
알고리즘 개요
크루스칼 알고리즘이란?
크루스칼 알고리즘은 최소 신장 트리(Minimum Spanning Tree)를 구하는 알고리즘 중 하나입니다.
이 알고리즘은 그리디 알고리즘의 일종으로, 간선을 가중치의 오름차순으로 정렬한 뒤 작은 가중치부터 하나씩 선택해 최소 신장 트리를 구합니다.
최소 신장 트리(Minimum Spanning Tree, MST): 모든 정점을 포함하면서, 사이클을 형성하지 않으면서 그래프 상의 간선들의 가중치 합이 최소인 트리
알고리즘 동작 과정
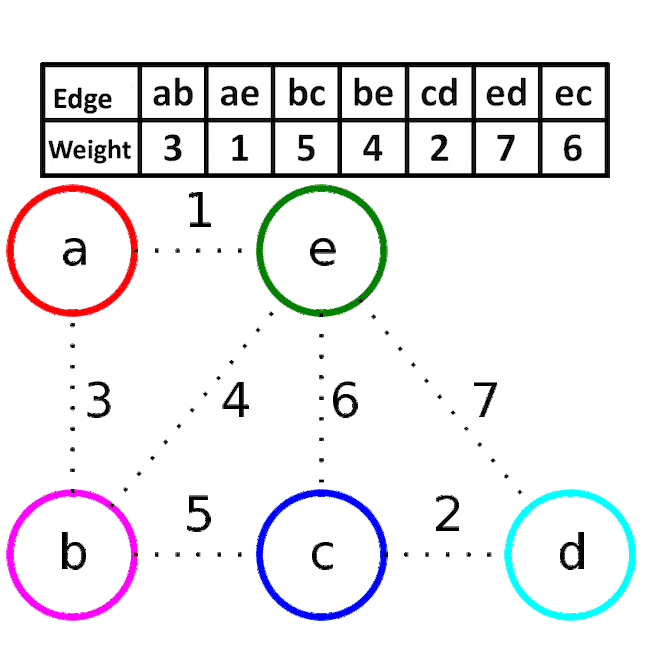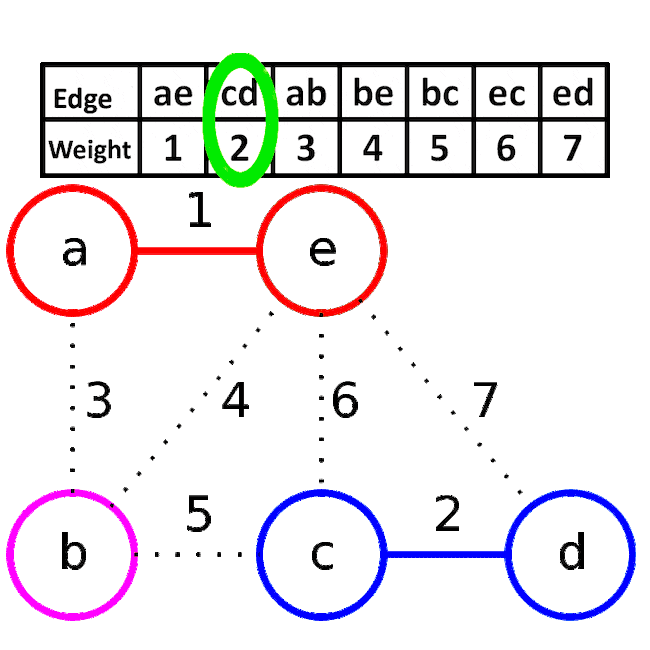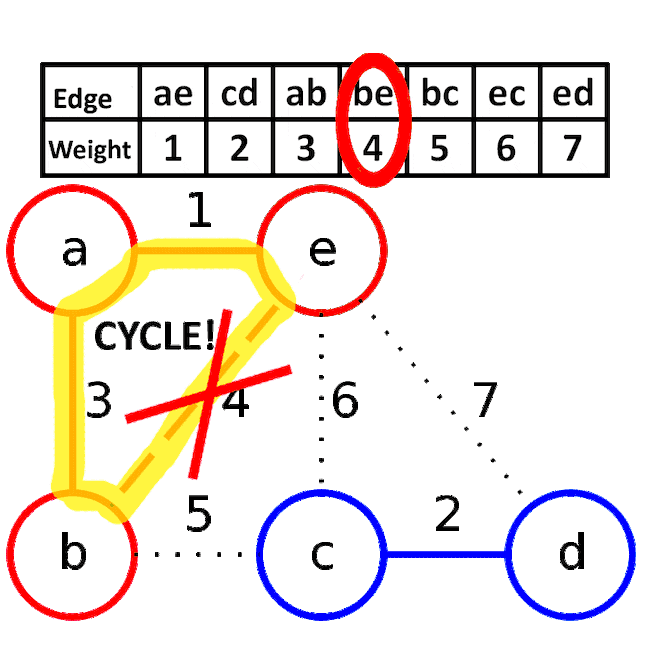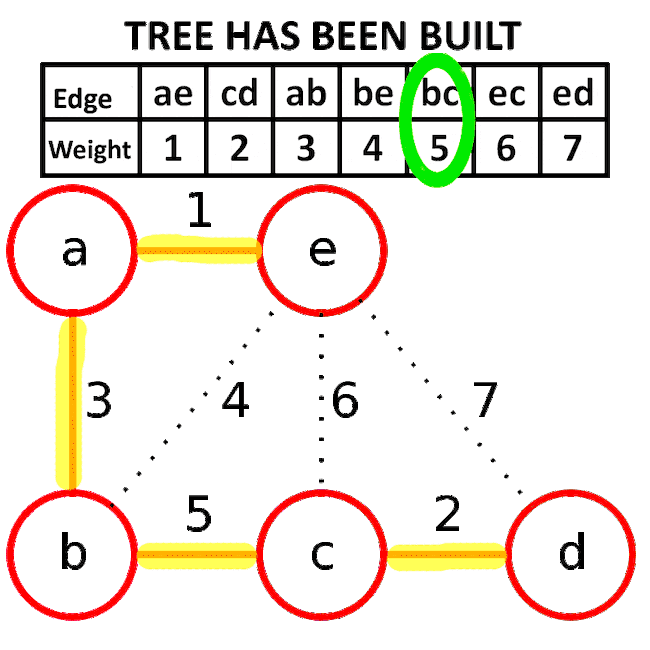 <이미지 출처: 네이버 블로그/Luiten Lab/히니즈>
<이미지 출처: 네이버 블로그/Luiten Lab/히니즈>
알고리즘 구현 방법
-
그래프 구성
- 그래프를 이루는 모든 노드를 정점으로 표현합니다.
- 그래프를 이루는 모든 간선을 가중치와 함께 리스트 형태로 표현합니다.
-
간선 가중치의 오름차순 정렬
- 간선들을 가중치 오름차순으로 정렬합니다.
-
Union-Find 자료구조를 이용한 노드 연결
- Union-Find 자료구조를 이용하여 노드들을 연결합니다.각 노드는 자신의 부모 노드를 가리키는 parent 배열과, 해당 노드가 속한 트리의 크기를 나타내는 rank 배열을 가지고 있습니다.
크루스칼 알고리즘에서 rank는 Union-Find 자료구조에서 특정 노드의 높이(height)를 나타내는 값입니다.
rank를 사용하는 이유는 Union-Find 자료구조에서 발생할 수 있는 최악의 시간 복잡도를 개선하기 위함입니다. rank를 이용해 Union 과정을 수행할 때, 높이가 낮은 트리를 높이가 높은 트리의 자식으로 붙이는 방식으로 높이를 최소화할 수 있습니다.- 초기에는 모든 노드의 부모 노드는 자기 자신이며, 해당 트리의 크기는 1입니다. Union-Find 자료구조를 이용하여 두 개의 트리를 연결할 때는 rank 값을 비교하여 더 작은 트리를 더 큰 트리에 붙입니다.
-
최소 신장 트리 구성
- 간선들을 가중치 오름차순으로 하나씩 가져옵니다. 간선의 양 끝 노드가 속한 트리가 서로 다른 경우, 해당 간선을 선택하여 최소 신장 트리에 추가합니다.
- 선택된 간선을 Union-Find 자료구조를 이용하여 노드들을 연결합니다.
-
모든 간선에 대하여 위의 과정을 반복합니다.
알고리즘 코드 예시
Python
# 간선 클래스 정의
class Edge:
def __init__(self, u, v, weight):
self.u = u
self.v = v
self.weight = weight
# 부모 노드를 찾는 함수
def find(parent, node):
if parent[node] == node:
return node
parent[node] = find(parent, parent[node])
return parent[node]
# 두 노드를 합치는 함수
def union(parent, rank, node1, node2):
root1 = find(parent, node1)
root2 = find(parent, node2)
if root1 != root2:
if rank[root1] > rank[root2]:
parent[root2] = root1
else:
parent[root1] = root2
if rank[root1] == rank[root2]:
rank[root2] += 1
# 크루스칼 알고리즘 함수
def kruskal(edges, num_nodes):
# 간선 가중치를 오름차순으로 정렬
edges.sort(key=lambda x: x.weight)
# 각 노드의 부모 노드와 랭크 초기화
parent = list(range(num_nodes))
rank = [0] * num_nodes
# 최소 신장 트리 구성을 위한 간선 선택
mst = []
for edge in edges:
if len(mst) == num_nodes - 1:
break
if find(parent, edge.u) != find(parent, edge.v):
mst.append(edge)
union(parent, rank, edge.u, edge.v)
return mst
알고리즘의 시간 복잡도
크루스칼 알고리즘의 시간 복잡도는 주어진 간선의 개수를 E, 노드의 개수를 V라고 할 때, 간선을 정렬하는 시간과 간선을 선택하는 데 걸리는 시간에 따라 결정됩니다.
-
간선 정렬 시간 복잡도
간선을 정렬하는 시간 복잡도는 대부분의 정렬 알고리즘에서 O(E log E) 입니다. 이는 주어진 간선의 개수에 비례하므로, E가 증가할수록 정렬 시간이 증가합니다. -
간선 선택 시간 복잡도
Union-Find 자료구조를 이용하여 간선을 선택하는 시간 복잡도는 O(E log V) 입니다. 이는 Union-Find 자료구조에서 노드를 찾는 데 걸리는 시간이 log V 이므로, 모든 간선에 대하여 찾는 시간이 필요하므로 E log V가 됩니다.
따라서, 크루스칼 알고리즘의 전체 시간 복잡도는 O(E log E + E log V) 입니다. 이를 보다 단순하게 표현하면, 간선의 개수가 많은 경우 O(E log E)에 근사합니다.
알고리즘의 한계와 개선 방법
한계
-
밀집 그래프(dense graph)에서의 성능 저하
크루스칼 알고리즘의 시간 복잡도는 O(E log E) 이기 때문에, 간선의 수가 많은 밀집 그래프에서는 다른 알고리즘에 비해 느리게 동작할 수 있습니다. -
Union-Find 자료구조에서의 최악의 경우
Union-Find 자료구조에서 트리의 높이가 매우 커질 경우, 최악의 경우 시간 복잡도가 O(V^2)가 될 수 있습니다. 이러한 경우를 방지하기 위해서는 경로 압축(path compression) 기법을 적용하여 트리의 높이를 최대한 작게 유지하는 것이 좋습니다.union-find 경로 압축: 부모 노드를 계속 연결시키는 것이 아니라 최상단의 노드를 부모로 정하는 기법
** rank와 경로 압축은 각기 다른 Union-Find 알고리즘의 최적화 기법입니다.
개선 방법
크루스칼 알고리즘의 개선 방법으로는 prim 알고리즘과 비슷한 개념인 힙(heap) 자료구조를 사용하는 방법이 있습니다.
각 노드마다 인접한 간선 중 가장 작은 가중치를 가진 간선을 선택하는 것이 아니라, 모든 간선을 우선순위 큐(heap)에 넣어 가장 작은 가중치의 간선을 선택합니다. 이렇게 하면 간선을 정렬하는 시간 복잡도가 O(E log E)에서 O(E log V)로 개선됩니다.
이 방법을 사용하면 크루스칼 알고리즘의 시간 복잡도는 O(E log V)가 됩니다.
