- 모델 간소화
- 파라미터가 많아짐에 따라 과적합 발생
-> 은닉 레이어의 파라미터 줄여 과적합 방지

-
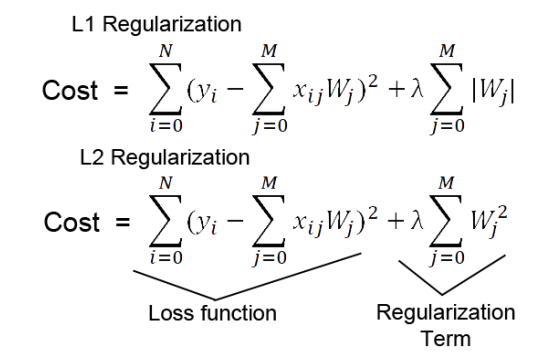
- 손실함수(loss function) 내 과적합 방지 함수(regularization term) 추가
- 일부 파라미터가 커지며 과적합 발생
-> 이를 제한하는 수식 손실함수 내에 추가하여 과적합 방지
-
- validation loss 이용
- validation loss가 증가할 때 학습 종료
-
-
손실함수
-
주어진 상황에 적합한 손실함수 사용
-
Binary Crossentropy: 이진결과(0/1) 문제
-
Categorical Crossentropy: 다중분류(클래스) 문제, 입력단에서 one-hot encoding 사용
-
Sparse Categorical Crossentropy: 다중분류(클래스) 문제, 입력단에서 one-hot encoding 없이 바로 클래스 적용
-
Mean absolute error(MAE) & Mean square error(MSE): 회귀문제(Regression), 실제값과 예측값의 차이 활용
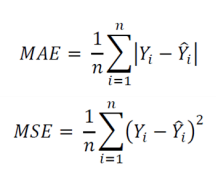
-
Dice loss: 영상 분할(Segmentation), 정답과 예측이 얼마나 겹치는지 수치화
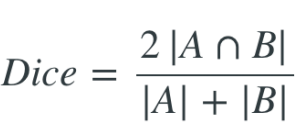
-

Data Science