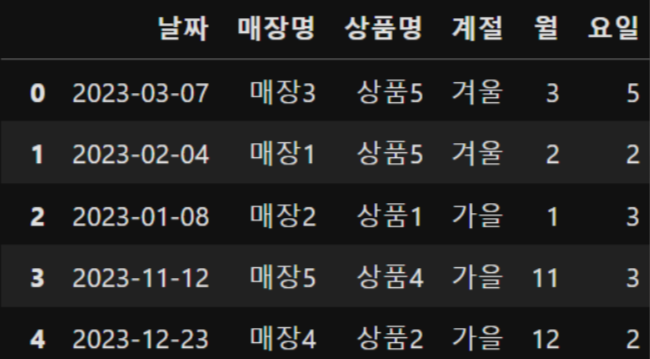
# 랜덤 샘플코드
import pandas as pdimport numpy as np
# 시작일과 종료일 설정
start_date = '2023-01-01'
end_date = '2023-12-31'
# 날짜 컬럼 생성
date_rng = pd.date_range(start=start_date, end=end_date, freq='D')
# 매장명과 상품명 랜덤 생성
store_names = ['매장1', '매장2', '매장3', '매장4', '매장5']
product_names = ['상품1', '상품2', '상품3', '상품4', '상품5']
season_names = ['봄','여름','가을','겨울']
df = pd.DataFrame({'날짜': np.random.choice(date_rng, 100),
'매장명': np.random.choice(store_names, 100),
'상품명': np.random.choice(product_names, 100),
'계절': np.random.choice(season_names, 100)})label encoding
before

from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
encoder.fit(df['요일'])
df['요일'] = encoder.transform(df['요일'])
after
one_hot encoding
# '월','계절'을 원핫인코딩으로 변환
df.info()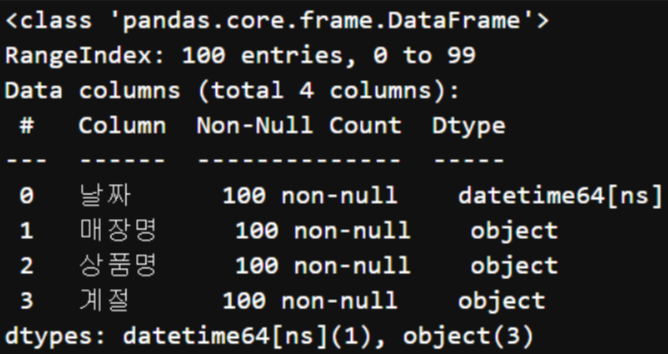
숫자형을 dummy화하면 어떻게 될까?
# 자료형에 유의할 것.
pd.get_dummies(df['월'])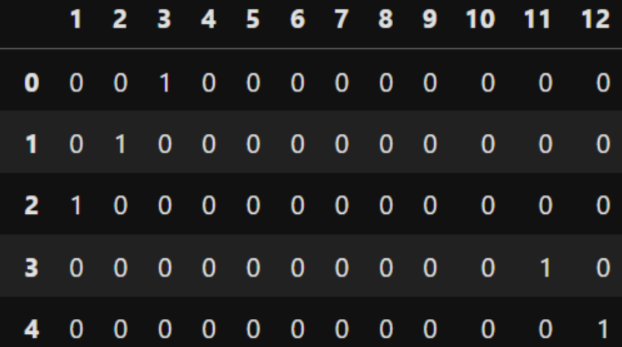
data type이 숫자인 경우 생길 수 있는 문제 : 월,일 등 컬럼이 혼재됨. 1이 1월이라는 건지 1일이라는 건지...
그래서 월_1, 일_1 이런 식의 원핫인코딩을 해주어야 함
# 딕셔너리형태로 데이터프레임 + 데이터타입:string
pd.get_dummies(pd.DataFrame({'월':list(df['월'].astype('string'))}))
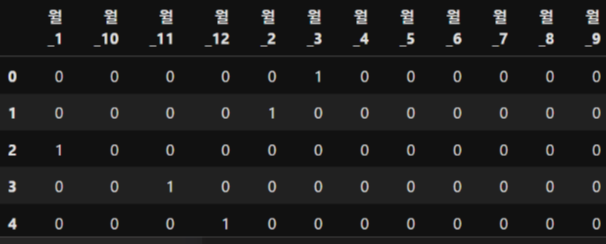
# 응용
after=pd.DataFrame()
for var in ['월','계절']:
sample = pd.DataFrame({var:list(df[var].astype('string'))})
tmp_after_var = pd.get_dummies(sample, prefix=None, prefix_sep='_',dummy_na=False)
after=pd.concat([after,tmp_after_var], axis=1)
after


데이터 분석/엔지니어링/ML에 관한 기록