1. 가상 데이터
import & set seed
import tensorflow as tf
import matplotlib.pyplot as plt
tf.random.set_seed(777)가상 데이터셋 & 모양 확인
W_true = 3.0
B_true = 2.0
X = tf.random.normal((500, 1))
noise = tf.random.normal((500, 1))
y = X * W_true + B_true + noise
plt.scatter(X, y)
plt.show()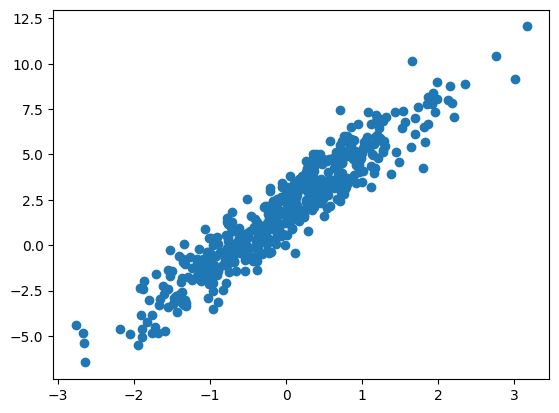
학습 & 그래프
w = tf.Variable(5.)
b = tf.Variable(0.)
lr = 0.03
w_records = []
b_records = []
loss_records = []
for epoch in range(100):
# 매 epoch 한 번씩 학습
with tf.GradientTape() as tape:
y_hat = X * w + b
loss = tf.reduce_mean(tf.square(y- y_hat))
w_records.append(w.numpy())
b_records.append(b.numpy())
loss_records.append(loss.numpy())
dw, db = tape.gradient(loss, [w, b])
w.assign_sub(lr*dw) # 기존값에서 마이너스
b.assign_sub(lr*db)
plt.plot(loss_records)
plt.title('loss')
plt.show()
plt.plot(w_records)
plt.title('w')
plt.show()
plt.plot(b_records)
plt.title('b')
plt.show()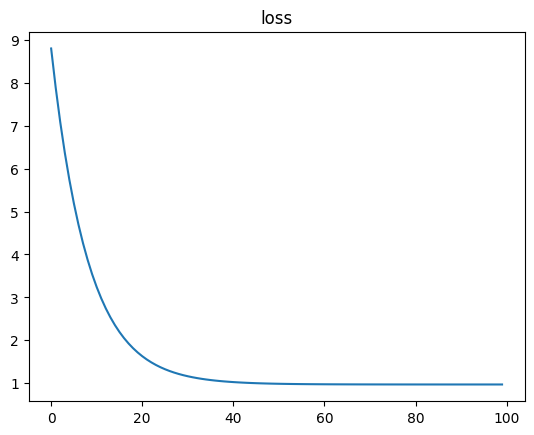 | 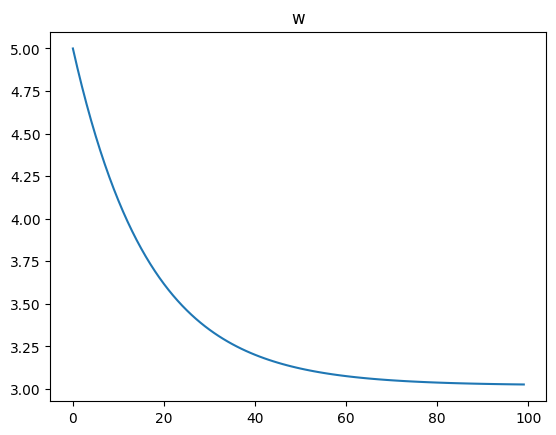 | 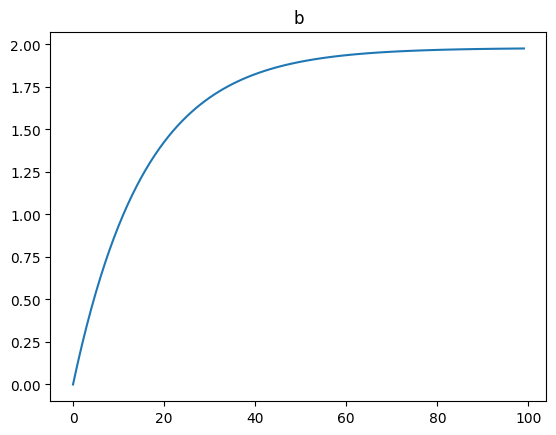 |
|---|
2. 당뇨병
를 Feature, ,를 가중치 벡터, 를 Target이라고 할 때,
의 역행령이 존재 한다고 가정했을 때,
아래의 식을 이용해 의 추정치 를 구하기.
dataset
from sklearn.datasets import load_diabetes
import pandas as pd
import numpy as np
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names, dtype=np.float32)
df['const'] = np.ones(df.shape[0])예측, 실제 비교
# shape 확인
df.shape # (442, 11)
diabetes.target.shape # (442, )
X = df
y = np.expand_dims(diabetes.target, axis=1).astype(np.float32) # 한 차원 늘려줌
XT = tf.transpose(X)
w = tf.matmul(tf.matmul(tf.linalg.inv(tf.matmul(XT, X)), XT), y)
y_pred = tf.squeeze(tf.matmul(X, w), axis=1)
print("예측한 진행도 :", y_pred[31].numpy(), "실제 진행도 :", diabetes.target[31]) # 예측한 진행도 : 69.47575835406316 실제 진행도 : 59.0SGD
- Conditions
- steepest gradient descents(전체 데이터 사용)
- 가중치는 Gaussian normal distribution에서의 난수로 초기화함.
- step size == 0.03
- 100 iteration
lr = 0.03
num_iter = 100
# dtype 확인
X.dtypes
# 11개 feature를 1개로
# 맞춰야 오류 발생 x
w_init = tf.random.normal([df.shape[1], 1], dtype=tf.float64)
w = tf.Variable(w_init)
for i in range(num_iter):
with tf.GradientTape() as tape:
y_hat = tf.matmul(X, w)
loss = tf.reduce_mean((y_hat - y)**2)
dw = tape.gradient(loss, w)
w.assign_sub(lr * dw)Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it