AlexNet
ImageNet Classfication with Deep Convolutional Neural Networks
논문의 명은 'ImageNet Classfication with Deep Convolutional Neural Networks'이지만, 논문의 저자 이름을 따서 해당 모델을 'AlexNet'이라고 부른다.
1. Introduction
도입부에서 밝힌 이 논문의 기여(contribution)는 ILSVRC-2010, ILSVRC-2012 대회에서 제공된 데이터셋을 이용한 결과물 중에 최고의 결과를 달성했다는 것이다.
그리고 네트워크의 성능을 향상 시키고 학습 시간을 줄이는 새롭고 독특한 특징(ReLU, Multiple GPU, Local Response Normalization, Overlapping Pooling)을 사용했다는 점도 꼽을 수 있다.
또한 overfitting 문제를 해결하였으며, 고성능 GPU와 더 많은 데이터가 있다면 성능을 향상시킬 수 있음을 실험적으로 제안하였다.
- ILSVRC-2010, ILSVRC-2012에서 best result
- ReLU, Multiple GPU, Local Response Normalization, Overlapping Pooling
2. The Dataset
ImageNet은 22,000개의 범주에 속하는 1500만 개의 데이터셋이다.
대회에서는 ImageNet의 부분 데이터로 학습을 진행하며, 부분 데이터는 120만 개의 데이터로 구성되어 있고, 이미지의 종류는 1000개이다.
이 논문에서는 학습을 위해 이미지를 256 * 256으로 해상도를 조절하였다.
3. The Architecture
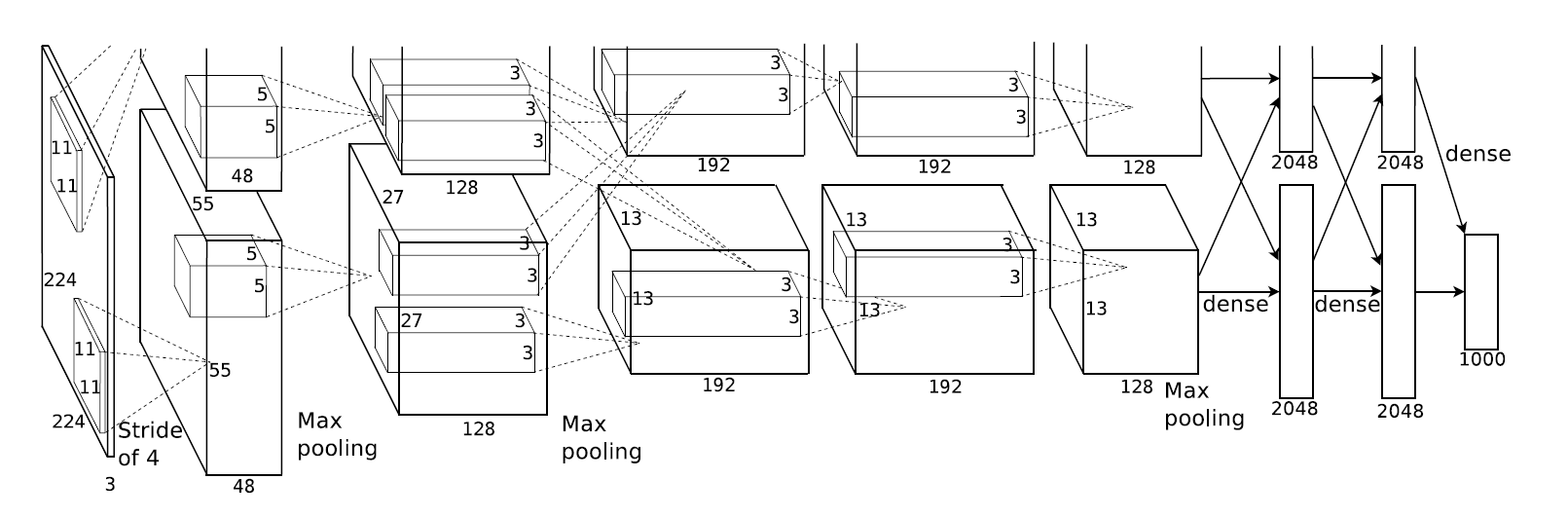
- AlexNet은 5개의 convolutinal layer와 3개의 fully-connected layer로 구성되어 있다.
-
ReLU (Rectified Linear Unit)
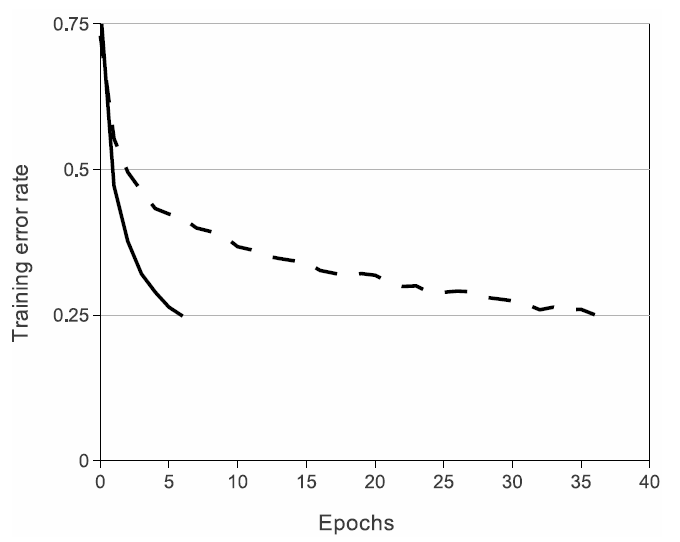
ReLU를 이용하여 tanh를 이용할 때보다 몇 배 더 빠르게 학습을 시켰다.
ReLU(실선), tanh(점선)
-
Multiple GPU
2개의 GPU를 사용하여 크기가 큰 네트워크를 학습하였다. (GPU를 두 개 사용하는 것이 한 개 사용하는 것보다 약간 더 빠르다, the two-GPU net takes slightly less time to train than the one-GPU net) -
Local Response Normalization
convolutional layer와 max pooling layer를 거칠 때, 높은 픽셀값이 있으면 주변 픽셀에 영향을 주게 되고, 이는 학습에 부정적인 영향을 끼친다. 따라서 LRN을 사용하여 높은 픽셀값이 주변에 영향을 주지 않도록 측면 언제를 적용하였다. -
Overlapping Pooling
stride를 조절하여 필터들이 겹치게 하였다. 그 결과 top-1과 top-5에서 error rate가 0.4%, 0.3% 줄었다.
4. Reducing Overfitting
-
Data Augmentation을 위해 이미지 좌우반전, 특정부분을 무작위로 224 * 224 크기의 이미지 추출, 이미지의 RGB 체널을 바꾸는 기법을 사용하였다.
-
Dropout을 첫 번째, 두 번째 fully-connected layer에 적용하였다.
5. Details of learning
- SGD를 이용하여 학습을 진행하였고, momentum(0.9)과 weight decay(0.0005)를 적용하였다.
- weight는 표준편차가 0.01, 평균이 0인 가우시안 분포를 따르도록 초기화하였다.
- 2,4,5, fully-connected layer들의 bias값은 상수 1로 초기화하였고, 다른 층 bias는 0으로 초기화하였다.
- 모든 층의 learning rate를 0.01로 동일하게 적용하였고, 학습은 총 90회 반복하였다.
6. Results
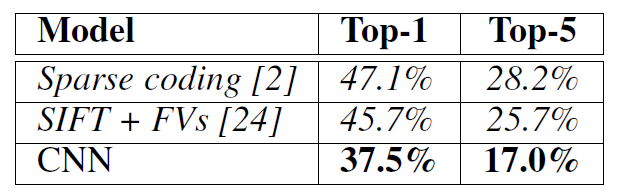
ILSVRC-2010의 결과는 아래 표와 같다. Top-1은 모델이 예측한 가장 가능성이 높은 첫 번째 대상을 의미한다. Top-5는 가장 가능성이 높은 상위 5개를 의미하는 것이다. 그 결과 Top-1에서의 error rate은 37.5%, Top-5에서는 17.0%를 기록하였다. (italics으로 쓰인 모델은 다른 이의 모델이다)
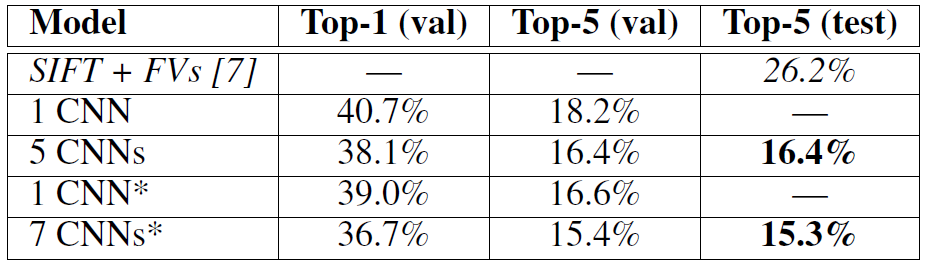
ILSVRC-2012의 결과는 아래 표와 같다. 이 논문에 나온 CNN 모델의 Top-5 (val) error rate은 18.2%를 기록하였고(1 CNN), 유사한 5개의 CNN 모델에 대해서는 16.4%를 기록하였다(5 CNNs).
마지막 pooling layer에 6번째 convolutional layer를 추가한 모델은 16.6%의 error rate을 기록하였고(1 CNN), 앞에서 언급한 유사한 5개의 CNN 모델(5 CNNs)과 pre-train된 모델의 예측에 대한 error rate을 평균한 값은 15.3%를 달성하였다.(7 CNNs) (italics으로 쓰인 모델은 다른 이의 모델이고, *표시는 ImageNet 2011으로 pre-trained된 모델을 의미한다.)