카프카(Kafka)란?
(Before 카프카)
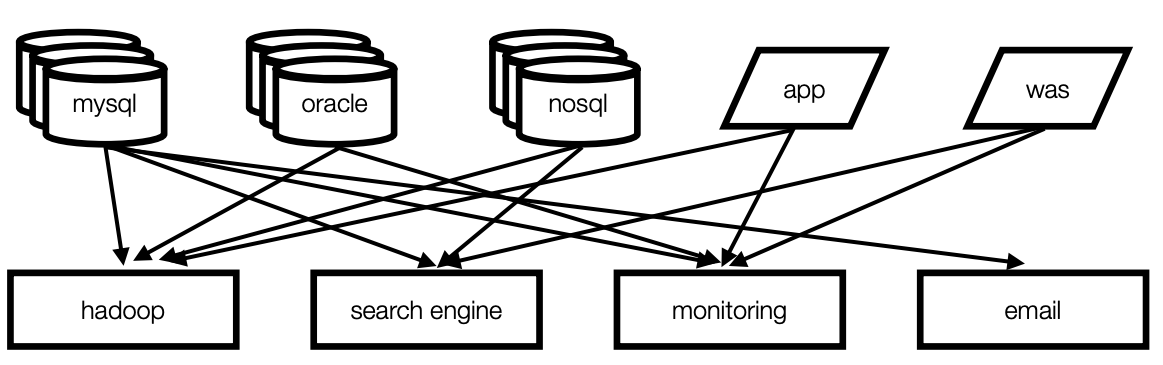
- 데이터를 전송하는 소스 애플리케이션과 데이터를 받는 타겟 애플리케이션으로 구성되어있음(스샷에서 Apps and Service가 소스 애플리케이션, Relational Data Warehouse가 타겟 애플리케이션)
- 엔드투엔드(end-to-end) 연결 방식의 아키텍쳐
- 데이터 연동의 복잡성 증가(하드웨어, 운영체제, 장애 등)
- 하드웨어, 운영체제가 달라서 생기는 문제
- 즉, 복잡성이 높아져 간단한 수정사항에도 에러가 발생할 확률이 높아짐
- 각기 다른 데이터 파이프라인 연결 구조
- 확장에 엄청난 노력 필요
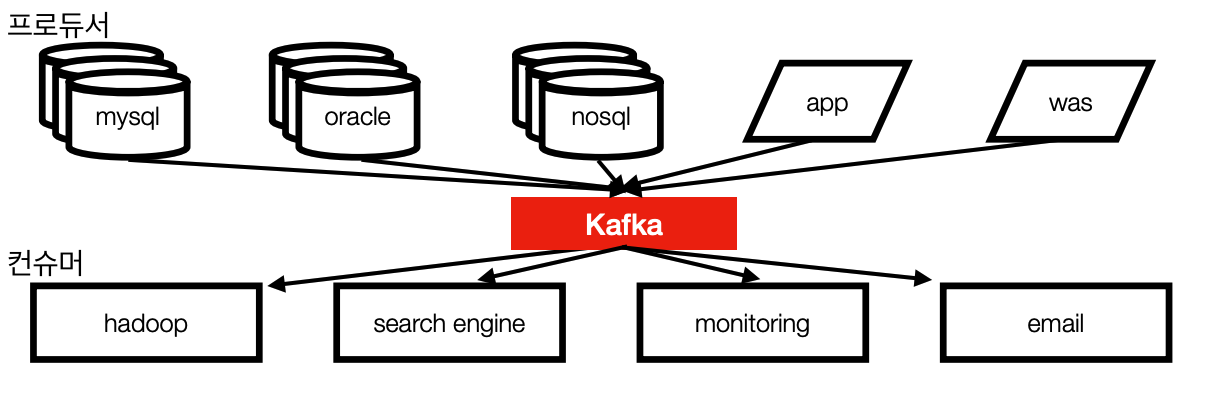
- 이로인해, 모든 시스템으로 데이터를 전송 및 실시간 처리도 가능하며, 데이터가 갑자기 많아지더라도 확장이 용이한 시스템이 필요해짐 이러한 필요성에 의해서 링크드인에서 자체개발한게 카프카
(After 카프카)
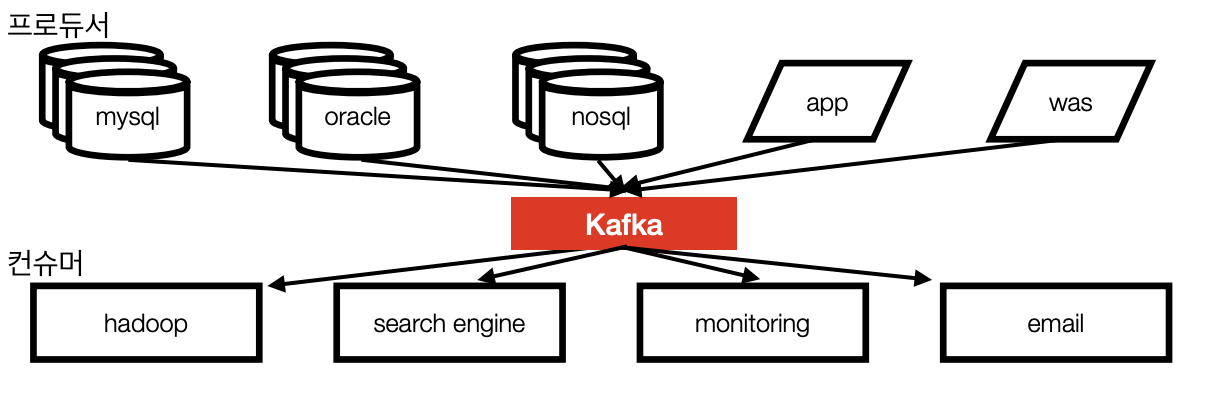
- 카프카가 개발되고 나서는 중추신경처럼 한군데 모였다가 퍼지게됨
- 프로듀서/컨슈머 분리
- 메세지 데이터를 여러 컨슈머에게 허용
- 어떤 데이터가 카프카에 들어간 이후에는 여러 컨슈머들이 각각 가져갈 수 있게 즉, 여러번 가져갈 수 있게 만듦
- 높은 처리량을 위한 메세지 최적화
- (쉽게) 스케일 아웃 가능
- 무중단으로 스케일 아웃이 가능
- 관련 생태계(eco system) 제공
카프카 브로커(broker) & 클러스터(Cluster)
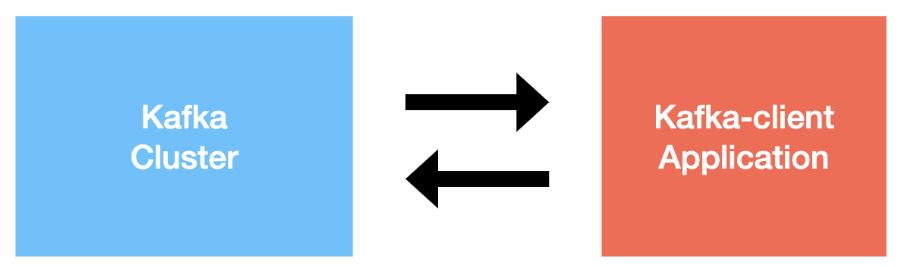
- 스샷에서 카프카 클러스터 부분 = 여러개의 카프카 브로커가 1개의 클러스터 이룸
- 카프카 클라이언트 => 카프카 프로듀서/컨슈머 뜻함
- 브로커는 중추신경 부분이라고 생각하자
- 브러커는 실행된 카프카 애플리케이션 서버 중 1대
- 브로커 = 서버 1대에 애플리케이션 1개가 띄워져 있다는 뜻
- (참고) 이론상으로 애플리케이션은 JVM이기 때문에 서버 1대에 2개 이상의 애플리케이션을 띄울 수 있지만, 대부분의 경우 서버 1대에 애플리케이션 1개를 띄움
- 보통 3대 이상의 브로커(=서버)로 클러스터 구성
- 보통은 카프카와 주키퍼를 연동해서 사용하지만, 카프카 2.8.0부터는 주키퍼 연동없이도 사용가능하지만 아직까지는 주키퍼와 연동해서 사용하는 경우가 많음
- 주키퍼
- 현재 주키퍼의 역할은 메타데이터를 저장함 브로커id 혹은 컨트롤러id를 저장함
- 추후에는 이러한 메타데이터를 카프카 클러스터 즉 브로커 안에 저장한다고 함
- 주키퍼
- n개(=여러개) 브로커 중 1대는 컨트롤러(Controller) 기능 수행
- 컨트롤러
- 각 브로커에게 담당파티션 할당 수행
- 브로커가 정상적으로 동작하는지 모니터링 하는데 사용
- 누가 컨트롤러인지는 주키퍼에 저장됨
- 컨트롤러
레코드(Record, 프로듀서 레코드/ 컨슈머 레코드)
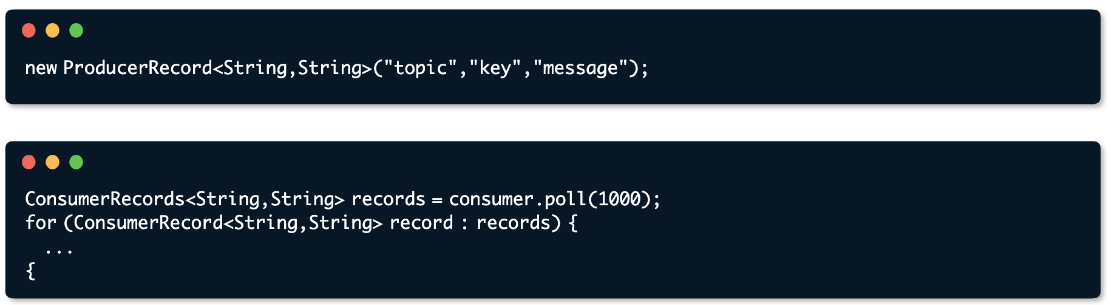
- 카프카에서 데이터를 주고받는 기본 단위
- 객체를 프로듀서에서 컨슈머로 전달하기 위해 Kafka 내부에 byte형태로 저 장할 수 있도록 직렬화/역직렬화하여 사용
- 기본 제공 직렬화 class : StringSerializer, ShortSerializer 등
- 커스텀 직렬화 class를 통해 Custom Object 직렬화/역직렬화 가능
- 간단하게 프로듀서 <> 브로커 <> 컨슈머는 레코드들을 주고 받는다고 생각하면됨
- 프로듀서는 레코드를 생성하여 ⇒ 카프카 브로커로 전송
- 컨슈머는 레코드를 카프카 브로커에서 pooling하는 애플리케이션
- 프로듀서/컨슈머 동일한 종류의 직렬화/역질렬화 맞춰줘야함
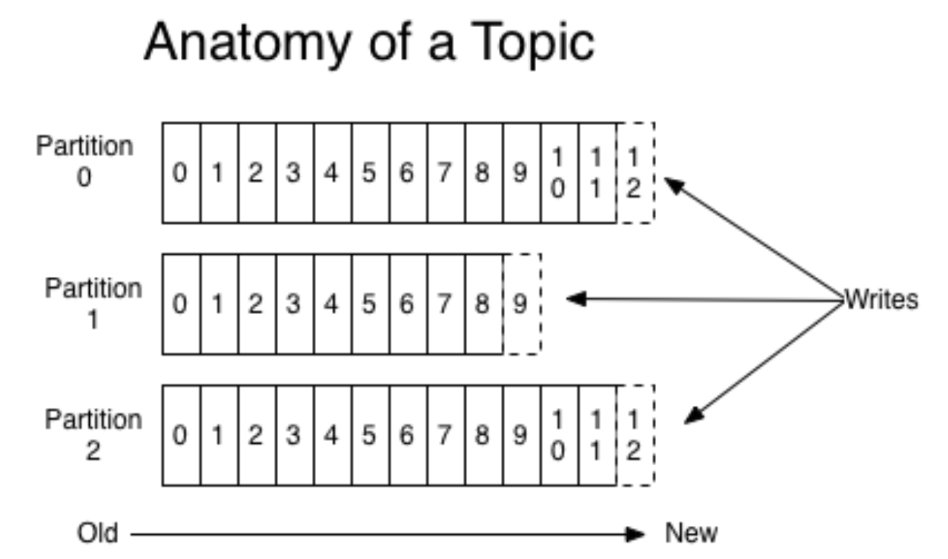
토픽(Topic) ⊃ 파티션(Partition) ⊃ 오프셋(Offset)
- 토픽은 메시지 분류 단위이며, n개의 파티션 할당 가능
- 토픽을 비유적으로 테이블이라고 생각하면 쉽게 이해됨
- 토픽안에 파티션은 반드시 1개이상 존재해야함 (토픽 파티션)
- 각 파티션마다 고유한 오프셋(Offset)을 가짐 = 각 파티션마다 오프셋이라는 번호가 붙는다
- 오프셋 0번 ~ n번 까지 있을때 0번이 가장 오래된거, n번이 가장 최신거
- 각 메시지 처리순서는 파티션 별로 유지 관리됨
- 파티션이 만약 1개라면 자료구조 큐에서 FIFO처럼 데이터를 가져가게됨 = 즉, 메세지 처리 순서가 들어간 순서대로 보장됨
- But, 파티션이 여러개이면 파티션 별로 관리되기때문에 메세지 처리 순서가 들어간 순서대로 보장되진 않음
카프카 클라이언트 - 프로듀서(Producer)와 컨슈머(Consumer)
- 프로듀서는 레코드를 새성하여 브로커로 전송
- 프로듀서가 레코드를 브로커에 전송하면 => 레코드는 특정 파티션의 특정 오프셋에 저장됨
- 즉, 전송된 레코드는 파티션에 신규 오프셋과 함께 기록됨
- 컨슈머는 브로커로부터 레코드를 요청하여 가져감 = 이를 풀링(polling)이라고 함
- 절대 브로커가 컨슈머로 보내는게 아님. 컨슈머가 브로커를 바라보면서 가져오는 것
- 브로커에 있는 동일 데이터(=같은 파티션에서 같은 오프셋인 데이터)를 특정 컨슈머가 한번 가져가면 끝인게 아니라, 여러 컨슈머가 브로커에서 한번씩 혹은 그이상(다시 가져와서 덮어쓰기 하는 경우)으로도 가져올 수 있음.
- 위 스샷에서 컨슈머 A와 컨슈머 B는 각각 다른 기능을 갖은 컨슈머인데(예를 들어 컨슈머 A 하둡에 넣어주는 역할, 컨슈머 B는 MySql에 넣어주는 역할) 각각 0번~12번의 데이터를 몇번이고 가져올 수 있음 => 예제5 참고
- 그리고 위 스샷에서처럼 컨슈머가 오프셋 11번을 가져갔다는 뜻은 이미 오프셋 0~10번 까지는 가져갔다는 것을 의미
카프카 로그 & 세그먼트(Kafka log & segment)
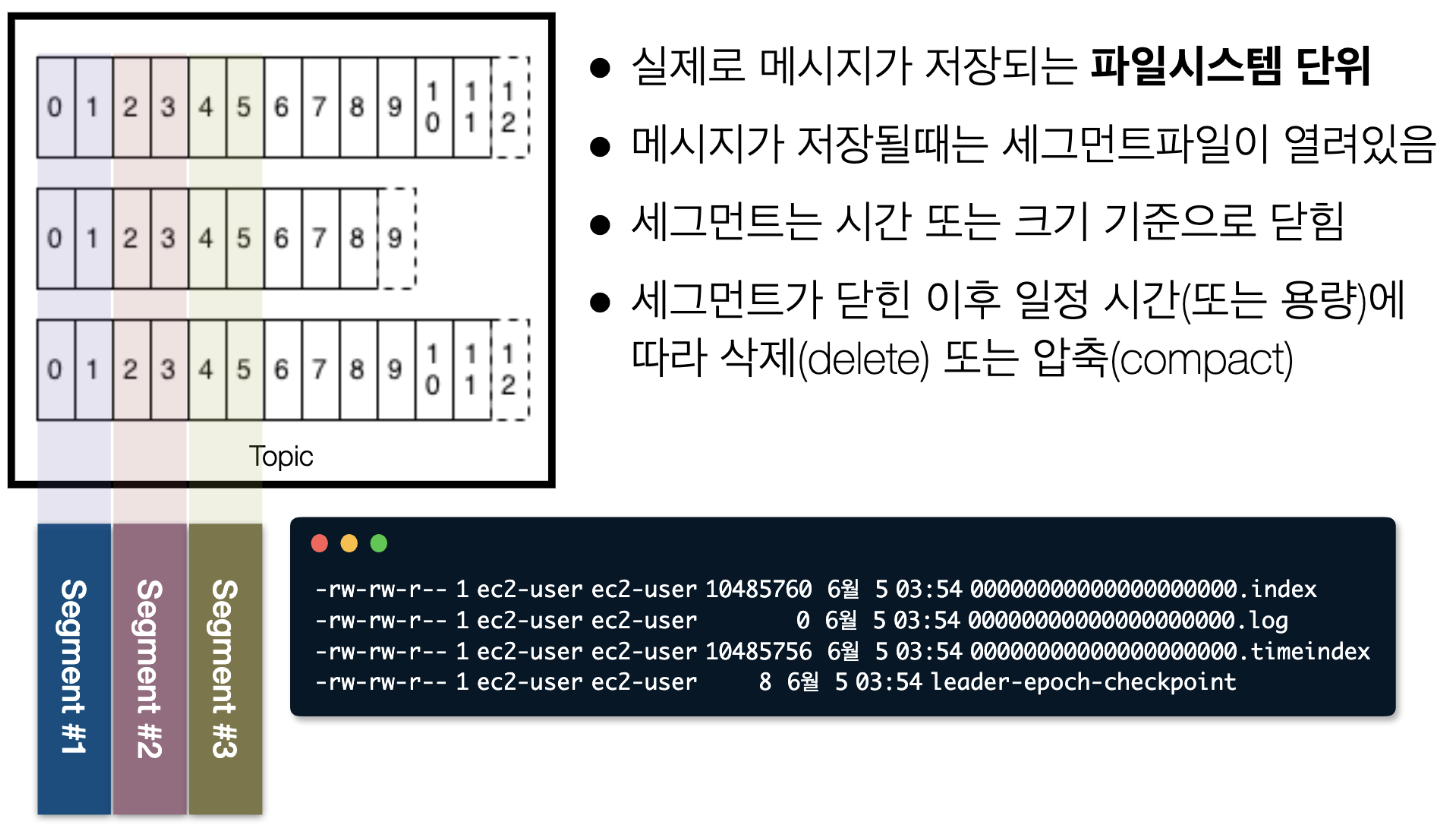
- 따라서, 카프카에 들어간 데이터는 (옵션으로 준) 일정기간, 일정용량에 따라서 언젠간 사라진다는 것을 알아둬야함
(예제1) 프로듀서 1개 <> 파티션이 3개인 토픽 <> 컨슈머가 1대인 경우
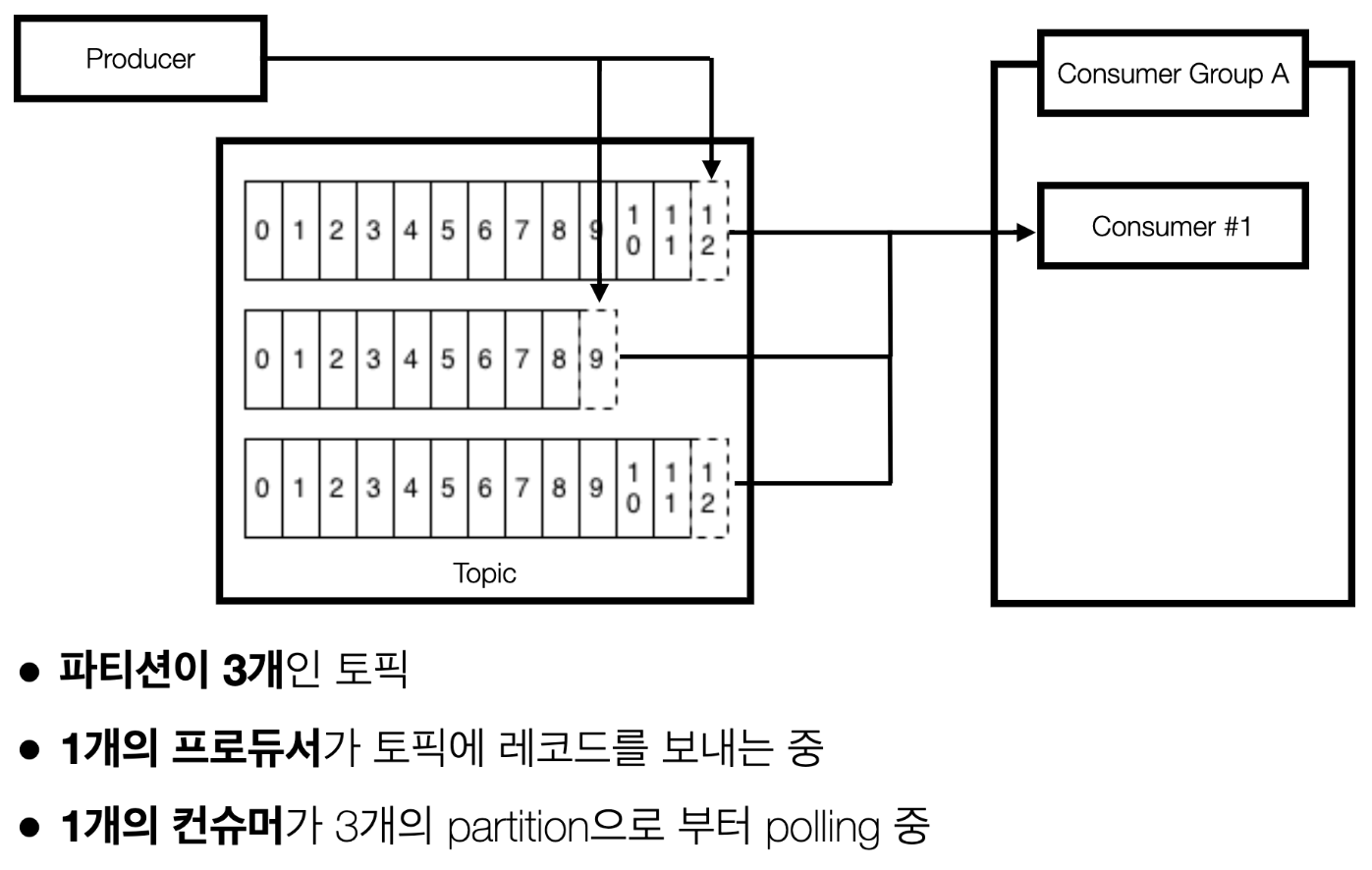
(예제2) 프로듀서 1개 <> 파티션이 3개인 토픽 <> 컨슈머가 3대인 경우
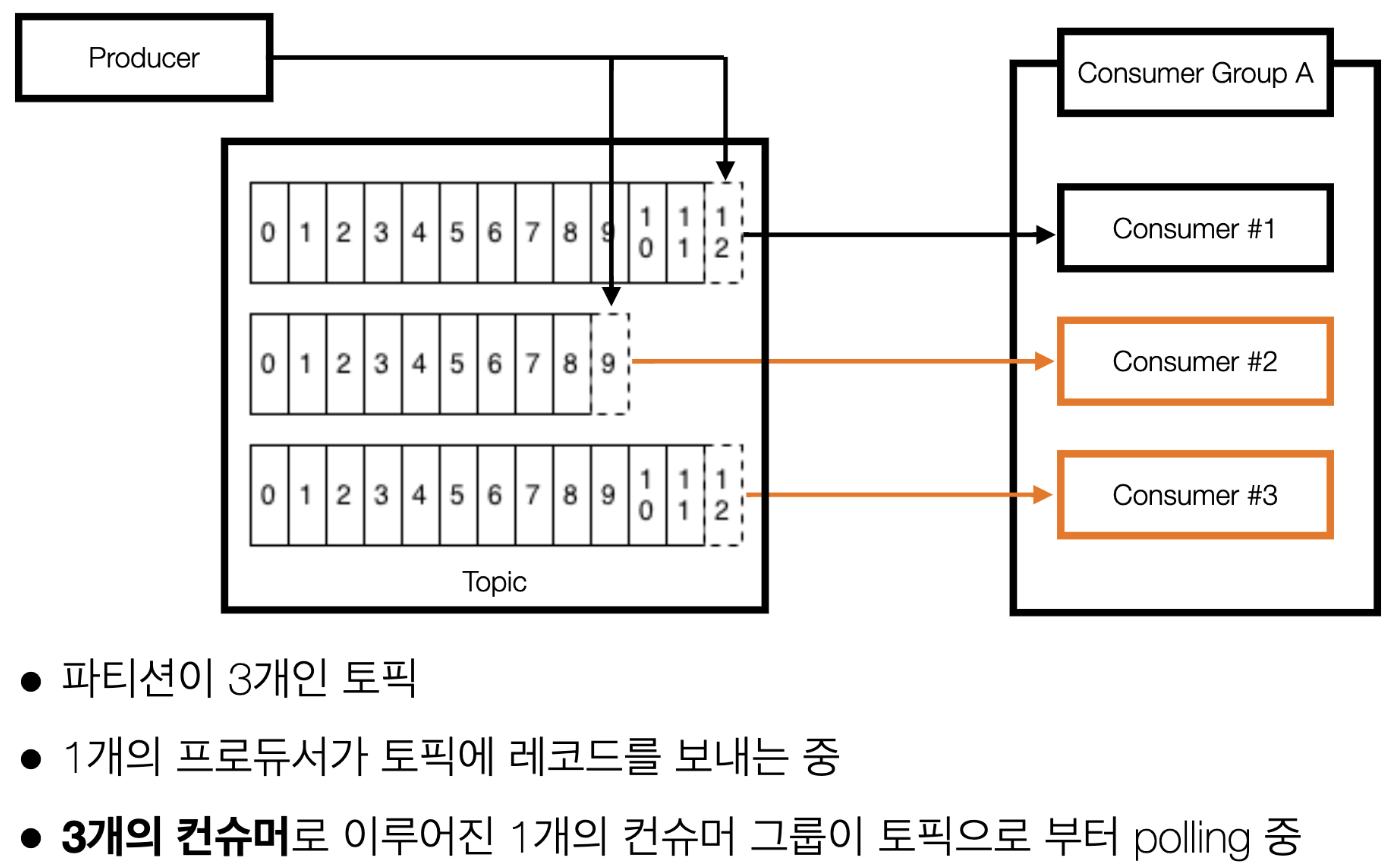
- 파티션이 3개이고 컨슈머가 3개인 경우 파티션과 컨슈머가 1대1 매칭됨
- 예제 1보다 예제 2의 경우 특정 토픽을 병렬처리하여 더 빠르게 처리할 수 있음
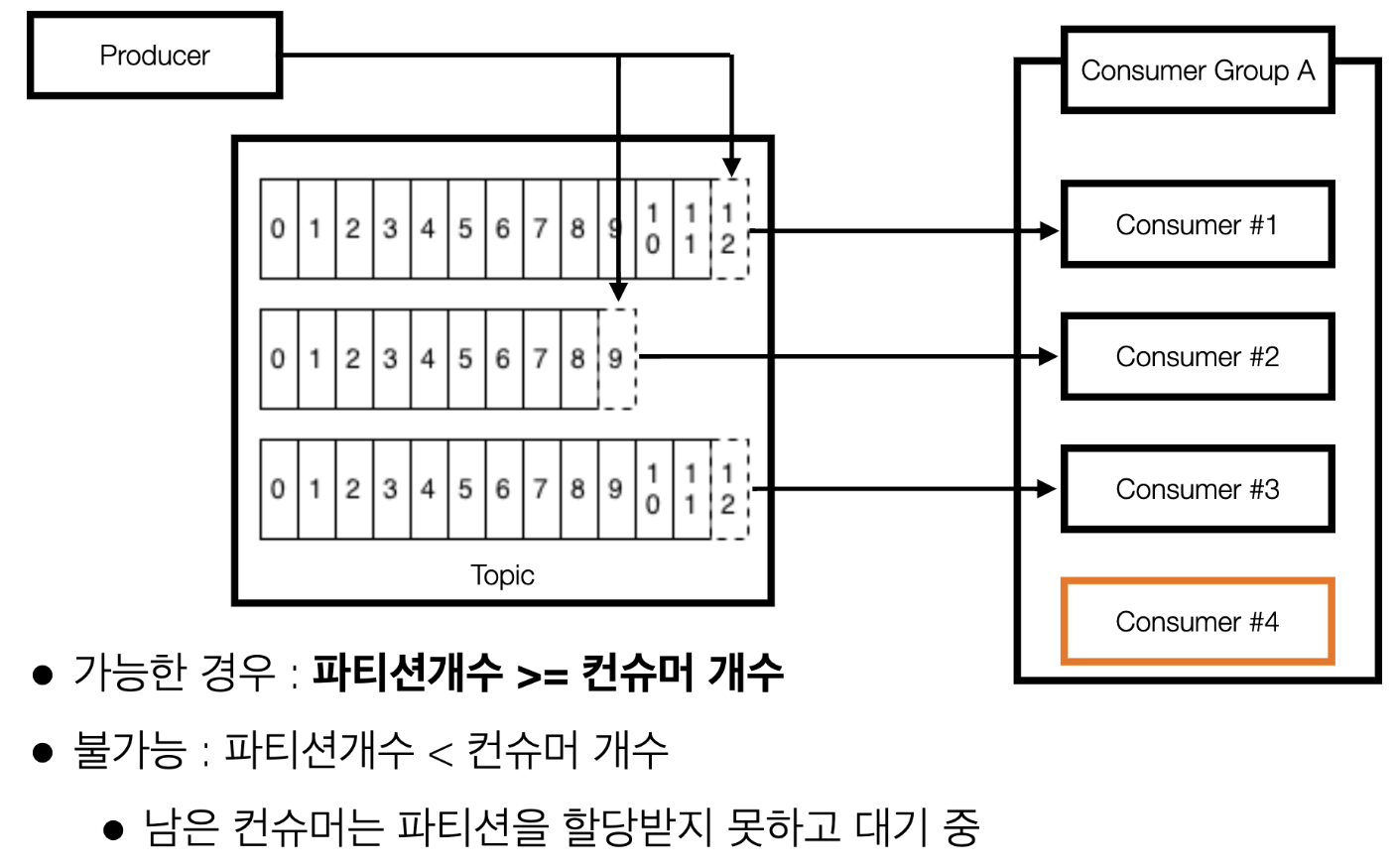
(예제3) 프로듀서 1개 <> 파티션이 3개인 토픽 <> 컨슈머가 4대인 경우 => 1대의 컨슈머가 놀게된다!!!
- (중요) 파티션갯수 >= 컨슈머갯수
- 즉, 파티션갯수보다 많은 컨슈머를 만들면 안된다.
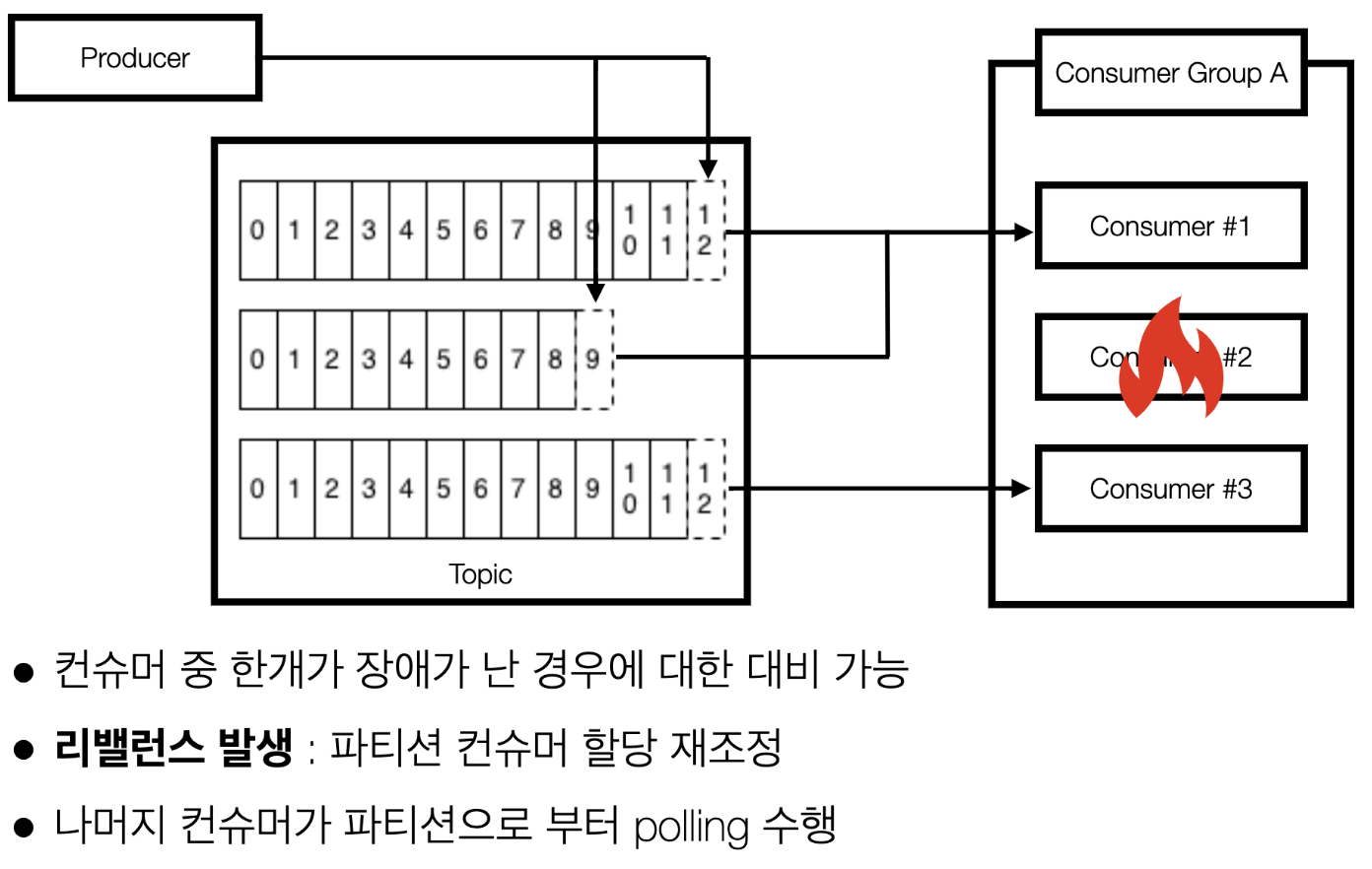
(예제4) 컨슈머 3대 중 1대가 장애가 났을 경우
(예제5) 2개 이상의 컨슈머 그룹이 있는 경우
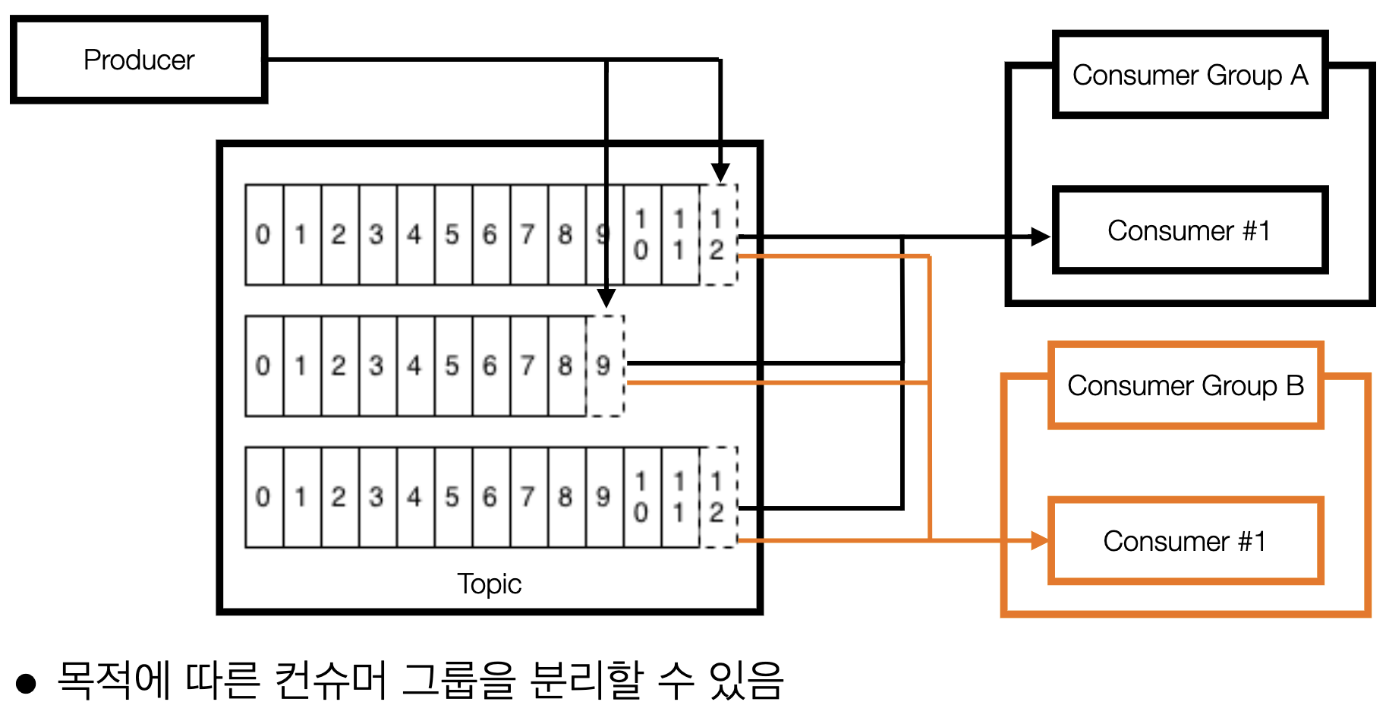
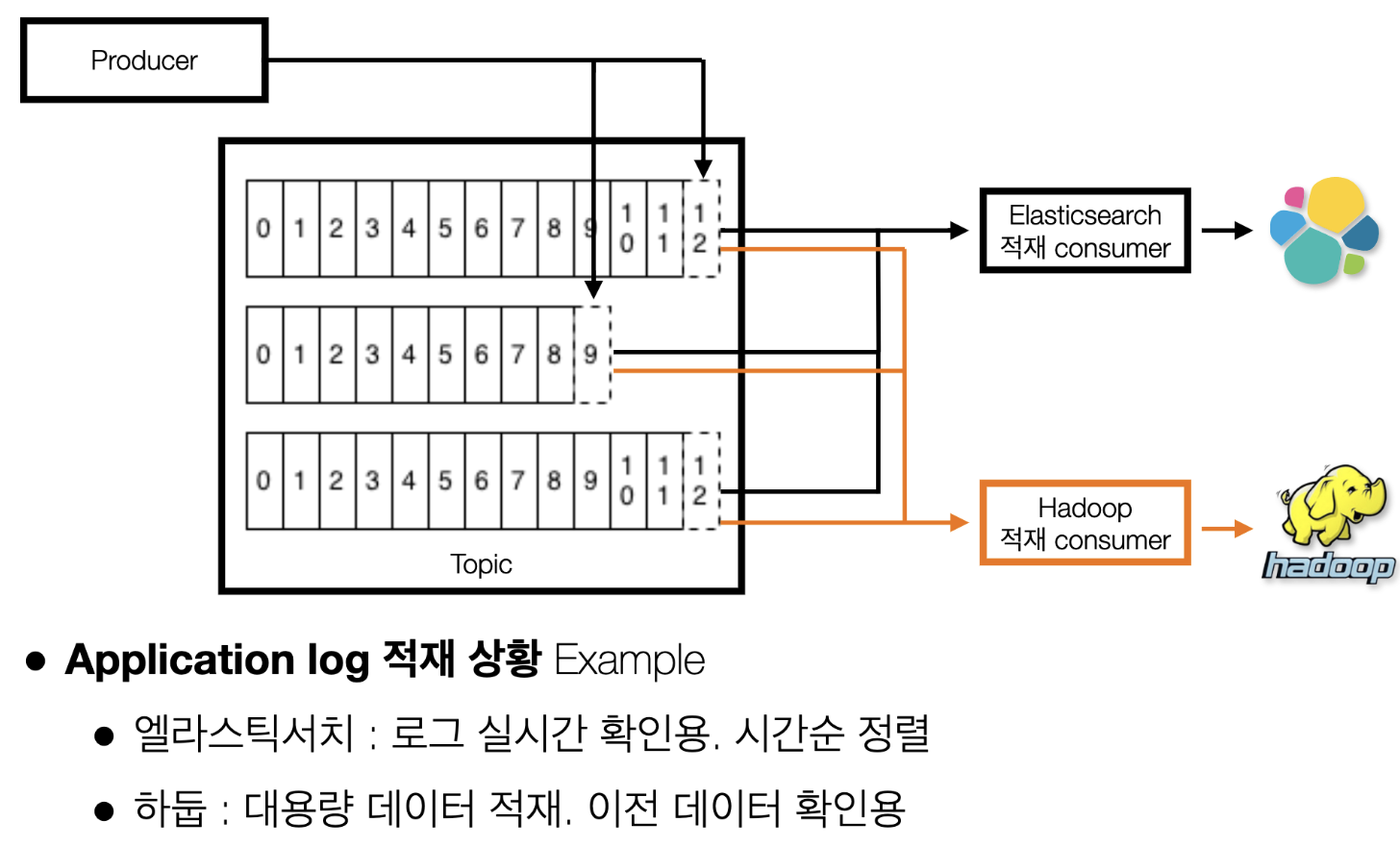
- 컨슈머 그룹 A에서 파티션 0번의 12번 데이터를 처리한 이후에도 컨슈머 그룹 B에서도 파티션 0번의 12번 데이터를 처리할 수 있음 <- 이게 카프카가 중추신경과 같은 역할을 할 수 있는 핵심적인 기능
- 장애에 대응하기 위해 재입수(또는 재처리) 목적으로 임시 신규 컨슈머 그룹을 생성하여 사용하기도 함
브로커 파티션 레플리케이션(Broker Partition Replication)
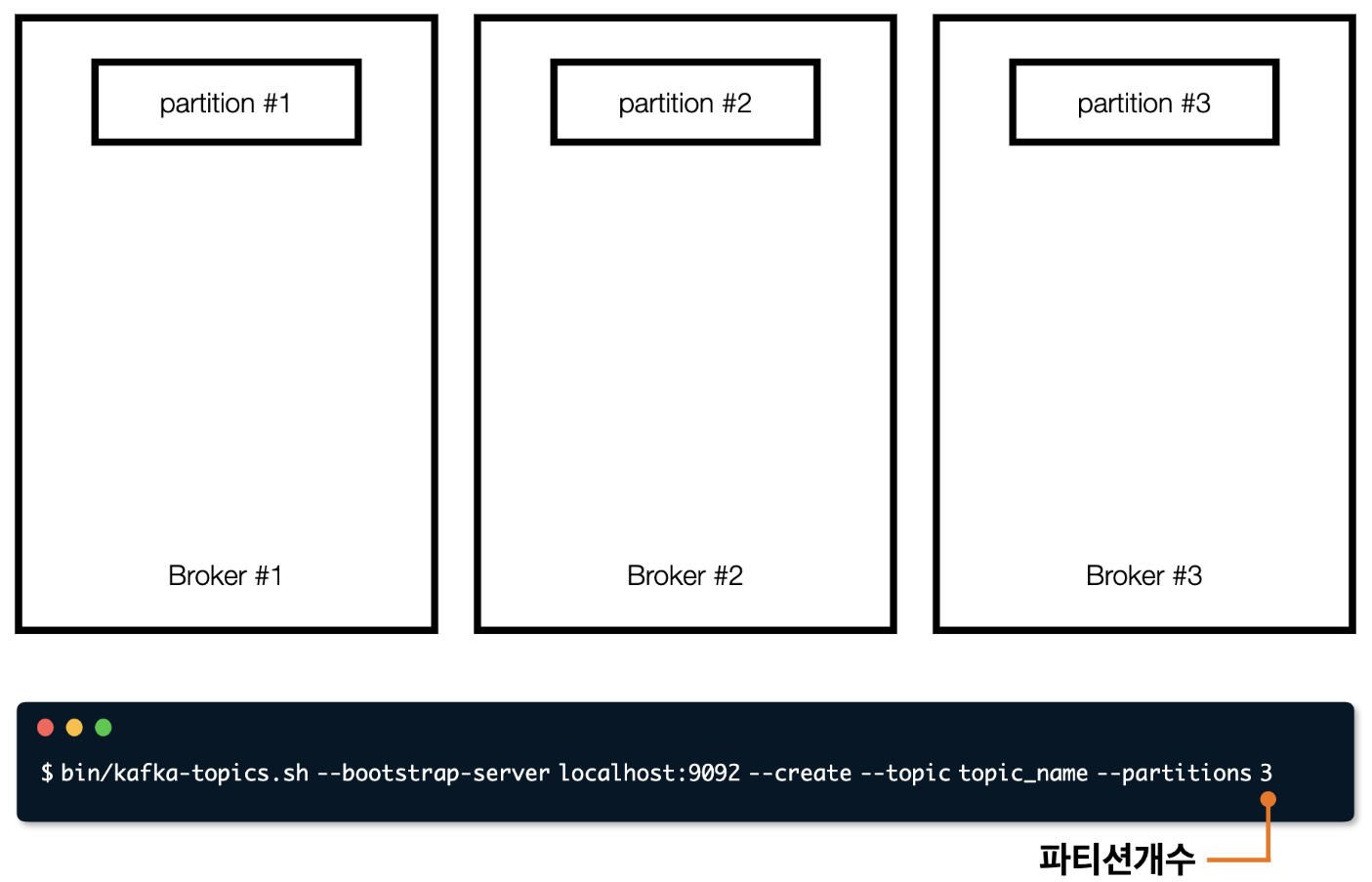
- 스샷의 명령어는 토픽을 생성하는 명령어인데, 이 명령어를 입력하면 스샷처럼 파티션 3개가 생김
bootstrap-server localhost:9092=> localhost:9092에 내리는 명령이라는 뜻
- (참고 : 링크)

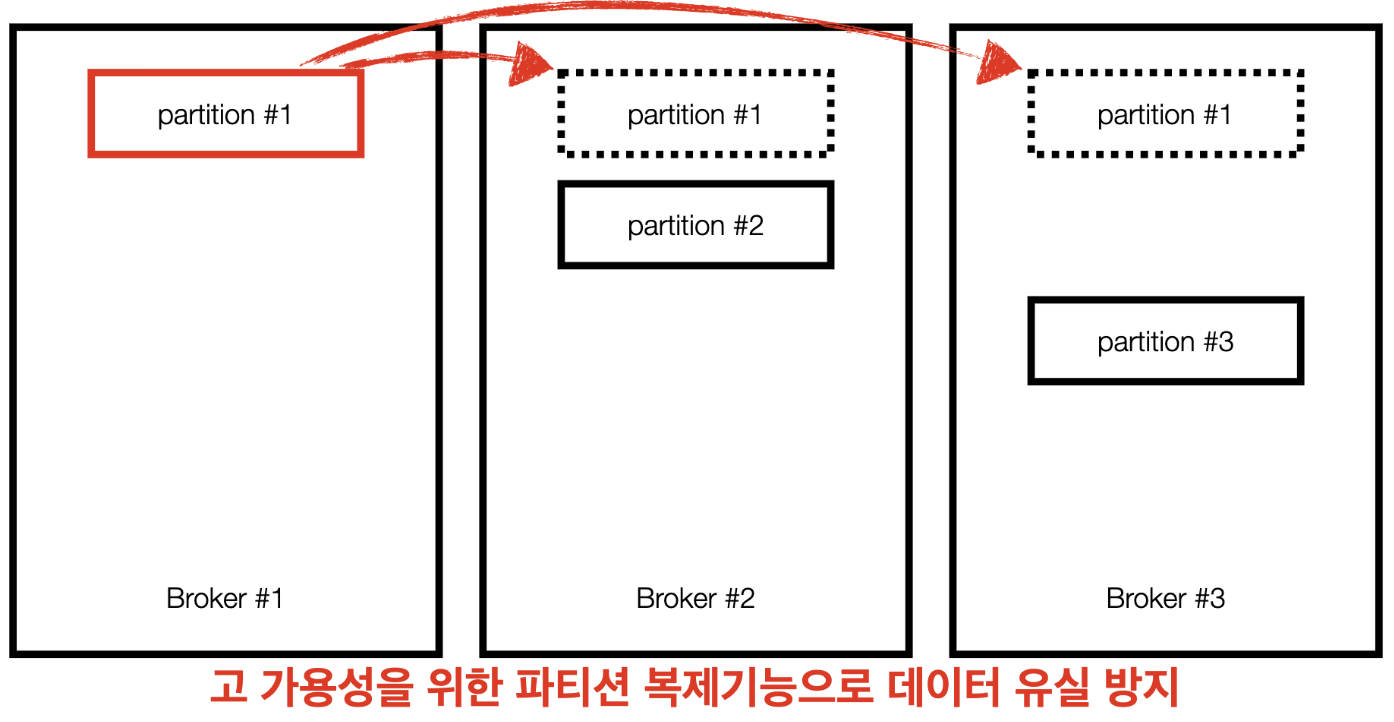
(상황) 카프카 브로커 이슈에 대응하기 위해 사용할 수 있는 방법은??
- 파티션을 다른 브로커에 복제하여 이슈에 대응가능
- 1번 브로커에 이슈가 생기면 다른 브로커에 복제된 데이터를 사용한다.

리더 파티션, 팔로워 파티션
- 기존에 사용하던 파티션을 "리더 파티션" 이라고 하고, 복제해서 사용하는 복제된 파티션을 "팔로워 파티션" 이라고 함
- 리더 파티션의 동작이 불가능할 경우 나머지 팔로워 중 1개가 리더 파티션이 됨
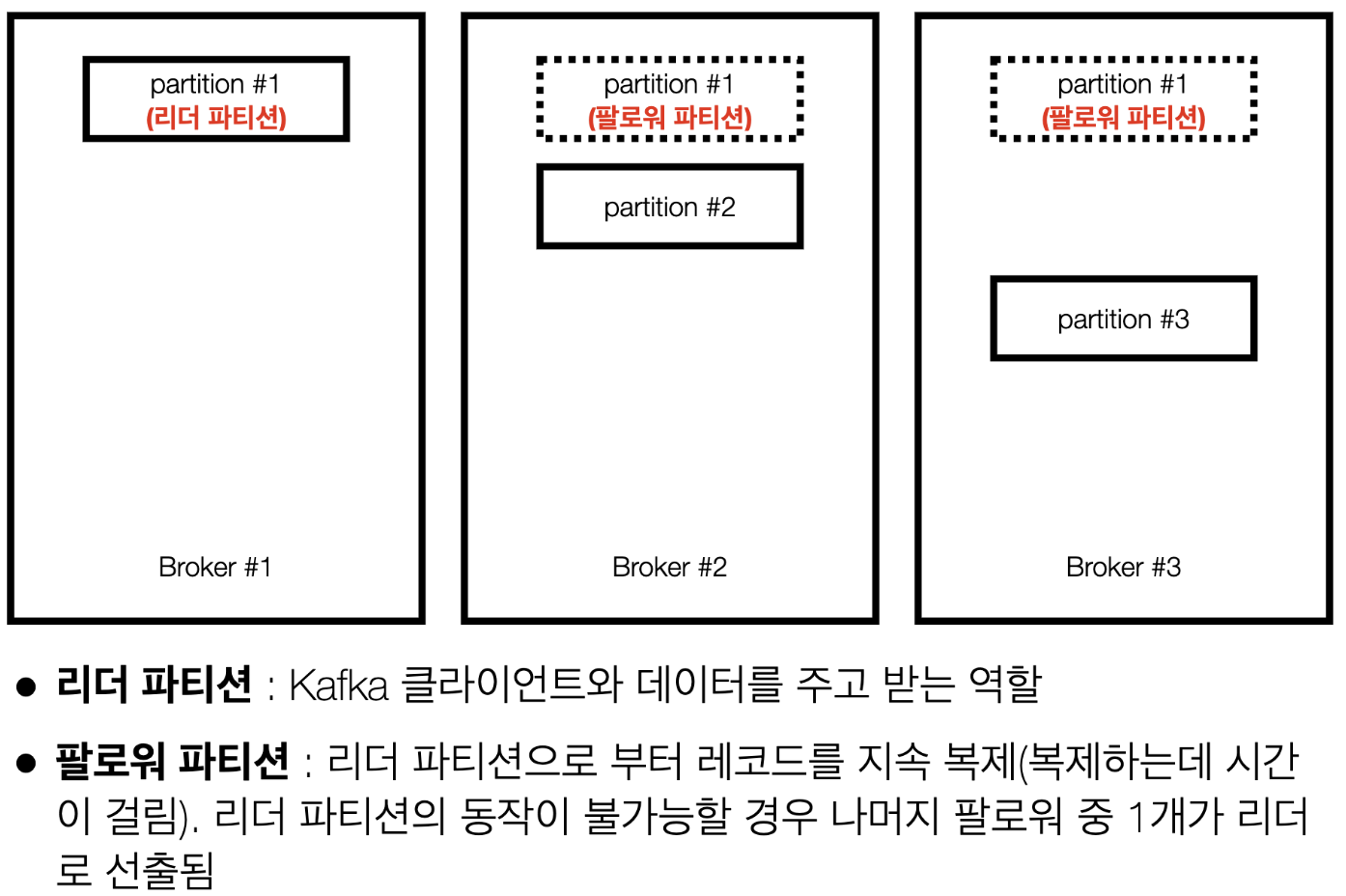
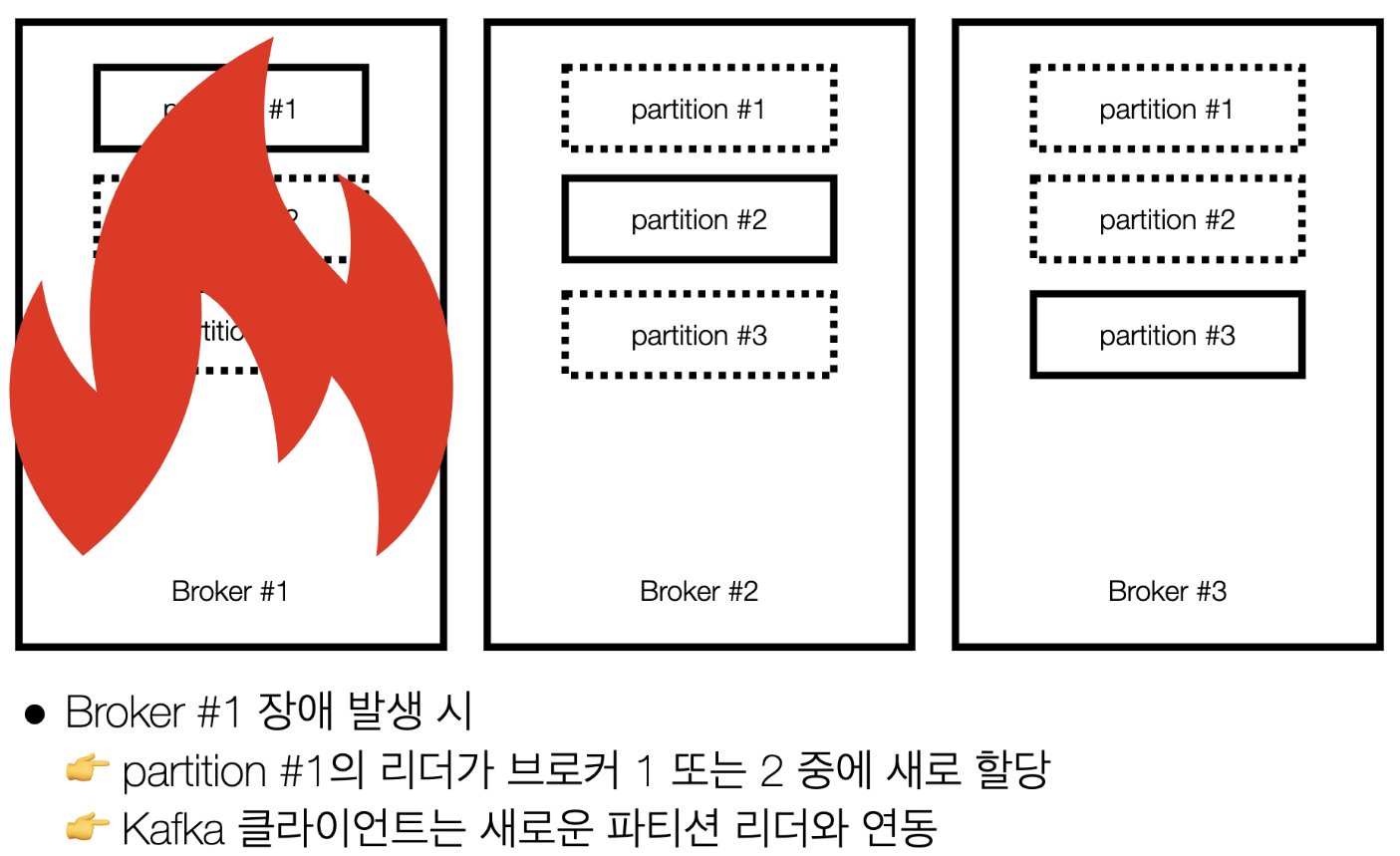
- 위에서 말하는 Kafka 클라이언트는 카프카 프로듀서/컨슈머 를 뜻함
ISR(In-Sync Replica), 리더와 팔로워의 싱크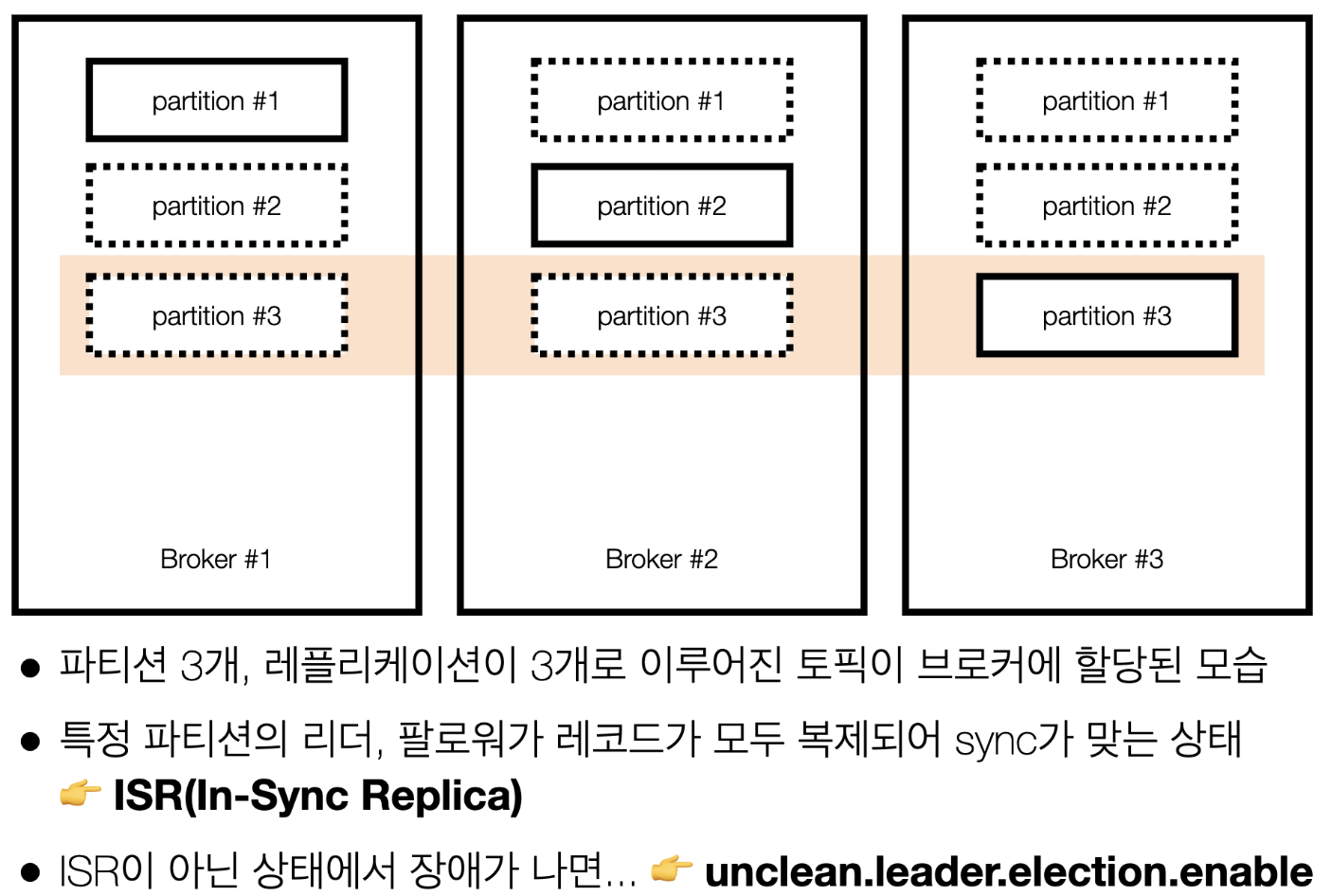
- ISR : 리더 파티션의 오프셋이 만약에 0~100번까지 있다고했을때, 나머지 팔로우 파티션도 오프셋 0~100번까지 모두 완벽하게 복제되어 있을때 ISR 상태라고 한다. = 모두 싱크가 되어있다는 뜻
unclean.leader.election.enable값이 False인 경우=> 예를 들어 3번 파티션의 리더 파티션이 있는 브로커 3번이 장애가 났고 0~100번 오프셋 까지 지니고있음 & 브로커1,2번에 복제된 파티션3번이 ISR상태가 아니면(0~90번 오프셋까지 가지고있음) 브로커 3번 복구될때까지 기다리라는 뜻True인 경우는 못가져온 91번~100번 오프셋까지 유실시키더라도 처리하라는 의미- 실제로 프로듀서/컨슈머가 작동안할때 이부분을 살펴봐야함
- 보통은
False로 둬서 브로커 3번이 복구될떄까지 기다리다가 작동안되는 경우가 많음
- 보통은
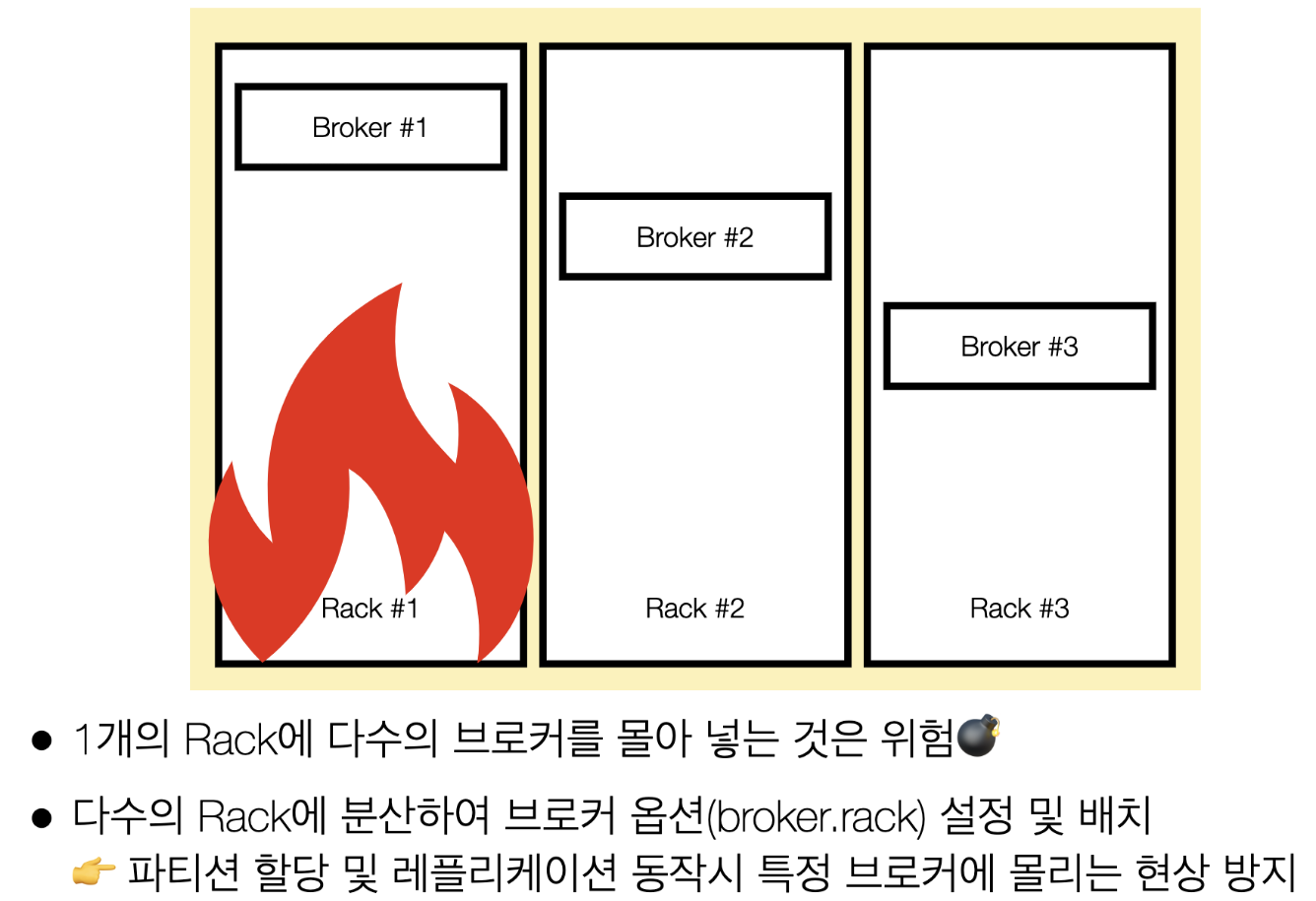
Kafka rack-awareness
- 서버 렉(Rack)과 서버
- 서버 렉이 내려가면 여러개의 서버가 한번에 내려감
- 이걸 방지하기위해서 Kafka rack-awareness 기능이 있음

- Kafka rack-awareness
주요개념 및 용어 정리
- 브로커(Broker) : 카프카 애플리케이션 서버 단위
- 프로듀서(Producer) : 레코드를 브로커로 전송하는 애플리케이션
- 컨슈머(Consumer) : 레코드를 polling하는 애플리케이션
- Consumer group: 다수 컨슈머 묶음
- Consumer offset: 특정 컨슈머가 가져간 레코드의 번호
- 토픽(Topic) 파티션(Partition) 오프셋(Offset)
- 파티션갯수보다 많은 컨슈머를 만들면 안된다.(파티션갯수 >= 컨슈머갯수)
- 토픽(Topic)
- 데이터가 보내지는 저장소 = 쉽게 생각하면 테이블과 유사하다고 생각하면 됨
- 토픽을 정하고 key를 적고 message를 보냄
- 데이터 분리 단위(파티션 하나생성되면 DB에서의 테이블이 하나 생성된다고 생각하면 됨)
- 토픽은 다수 파티션 보유
- 파티션(Partition) : 레코드를 담고 있음. 컨슈머 요청시 레코드 전달
- 오프셋(Offset) : 각 레코드당 파티션에 할당된 고유 번호
- Replication: 파티션 복제 기능
- ISR: 리더+팔로워 파티션의 sync가 된 묶음
- Rack-awareness : Server rack 이슈에 대응
- [카프카 브로커 여러개가 하나의 카프카 클러스터 이룸] <> [카프카 클라이언트(프로듀서 컨슈머)]
References
질문
- 보통 브로커 1개당 파티션 1개인가??
- 중추신경 카프카 부분에 프로듀서/컨슈머가 있는건지??

oneofakindscene