pipeline & StandardScaler
- 이 상태에서 cross validation 을 한다면 X_train 만 대상이 된다
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
wine = pd.read_csv(wine_url, index_col=0)
wine['taste'] = [1. if grade > 5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
sc = StandardScaler()
X_sc = sc.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_sc, y, test_size=0.2, random_state=13)quality에 대한 나머지 특정들의 상관관계
- 절댓값으로 비교해야 한다.(alcohol, density 등 관계가 높아 보인다.)
corr_matrix = wine.corr()
print(corr_matrix['quality'].sort_values(ascending=False))
'''
quality 1.000000
taste 0.814484
alcohol 0.444319
citric acid 0.085532
free sulfur dioxide 0.055463
sulphates 0.038485
pH 0.019506
residual sugar -0.036980
total sulfur dioxide -0.041385
fixed acidity -0.076743
color -0.119323
chlorides -0.200666
volatile acidity -0.265699
density -0.305858
Name: quality, dtype: float64
'''다양한 모델을 한 번에 테스트
from sklearn.ensemble import (AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier)
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
models = [] # 튜플형으로 추가
models.append(('RandomForestClassifier', RandomForestClassifier()))
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append(('LogisticRegression', LogisticRegression()))
# 결과 저장
from sklearn.model_selection import KFold, cross_val_score
results = []
names = []
for name, model in models:
kfold = KFold(n_splits=5, random_state=13, shuffle=True) # shuffle: 5개로 나누기 전에 섞기
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())
'''
RandomForestClassifier 0.8206585474198566 0.019351893580860268
DecisionTreeClassifier 0.7515863996446288 0.009186380636826795
AdaBoostClassifier 0.7533103205745169 0.02644765901536818
GradientBoostingClassifier 0.7663959428444511 0.021596556352125432
LogisticRegression 0.74273191678389 0.015548839626296565
'''cross validation 결과 확인
- RandomForest가 유리해 보이기는 하다.
fig = plt.figure(figsize=(14,8))
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show() 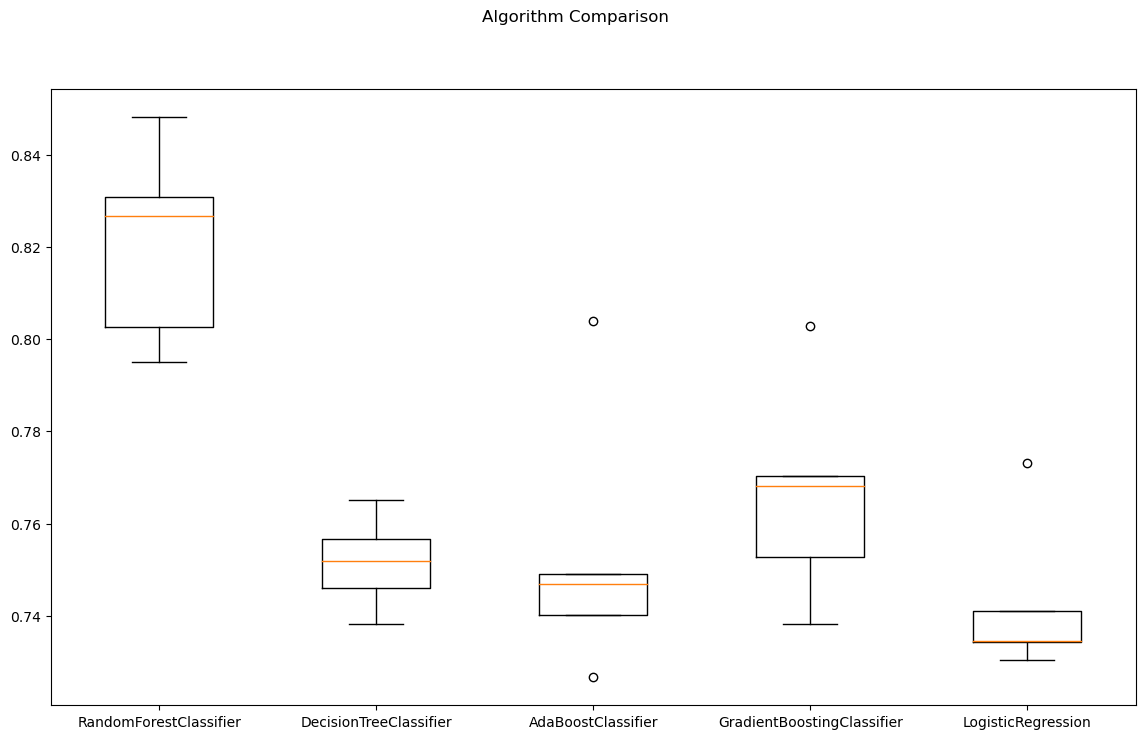
테스트 데이터에 대한 평가 결과
from sklearn.metrics import accuracy_score
for name, model in models:
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(name, accuracy_score(y_test, pred))
'''
RandomForestClassifier 0.8361538461538461
DecisionTreeClassifier 0.7776923076923077
AdaBoostClassifier 0.7553846153846154
GradientBoostingClassifier 0.7884615384615384
LogisticRegression 0.7469230769230769
'''Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it