이번 포스팅에서는 성능지표 중 하나인 mape를 구하는 예제를 통해서
자주 사용하는 데이터프레임 스킬을 익히고자 한다.
우선 샘플 테이블을 생성해보자
# 시작일과 종료일 설정
start_date = '2023-01-01'
end_date = '2023-12-31'
# 날짜 컬럼 생성
date_rng = pd.date_range(start=start_date, end=end_date, freq='D')
# 매장명과 상품명 랜덤 생성
store_names = ['매장1', '매장2', '매장3', '매장4', '매장5']
product_names = ['상품1', '상품2', '상품3', '상품4', '상품5']
season_names = ['봄','여름','가을','겨울']
df = pd.DataFrame({'날짜': np.random.choice(date_rng, 100),
'매장명': np.random.choice(store_names, 100),
'상품명': np.random.choice(product_names, 100),
'계절' : np.random.choice(season_names, 100),
'예측판매량': np.random.randint(0, 51, 100),
'실제판매량': np.random.randint(0, 51, 100)
})
후반부에 나올 케이스 설명을 위해 매장1,상품1에 대한 실제판매량을 모두 0으로 만들어보겠다. 상품 중에서는 특정 기간동안 안팔린 상품도 충분히 존재할 수 있으니깐!
cell값 변경
- 보통 dataframe은 행, 열단위로 접근하긴 하지만..!
조건에 의해 cell값을 변경하는 방법은 loc[]을 이용하는 것이다.
df.loc[(df['매장명']=='매장1')&(df['상품명']=='상품1'),'실제판매량']=0groupby
- groupby를 하는 이유는 '집계'연산을 위해서이다.
- 집계연산을 위해서 .agg([새로운컬럼명]=('[기존컬럼명]','연산종류')) 메서드를 사용해준다.
- 이때 원활한 추가작업을 위해서는 groupby를 쓴 경우 reset_index()를 써주는 것이 좋다.
안써주면 이렇게 됨
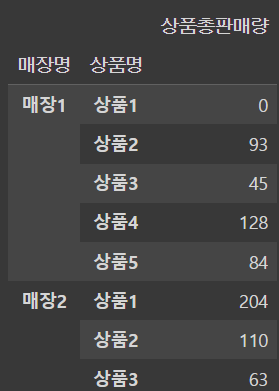
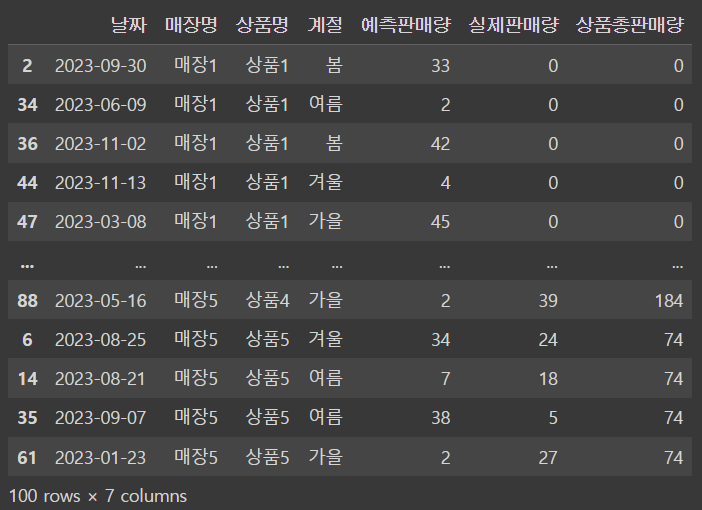
df_sum_actual_sales = df.groupby(['매장명','상품명']).agg(상품총판매량=('실제판매량','sum')).reset_index()df2 = df.merge(df_sum_actual_sales, how='left', on=['매장명','상품명']).sort_values(['매장명','상품명'])
df2날짜 매장명 상품명 계절 예측판매량 실제판매량 상품총판매량 2 2023-09-30 매장1 상품1 봄 33 0 0 34 2023-06-09 매장1 상품1 여름 2 0 0 36 2023-11-02 매장1 상품1 봄 42 0 0 44 2023-11-13 매장1 상품1 겨울 4 0 0 47 2023-03-08 매장1 상품1 가을 45 0 0 .. ... ... ... .. ... ... ... 88 2023-05-16 매장5 상품4 가을 2 39 184 6 2023-08-25 매장5 상품5 겨울 34 24 74 14 2023-08-21 매장5 상품5 여름 7 18 74 35 2023-09-07 매장5 상품5 여름 38 5 74 61 2023-01-23 매장5 상품5 가을 2 27 74 [100 rows x 7 columns]
이제 오차를 구해보자
여기서 중요한 포인트는 컬럼끼리 나누는 연산 중 분모가 0인 경우를 방지하여 처리하는 것이다.
# 오차
df2['오차']=abs(df2['예측판매량']-df2['실제판매량'])df2날짜 매장명 상품명 계절 예측판매량 실제판매량 상품총판매량 오차 2 2023-09-30 매장1 상품1 봄 33 0 0 33 34 2023-06-09 매장1 상품1 여름 2 0 0 2 36 2023-11-02 매장1 상품1 봄 42 0 0 42 44 2023-11-13 매장1 상품1 겨울 4 0 0 4 47 2023-03-08 매장1 상품1 가을 45 0 0 45 .. ... ... ... .. ... ... ... .. 88 2023-05-16 매장5 상품4 가을 2 39 184 37 6 2023-08-25 매장5 상품5 겨울 34 24 74 10 14 2023-08-21 매장5 상품5 여름 7 18 74 11 35 2023-09-07 매장5 상품5 여름 38 5 74 33 61 2023-01-23 매장5 상품5 가을 2 27 74 25 [100 rows x 8 columns]
아까 매장1, 상품1의 판매량을 0으로 모두 변경해서 상품총판매량이 0인 케이스가 발생한다.
이런 경우에서 그냥 바로 나누기를 날려버리면
# mape
df2['오차']/df['상품총판매량']
이렇게 오류를 선물해준다.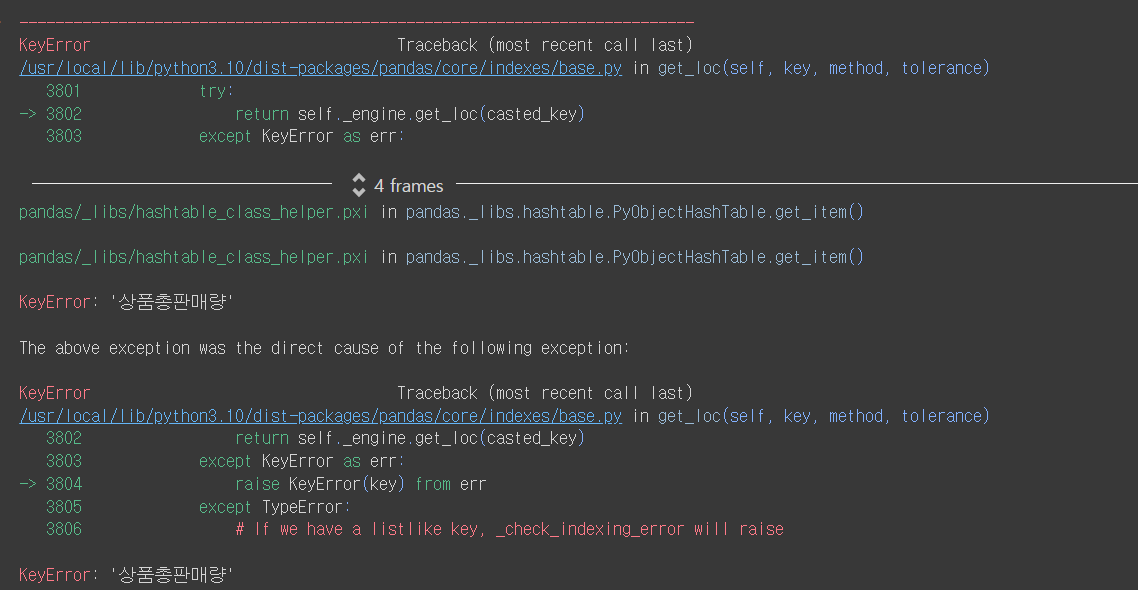
에러를 방지하기 위해서는 분모가 0이 아닐 때만 나눠주는 조건이 필요할 것이다
apply & lambda
apply와 lambda를 이용해 조건에 따른 연산처리를 할 수 있다.
⭐ lambda 함수가 유용한 경우
- 함수를 한 번만 사용할 때
- 함수를 인자로 전달해야 할 때
df2.apply(lambda x:x['오차']/x['상품총판매량'] if x['상품총판매량']!=0 else 0, axis=1)2 0.000000
34 0.000000
36 0.000000
44 0.000000
47 0.000000
...
88 0.201087
6 0.135135
14 0.148649
35 0.445946
61 0.337838
Length: 100, dtype: float64

데이터 분석/엔지니어링/ML에 관한 기록