1. 머신러닝
- 정의: 명시적인 프로그램에 의해서가 아니라, 주어진 데이터를 통해 규칙을 찾는 것
2. Decision Tree
Tree model visualization
- 장점: 특성을 파악하기 좋다.
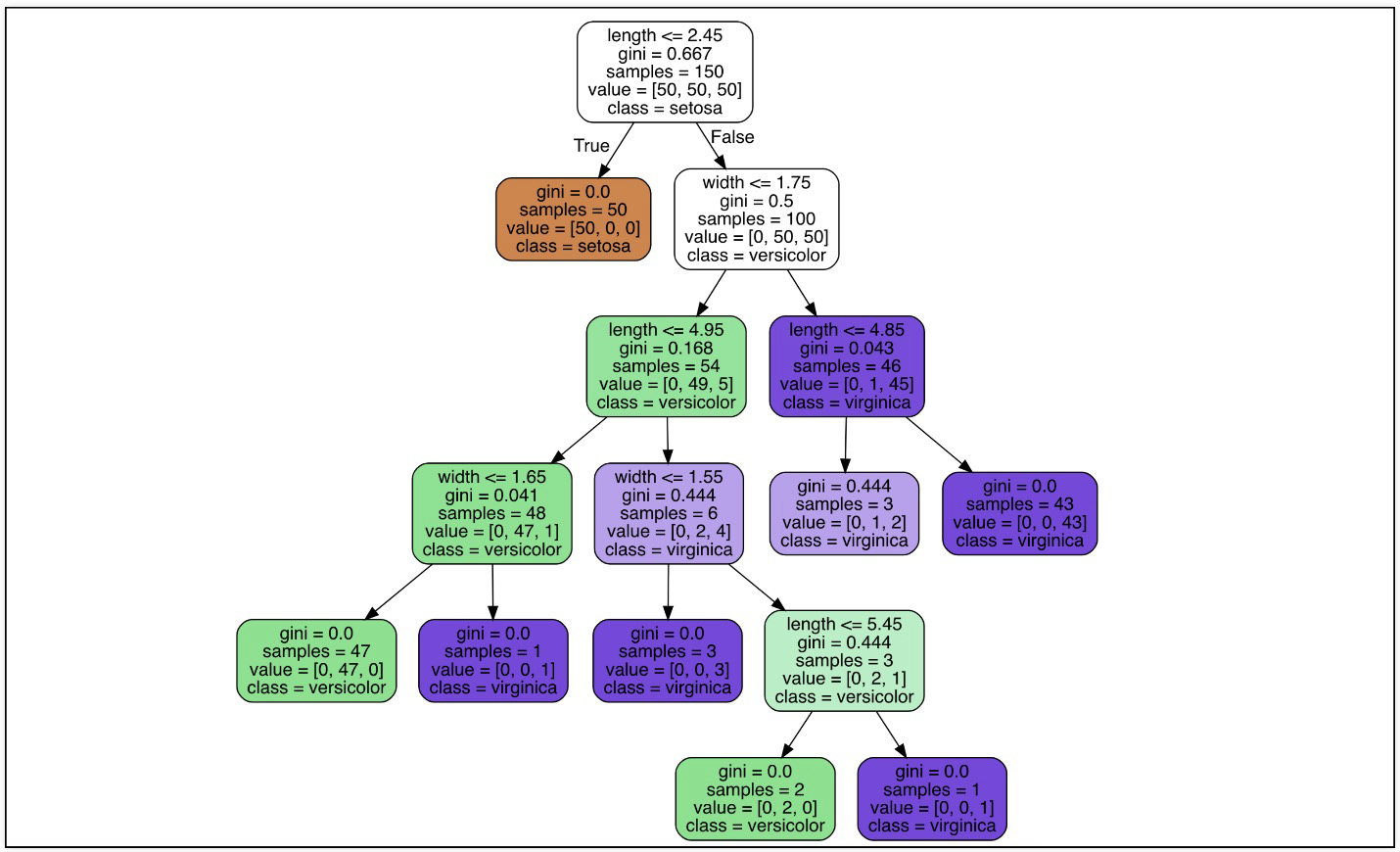
Decision Tree의 분할 기준 (Split Criterion)
-
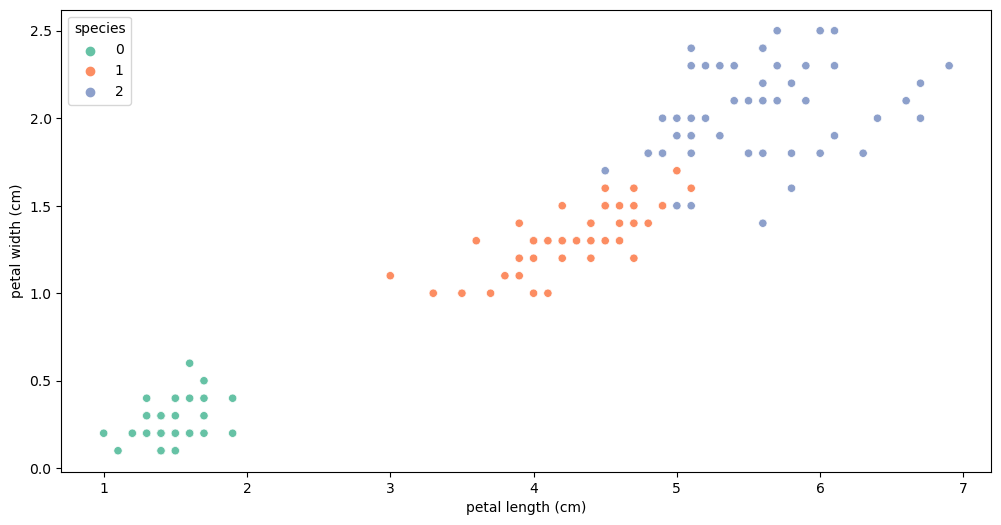
예시) iris 3종으로 나누기(setosa, versicolor, virginica)
-
petal length > 2.5 기준: setosa vs versicolor, virginica
-
versicolor, virginica은 어떤 기준으로?
정보 획득 Information Gain
- 정보의 가치를 반환하는 데 발생하는 사건의 확률이 작을수록 정보의 가치는 커진다
- 정보 이득이란 어떤 속성을 선택함으로 인해서 데이터를 더 잘 구분하게 되는 것
엔트로피
- 정보의 양 & 무질서도(disorder) & 불확실성(uncertainty)을 의미
- p는 해당 데이터가 해당 클래스에 속할 확률이다. 어떤 확률 분포로 일어나는 사건을 표현하는 데 필요한 정보의 양이며 이 값이 커질수록 확률 분포의 불확실성이 커지며 결과에 대한 예측이 어려워진다.
지니계수
- Gini index 혹은 불순도율
- 엔트로피의 계산량이 많아서 비슷한 개념이면서 보다 계산량이 적은 지니계수를 사용하는 경우가 많다.
- 분할해서 지니계수가 낮아지면 그 경우를 선택한다. 나누지 않는 경우도 존재하나 그에 따른 근거도 필요하다.
3. Scikit Learn
결정나무모델
- fit(내용, 정답) -> 학습하라는 의미
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()
iris_tree.fit(iris.data[:, 2:], iris.target)정확도
- predict(데이터) -> 예측, 추론하라
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
accuracy_score(iris.target, y_pred_tr)4. 과적합
- 지도학습: 학습 대상이 되는 데이터에 정답(label)을 붙여서 학습 시키고 모델을 얻어서 완전히 새로운 데이터에 모델을 사용해서 “답”을 얻고자 하는 것
- 과적합: 기계 학습 모델이 학습 데이터에 대한 정확한 예측을 제공하지만 새 데이터에 대해서는 제공하지 않을 때 발생하는 바람직하지 않은 기계 학습 동작(모델이 학습 데이터에만 과도하게 최적화된 현상. 그로 인해 일반화된 데이터에서는 예측 성능이 과하게 떨어지는 현상)
- 발생이유?
- 훈련 데이터 크기가 너무 작고 가능한 모든 입력 데이터 값을 정확하게 나타내기에 충분한 데이터 샘플을 포함하지 않을 때
- 훈련 데이터에는 노이즈 데이터라고 하는 관련 없는 정보가 많이 포함되어 있을 때
- 모델이 단일 샘플 데이터 세트에서 너무 오래 훈련할 때
- 모델 복잡도가 높기 때문에 훈련 데이터 내의 노이즈를 학습할 때
- 보통 본인이 가진 유한한 데이터를 가지고 일반화를 추구하게 된다. 그래서 복잡한 경계면은 유한한 데이터에 적합할 뿐 일반화하기에는 어려워 모델의 성능을 낮추게 한다.
→ 과적합 감지: 교차 검증
결정 경계
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=iris.data[:,2:], y=iris.target, clf=iris_tree, legend=2)
plt.show()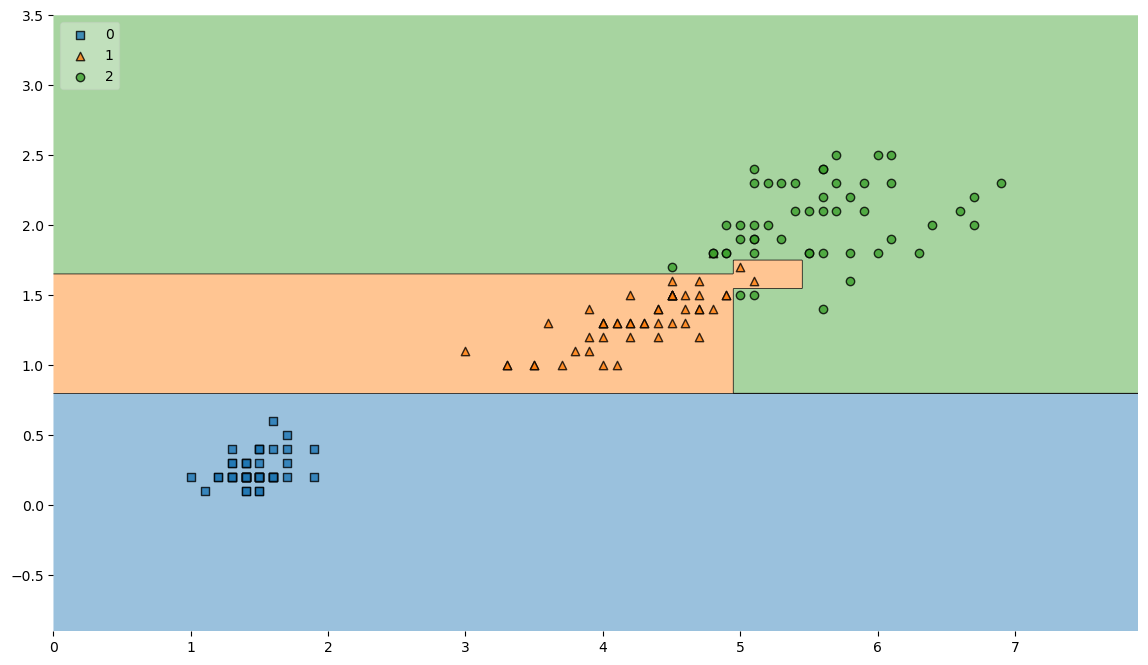
5. 데이터 분리
- 데이터의 분리 (훈련 / 검증 / 평가)

테이터 분리
- test_size: 테스트 비율
- stratify: 동일 비율로 나누어줌
- random_state: random하게 추출
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
feature = iris.data[:, 2:]
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(feature, labels, test_size=0.2, stratify=labels, random_state=13)train decisionTree 결정나무모델
- 학습할 때 마다 일관성을 위해 random_state만 고정
- 모델을 단순화시키기 위해 max_depth를 조정
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(iris_tree)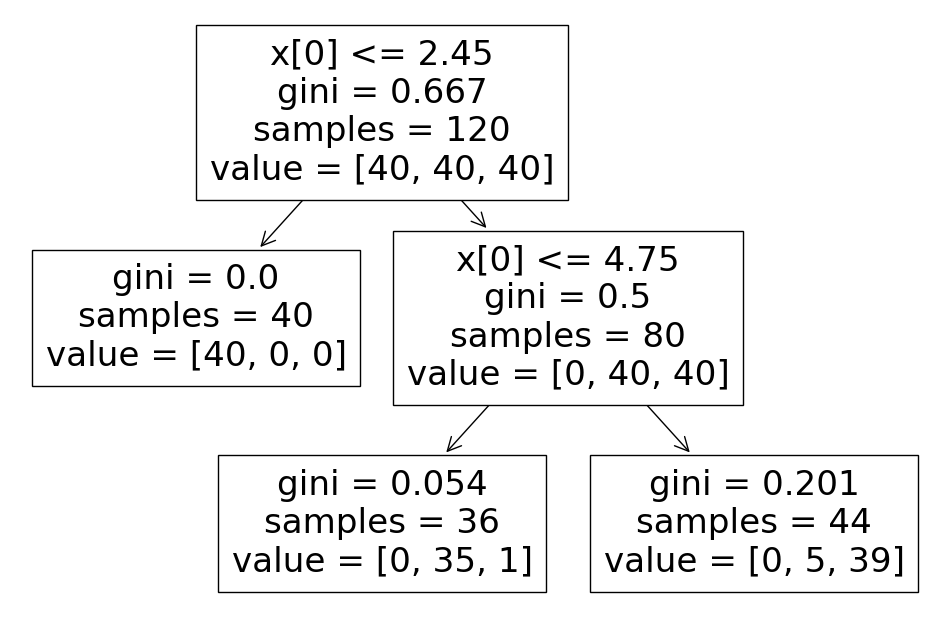
train 데이터에 대한 accuracy 확인
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(X_train)
accuracy_score(y_train, y_pred_tr)train 데이터에 대한 결정경계
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2)
plt.show()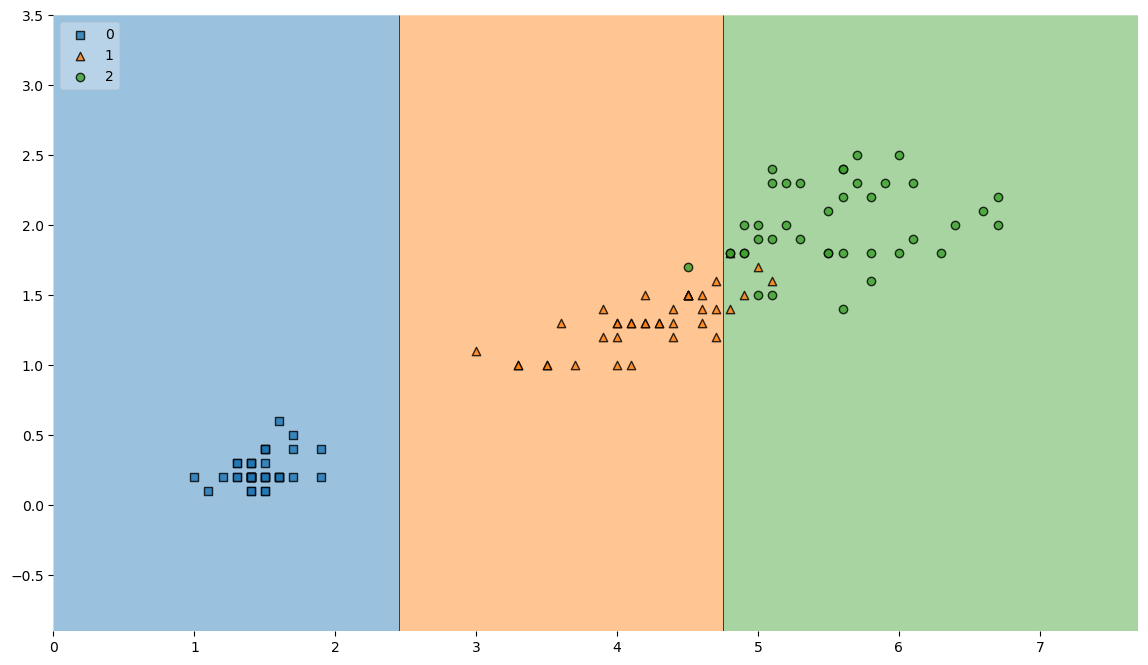
테스트 데이터에 대한 accuracy
y_pred_tr = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_tr)
# 0.9666666666666667전체 데이터
scatter_highlight_kwargs = {'s':150, 'label':'Test data', 'alpha':0.9}
scatter_kwargs = {'s':120, 'edgecolor': None, 'alpha':0.7}
plt.figure(figsize=(12,8))
plot_decision_regions(X=feature, y=labels, X_highlight=X_test, clf=iris_tree, legend=2,
scatter_highlight_kwargs=scatter_highlight_kwargs,
scatter_kwargs=scatter_kwargs,
contour_kwargs={'alpha':0.2})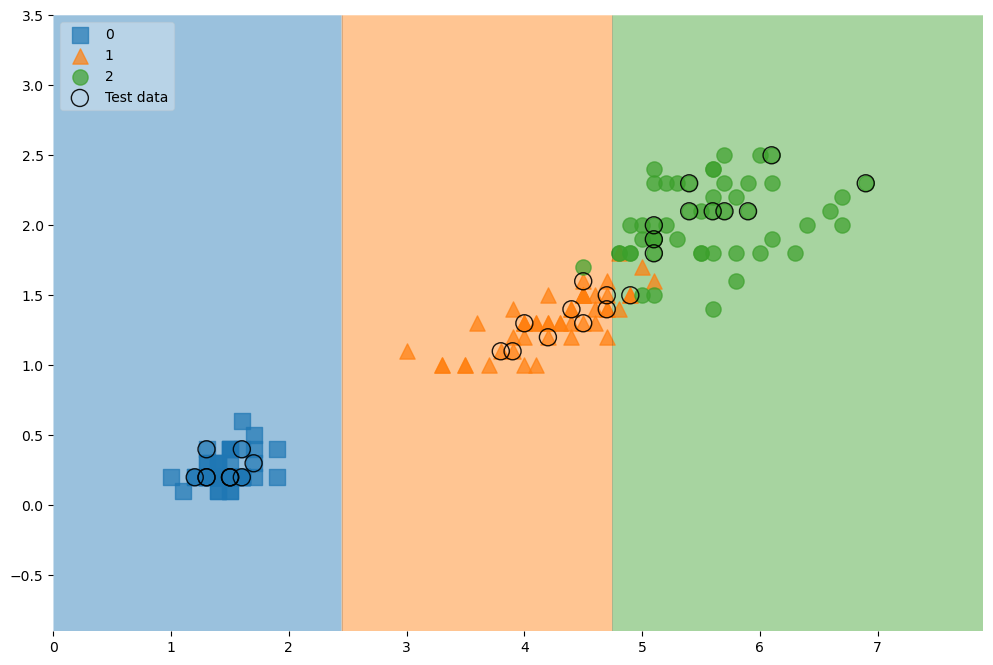
전체 특성 결정 나무 모델
features = iris.data
label = iris.target
X_train, X_test, y_train, y_test = train_test_split(features, label, test_size=0.2, stratify=labels, random_state=13)
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
plt.figure(figsize=(12,8))
plot_tree(iris_tree)모델 사용하기
test_data = [[4.3, 2., 1.2, 1.0]]
# 범주 값
iris.target_names[iris_tree.predict(test_data)]
# 클래스별 확률
iris_tree.predict_proba(test_data)zip
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
pairs = [pair for pair in zip(list1, list2)]
# [(1, 'a'), (2, 'b'), (3, 'c')]
dict(pairs)
# {1: 'a', 2: 'b', 3: 'c'}
dict(zip(list1, list2))
# {1: 'a', 2: 'b', 3: 'c'}unpacking
a, b = (*pairs)
a = (1, 2, 3)
b = ('a', 'b', 'c')Reference
1) 제로베이스 데이터스쿨 강의자료
2) https://aws.amazon.com/ko/what-is/overfitting/

데이터 사이언스 / just do it