1. 앙상블
- Ensemble: 여러 개의 분류기(약한 분류기)를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법
- 이유:
- 머신러닝이 세부적으로 학습을 할 수록 과적합(Overfitting) 현상이 발생하는데 이를 해결
- 세부적으로 학습하지 않으면 예측 성능이 떨어지는 과소적합 현상 발생하는데 이 문제 또한 해결
- 종류: voting, bagging, boosting
- 현재 정형데이터를 대상으로 하는 분류기에서 앙상블 기법이 좋은 성과를 보여준다.
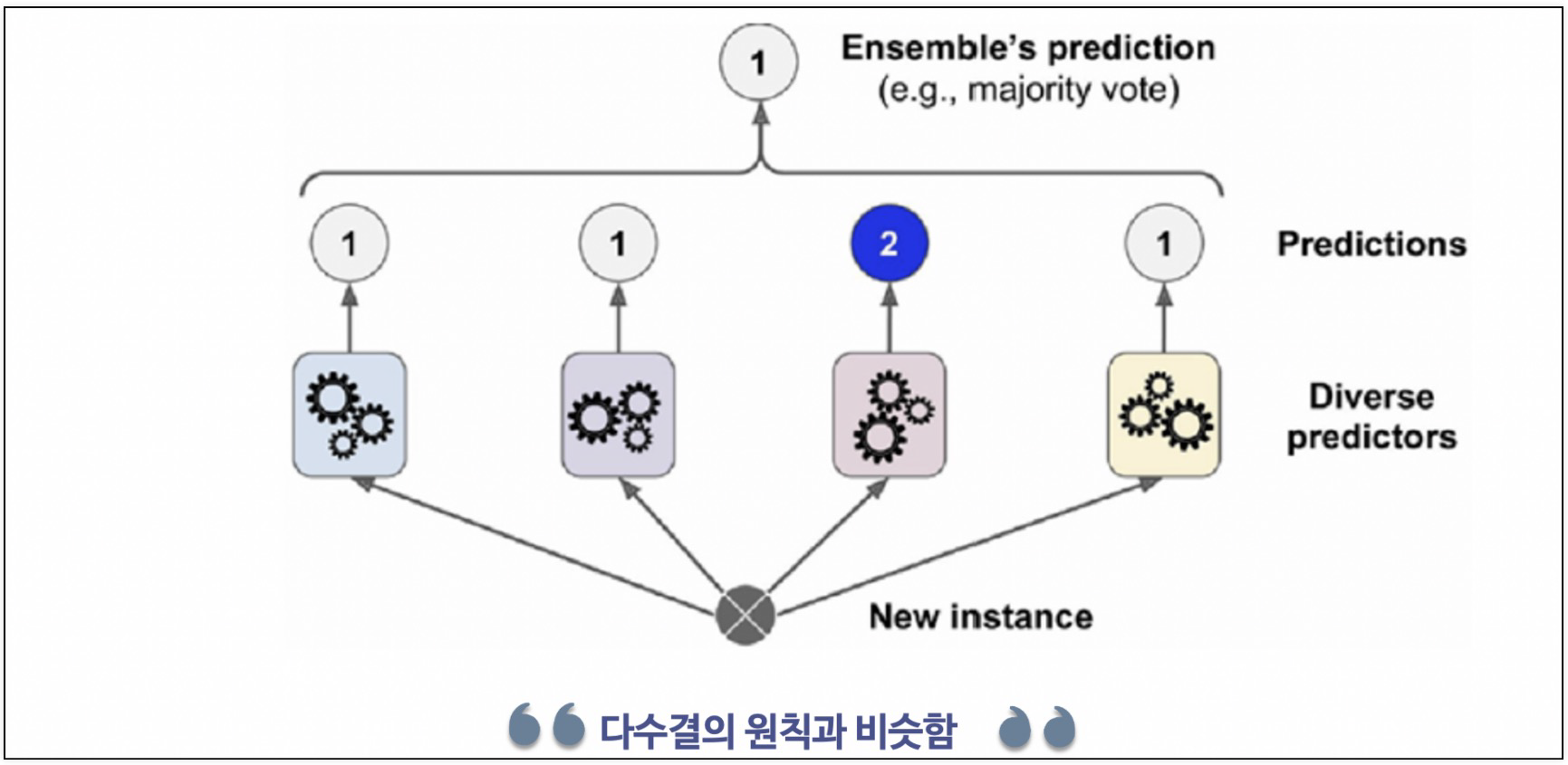
2. Voting
- 각각 다른 알고리즘을 이용한 분류기를 결합하는 방식으로 최종 예측 값을 투표하는 방식
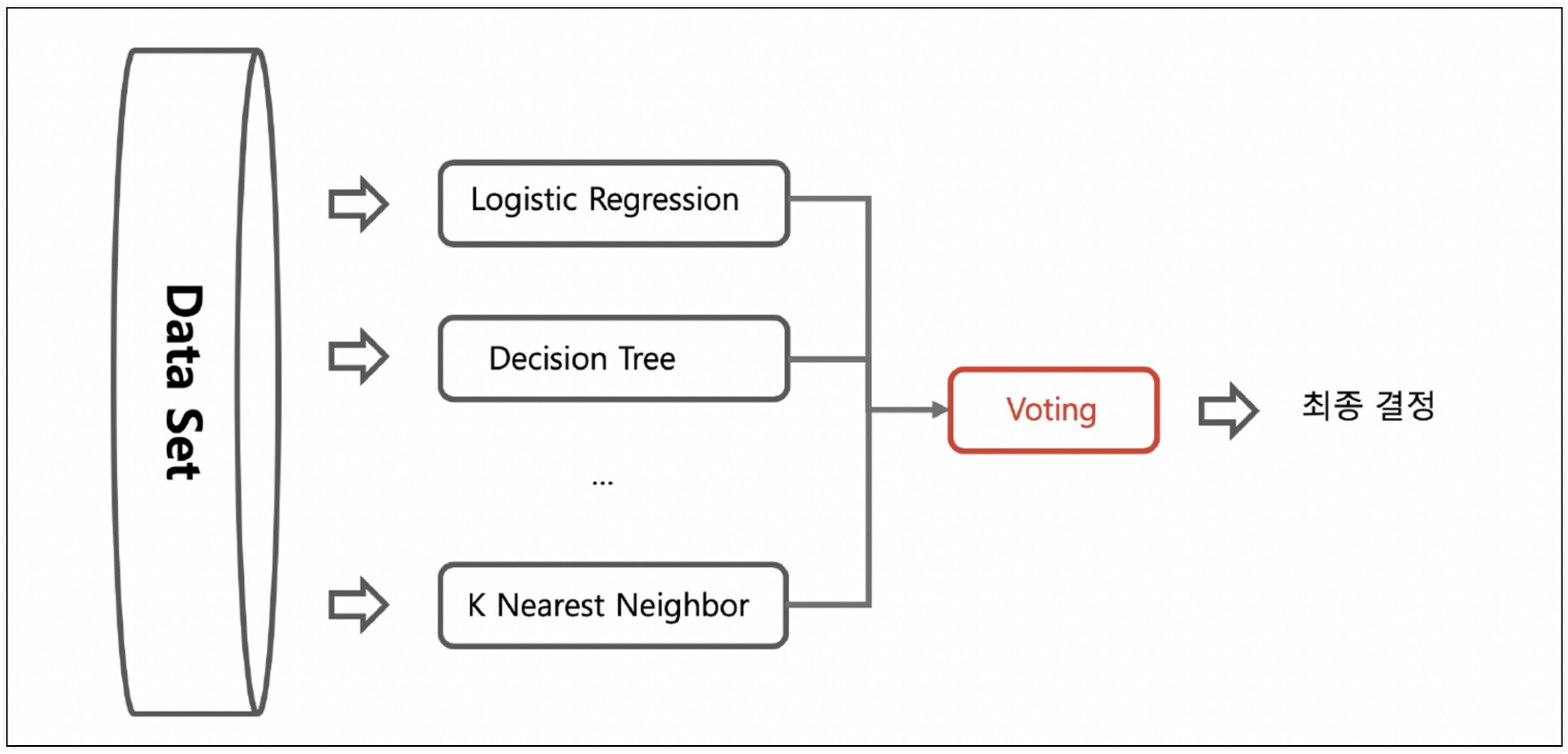
- soft voting
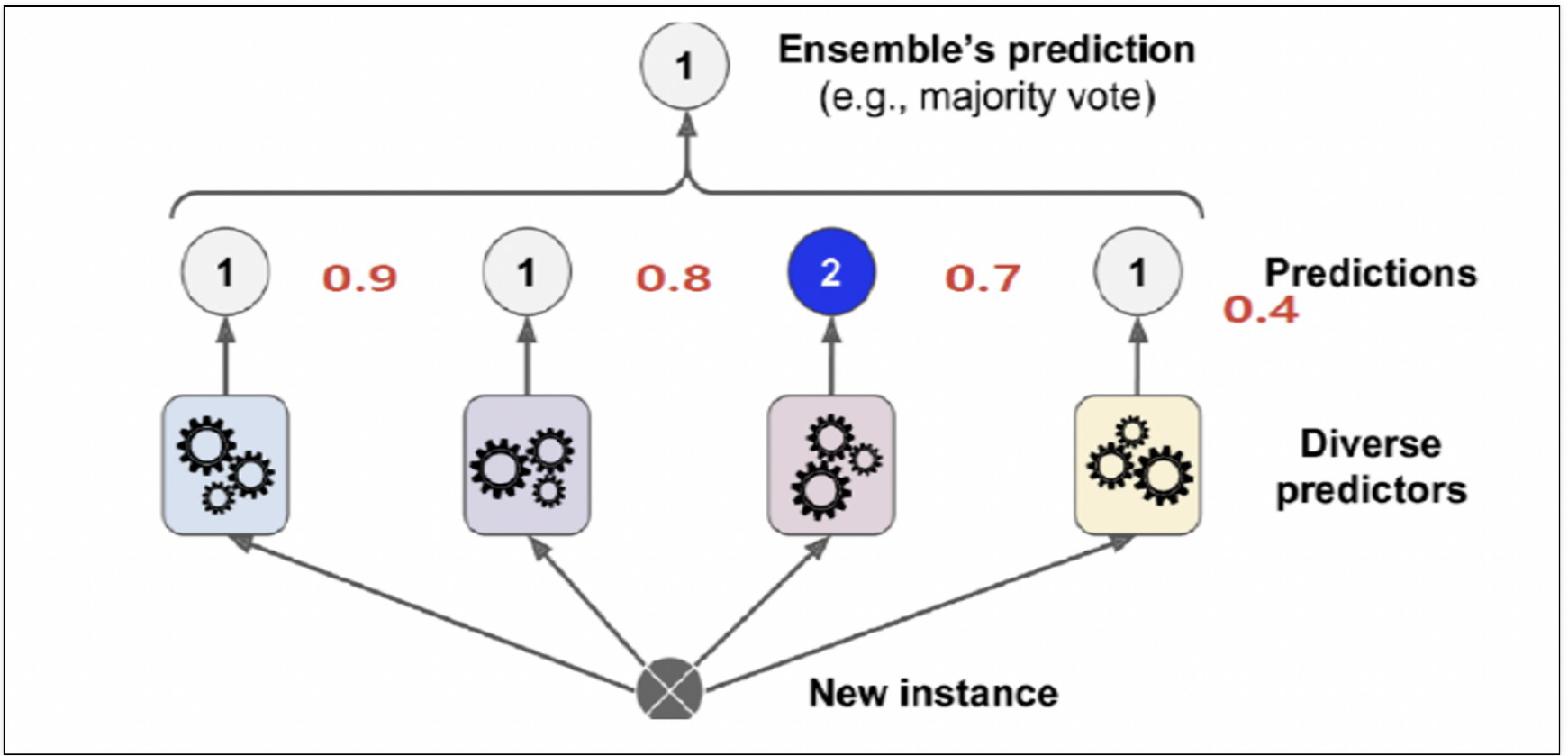
- hard voting
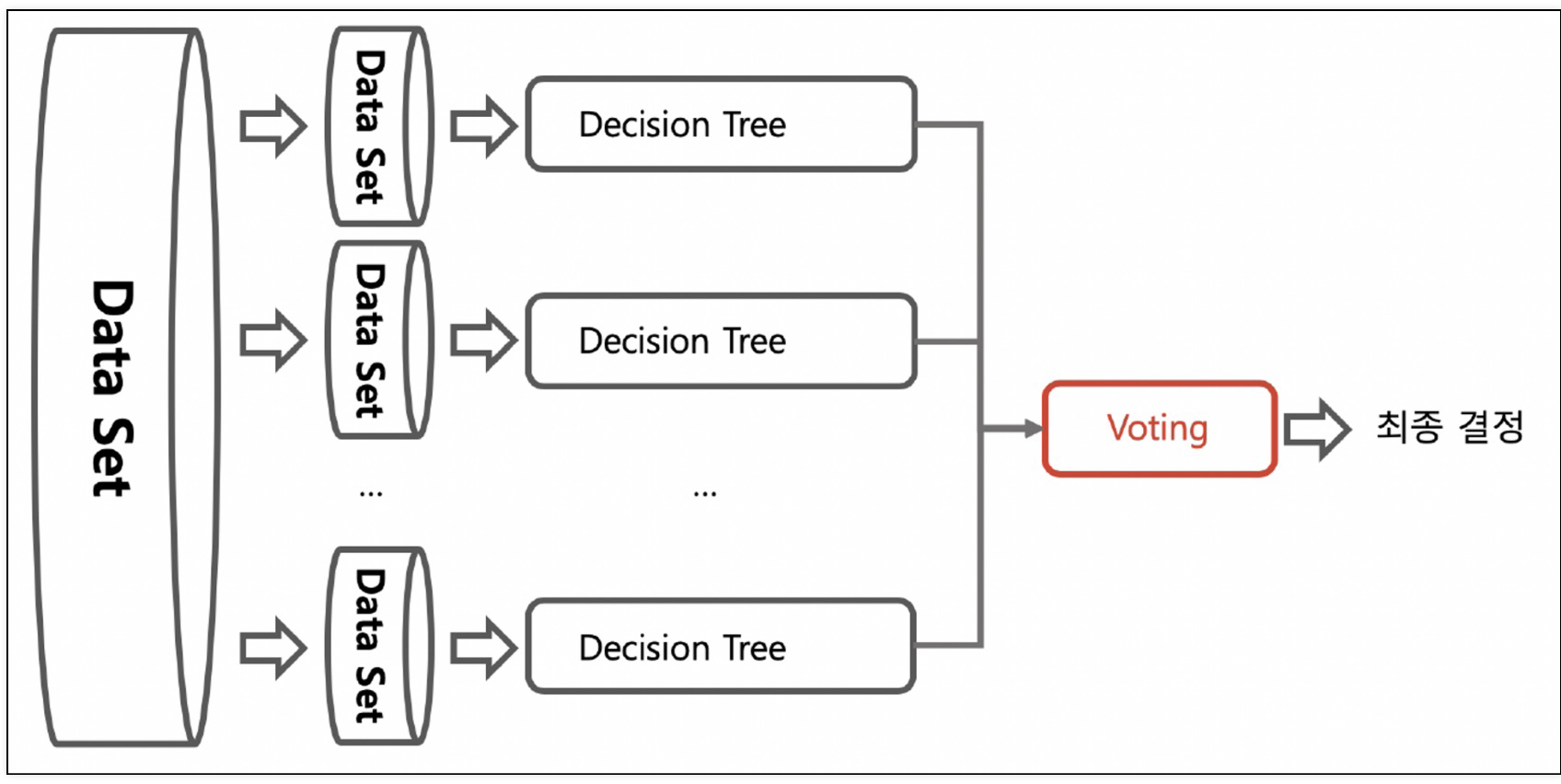
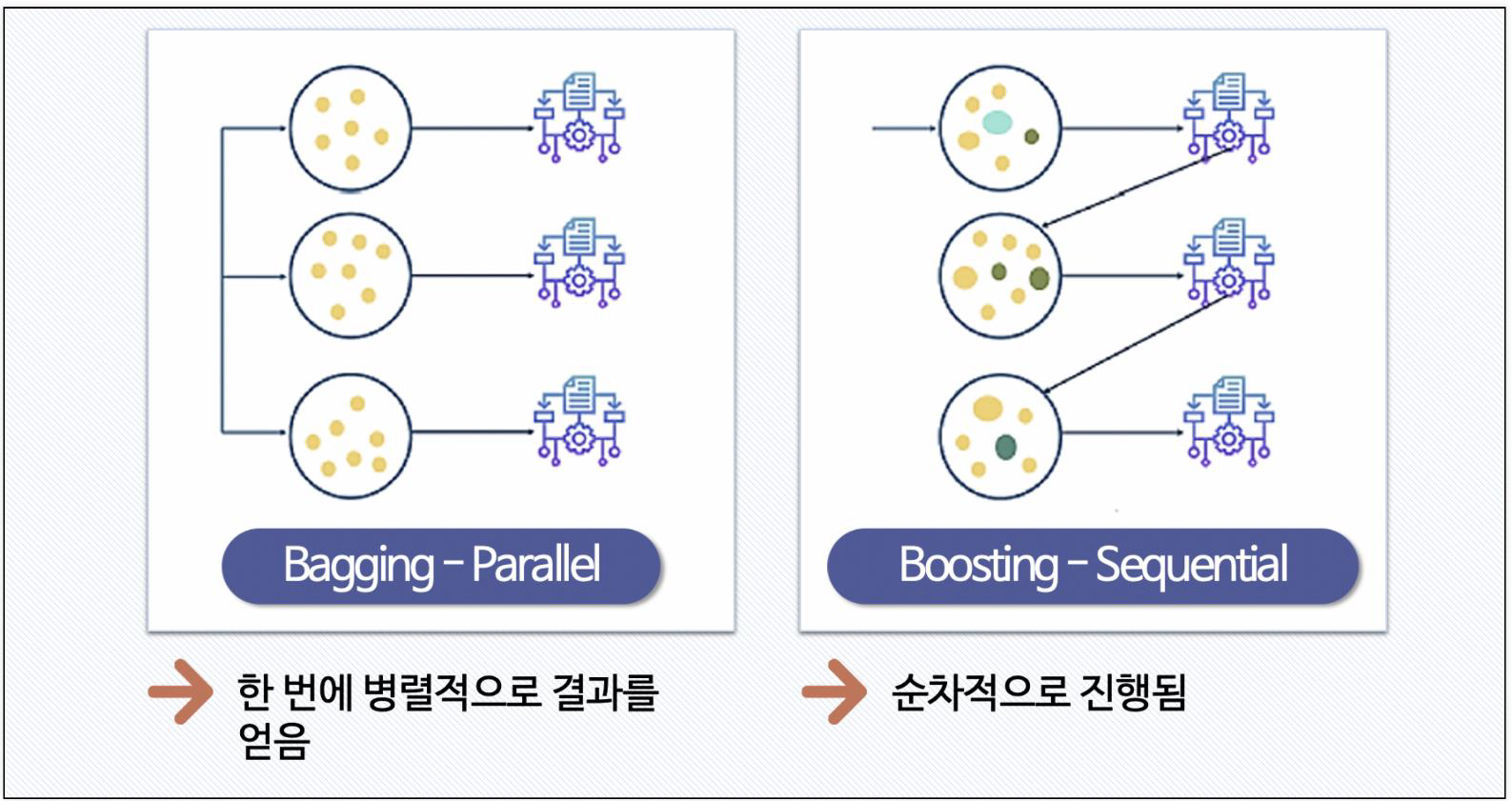
3. Bagging
- Bootstrap + Aggregating
- 데이터를 중복을 허용해서 샘플링하고 각각의 데이터에 같은 알고리즘을 적용해서 결과를 투표로 결정
- 약한 분류기들을 결합하여 강 분류기로 만드는 과정
- 서로 같은 알고리즘을 이용한 분류기가 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행하는 방식(ex. 랜덤 포레스트)
- 개별 분류기가 부트스트래핑 방식으로 샘플링된 데이터 세트에 대해 학습을 통해 개별적인 예측을 수행한 결과를 voting을 통해 최종 예측 결과를 선정하는 방식을 'Bagging Ensemble'
Random forest
- bagging의 대표적인 방법
- 앙상블 방법 중에서 비교적 속도가 빠르며 다양한 영역에서 높은 성능을 보여준다.
- Bootstrapping은 여러 개의 작은 데이터 셋을 중첩을 허용해서 만든다.
- 랜덤 포레스트는 결정 나무를 기본으로 한다.
- Bootstrapping으로 샘플링된 데이터마다 결정나무가 예측한 결과를 소프트보팅으로 최종 예측 결론을 얻는다.
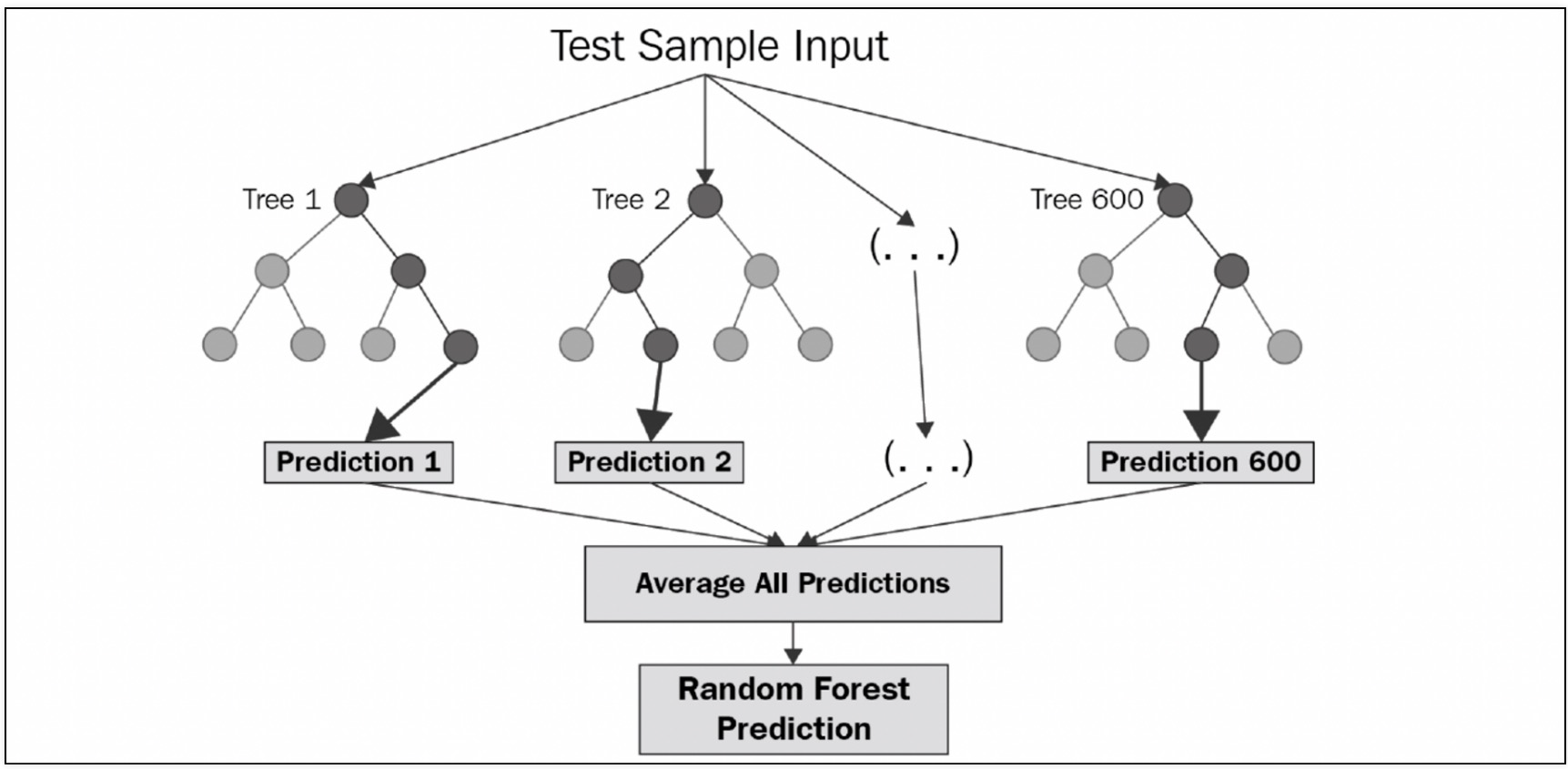
- Bootstrapping으로 샘플링된 데이터마다 결정나무가 예측한 결과를 소프트보팅으로 최종 예측 결론을 얻는다.
4. Boosting
- 여러 개의 (약한)분류기가 순차적으로 학습을 하면서, 학습한 분류기가 예측이 틀린 데이터에 대해 다음 분류기가 가중치를 인가해서 학습을 이어 진행하는 방식
- 예측 성능이 뛰어나서 앙상블 학습을 주도하고 있다.
- 종류: Gradientboost, XGboost(eXtra Gredient Boost), LightGBM(Light Gredient Boost)

Reference
1) 제로베이스 데이터스쿨 강의자료
2) https://dacon.io/codeshare/5123

데이터 사이언스 / just do it