EDA를 하는 방법은 크게
주피터 노트북에서 df.info(), df.descrieb(), df.isnull() 등으로 한땀한땀 코드를 입력하면서 확인하거나 때로는 태블로에 띄워서 요리조리 확인했었다.
- 첫번째 방법은 코드 작업을 하면서 바로 확인하기 쉽지만, 하나하나 코드를 입력하는 작업이 반복적이라 소모적인 느낌이 든다는 단점이 있다.
- 두번째 방법은 드래그앤드롭으로 직관적으로 확인하기 쉽지만, 일단 툴에 대한 진입장벽이 있고 좀 다양한 관점에서 보려고 하면 한계에 부딪힌다. (EDA하려고 태블로 켰는데 갑자기 정신을 차려보니 태블로 기능 검색을 하고 있음)
그런데 이에 대한 절충안을 해줄 패키지를 찾았다 +_+
바로 ydata-profiling!!
# Step 1: 패키지 설치
# !pip install ydata-profiling
# Step 2: 샘플 데이터 로드
import pandas as pd
from sklearn.datasets import load_iris
# Iris 데이터 로드
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# Step 3: ydata-profiling을 사용한 데이터 프로파일링
from ydata_profiling import ProfileReport
# 데이터 프로파일링 리포트 생성
profile = ProfileReport(df, title="Iris Dataset Profiling Report")
# 리포트를 주피터 노트북에서 직접 표시
profile.to_notebook_iframe()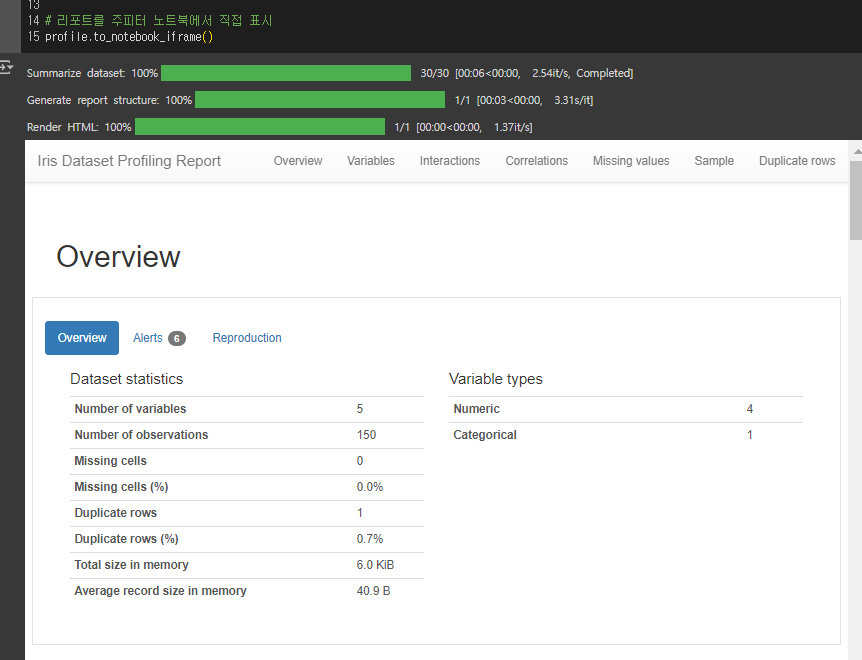
중복값, NULL값, 메모리, 데이터타입, 컬럼별 상세 EDA,상관관계까지 분석 가능하다.
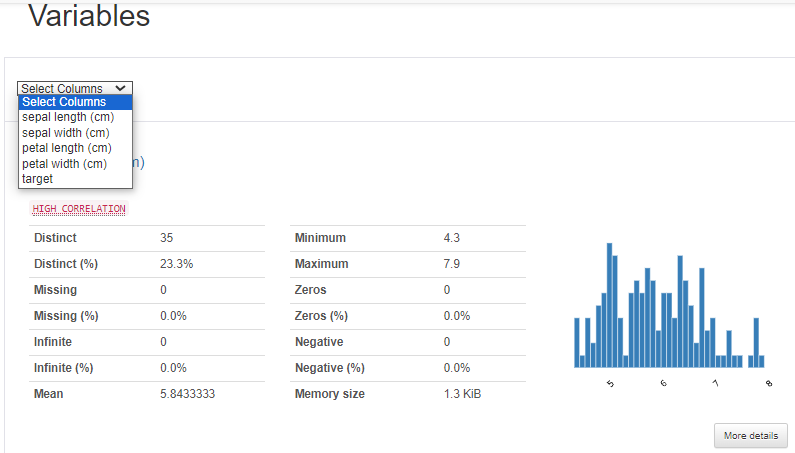
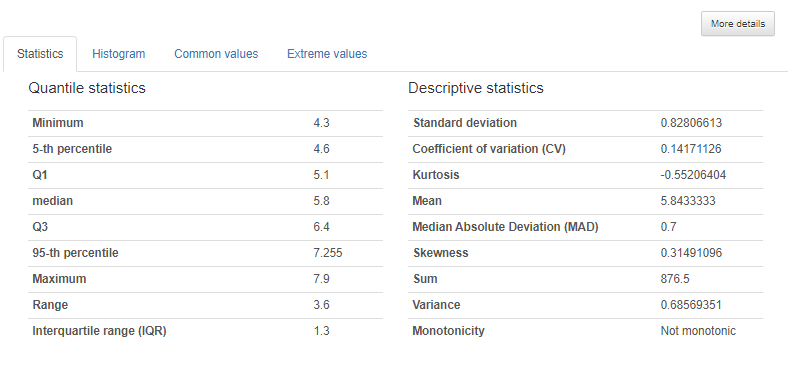
More detail 클릭하면 기술통계정보도 제공한다.

데이터 분석/엔지니어링/ML에 관한 기록