와인데이터
wine = pd.read_csv(wine_url, index_col=0)
wine['taste'] = [ 1. if grade > 5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']데이터 분리, 간단 로지스틱 회귀 테스트
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score # 분류 회귀라서 accuracy_score가능
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
lr = LogisticRegression(solver='liblinear', random_state=13) # 최적화 알고리즘
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print('Train Acc: ', accuracy_score(y_train, y_pred_tr)) # Train Acc: 0.7425437752549547
print('Test Acc: ', accuracy_score(y_test, y_pred_test)) # Test Acc: 0.7438461538461538스케일러 & 파이프라인
- 결정나무에서는 영향이 별로 없었던 scaler이지만 accuracy 상승효과가 있긴 하다.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()), ('clf', LogisticRegression(solver='liblinear', random_state=13))]
pipe = Pipeline(estimators)
pipe.fit(X_train, y_train)
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print('Train Acc: ', accuracy_score(y_train, y_pred_tr)) # Train Acc: 0.7444679622859341
print('Test Acc: ', accuracy_score(y_test, y_pred_test)) # Test Acc: 0.7469230769230769Decision Tree vs LogisticRegression AUC 그래프
- 분류회귀가 조금 더 좋음
- ROC & AUC 설명
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_curve
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
models = {'logistic regression':pipe, 'decission tree':wine_tree}
plt.figure(figsize=(10, 8))
plt.plot([0,1], [0,1])
for model_name, model in models.items():
pred = model.predict_proba(X_test)[:, 1] # 0일 확률, 1일 확률에서 1일 확률값만 선택
fpr, tpr, thresholds = roc_curve(y_test, pred)
plt.plot(fpr, tpr, label=model_name)
plt.grid()
plt.legend()
plt.show() 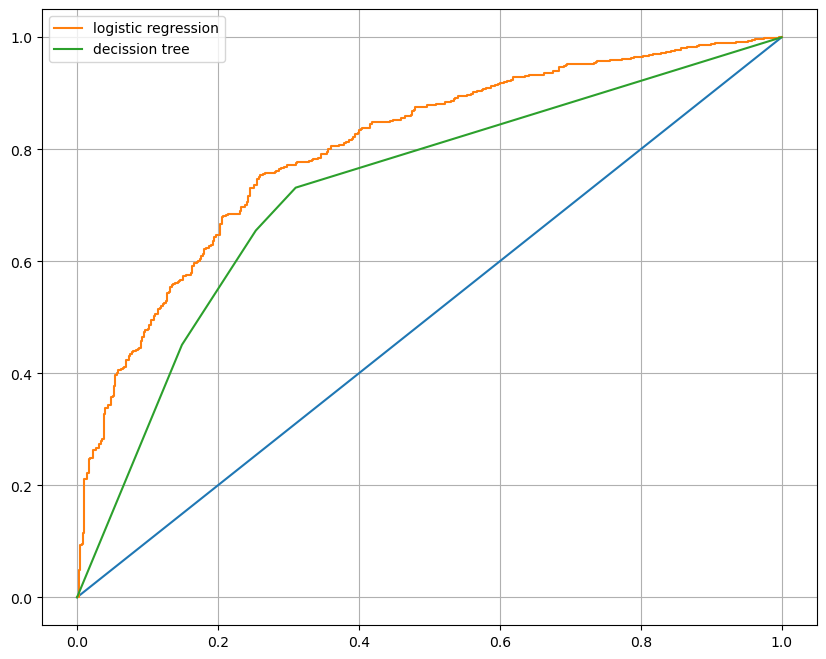
Reference
1) 제로베이스 데이터 스쿨 강의자료

데이터 사이언스 / just do it