대회 개요
주제 : 마스크 착용 상태 분류
- 카메라로 촬영한 사람 얼굴 이미지의 마스크 착용 상태와 나이, 연령대를 판단하는 Task
개요
- 마스크 착용 상태 (Wear, Incorrect, Not Wear ),
성별 (Male, Female),
연령 (30세 미만 = young, 30세 이상 60세 미만 = middle, 60세 이상 = old)
을 기준으로 총 18개의 클래스로 분류하면 된다. - 평가는 F1 Score를 통해 진행된다.
데이터
- 전체 사람 수 : 4,500명
- 한 사람당 사진의 개수 : 7 (마스크 착용 5장, 미착용 1장, 오착용 1장)
- 이미지 크기 : (384, 512)
- 전체 데이터셋(31,500장) 중 학습 데이터는 60%(18,900장)이다.
대회 Timeline
- 10/24 ~ 10/26 : Domain Study
- 10/27 ~ 10/30 : 실험 기획 및 통제 변인 설정
- 10/27 ~ 10/30 : 기본 모델 선정
- 10/30 ~ 11/01 : 모델 Custom
- 11/01 ~ 11/03 : Hyperparameter Tuning
- 11/03 : 대회 종료
문제 정의
-
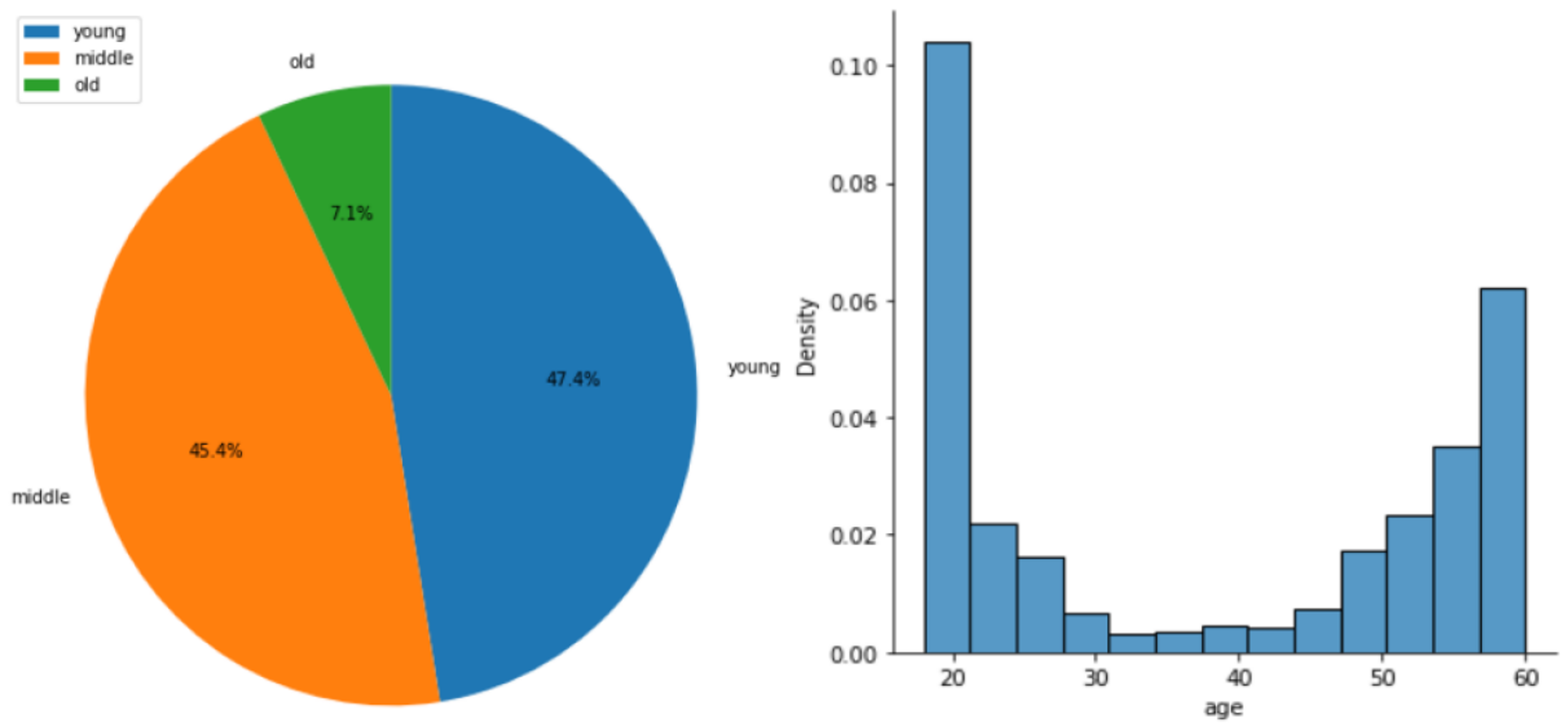
EDA 결과, Data Imbalance가 존재했다. 남여 비율은 6:4로 큰 차이는 없었지만, 60대 이상을 나타내는 'Old'가 약 7.3%로 매우 낮은 비율을 차지했다. 또한 'Middle'과 'Old'의 경계선 부분의 데이터 밀도가 높다는 문제가 있다.
-
마스크 착용 상태, 성별, 연령대를 서로 다른 모델로 학습 후 인코딩을 통해 Label을 추론하는 방법과 3가지 카테고리를 단일 Task로 가정하여 추론하는 방법을 선택해야 했다.
주어진 문제를 해결하기 위해 아래와 같은 방법에 대해 고민을 하였다.
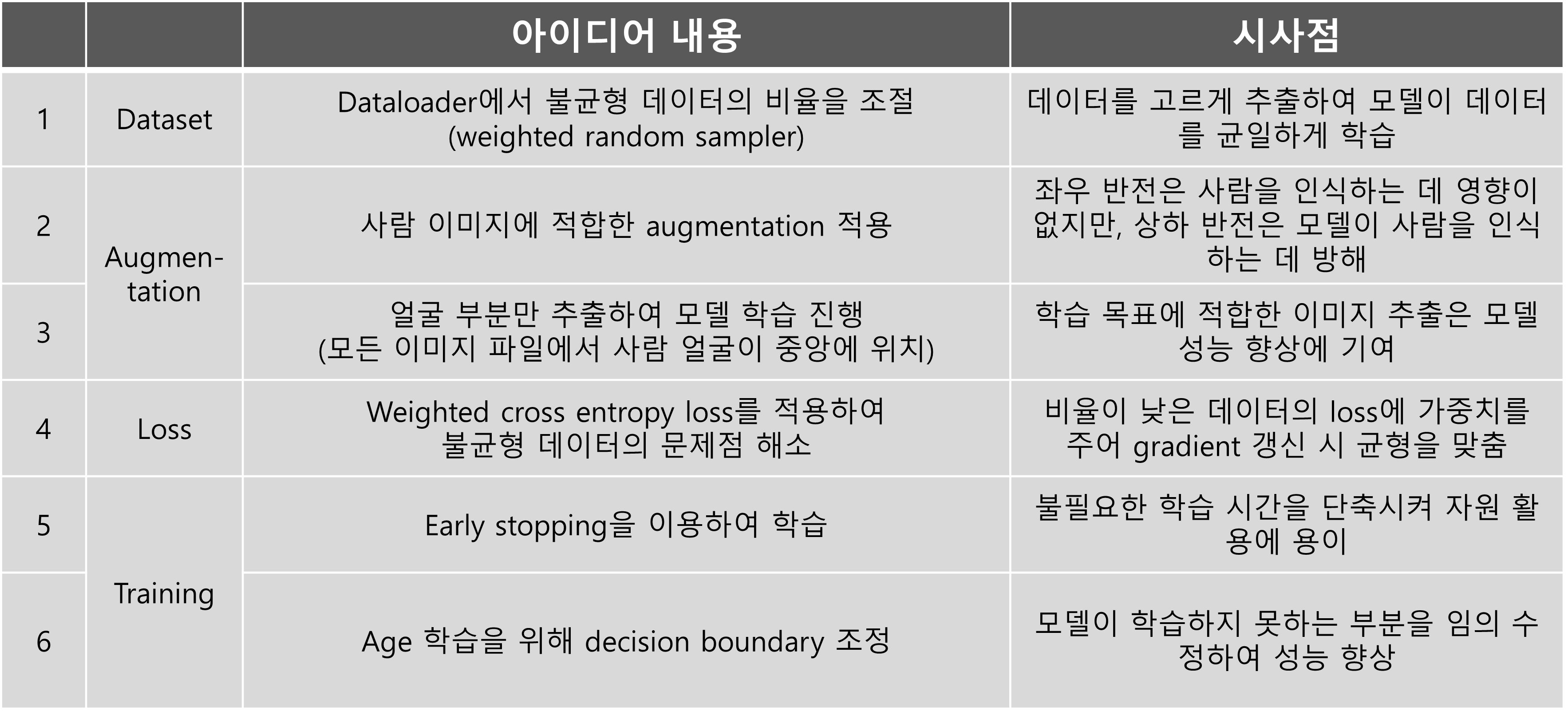
Dataset 구성
EDA 중 알게 된 Class Imbalance 문제를 해결하기 위해 Weigthed Random Sampler를 이용하여 비중이 낮은 Class에 가중치를 주어 학습 과정에서 자주 학습될 수 있도록 하였다.
Model Search
- 모델은 EfficientNet으로 고정하였다. 이유는 대회를 진행하기 전 EfficientNet 논문 스터디를 진행하여 EfficientNet을 직접 실험함으로써 이해도를 더 높이고자 했기 때문이다.
- 주어진 데이터의 Input Size가 (384, 512)이기 때문에 EfficientNet의 논문에서 제시한 Input Size를 고려하여 Input Size가 (380, 380)인 B4 모델부터 실험을 진행하였다.
Task 세분화
앞서 문제 정의에서 언급했듯이 모델 관점에서 문제를 해결하기 위한 방법을 두 가지로 추렸다.
- 모델를 학습시켜 총 18개의 class를 구분하는 방법
- Category(마스크 착용 상태, 성별, 연령대)를 분리하여 따로 학습 시킨 후 각 출력값을 인코딩하는 방법
이 중 두 번째 방법을 먼저 선택하여 실험을 진행했다. 그 이유는 Task를 분리함으로써 하나의 모델이 표현해야 하는 Feature Map이 단순해져 최적화가 쉬워질 것이라고 생각했기 때문이다. 그리고 Young, Middle, Old의 Decision Boundary가 명확해지는 효과가 있을 것이라 생각했다.
하지만 단일 모델의 성능과 비교했을 때 Task를 세분화한 실험의 성능이 낮았다. 이에 대한 개인적인 결론은 다음과 같다.
-
불명확한 기준
나이대를 구분할 수 있는 명확한 특징이 존재하지 않기 때문에 얼굴을 바탕으로 구분하는 것은 한계가 있었다. 그래서 나이를 분류하는 모델의 정확도가 다른 모델에 비해 낮은 정확도를 보였다고 생각한다. -
오류의 중복
각 모델의 정확도가 90%로 동일하다면, 세 모델이 모두 올바른 label을 출력할 확률은 72.9%이다. 즉 각 Task에 대해서는 높은 성능을 낼 수 있지만, 이를 종합하는 과정에서 오류의 중복으로 정확도가 떨어졌다고 판단했다. 그리고 나이에 대한 낮은 성능이 결과를 더 악화시켰다고 판단했다.
이러한 실험 결과로 인해 최종 모델은 Task를 세분화하지 않고 18개의 Class를 구분하는 방법으로 진행하였다.
실험 관리
모델이 확정된 이후에는 통제변인을 설정 후 하나의 조작변인만 변화시키며, 현재 모델의 최적의 Augmentation, Loss function, Optimizer를 탐색하는 실험과 Hyperparameter Tuning을 진행하였다.
개인 회고
-
실험 관리 미숙
머신러닝 대회를 처음 접해 실험 관리에서 아쉬운 점이 많았다. 여러 개의 변인을 한 번에 조작하여 결과 도출의 원인을 파악하지 못해 다시 실험을 진행한 경우도 많았으며, 모델 실험의 기준을 정하지 못해 일관성 없는 실험도 진행하였다. -
문제에 대한 고찰 부족
문제를 정확히 파악하지 않고 실험을 진행하여 실험 도중 문제 정의를 다시 하였다. 그 결과, 실험에 필요한 절대적인 시간이 부족해져 충분한 실험을 진행하지 못했다.
