
탐색
탐색이란 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정을 의미한다.
프로그래밍에서는 그래프, 트리 등의 자료구조 안에서 탐색을 하는 문제를 자주 다룬다.
대표적인 탐색 알고리즘으로 DFS와 BFS가 있다.
그래프
그래프의 구조
DFS/BFS를 이해하기 전에 그래프의 기본 구조를 알아야 한다.
- 그래프는 노드(Node)와 간선(Edge)로 표현된다.
그래프 탐색이란 하나의 노드를 시작으로 다수의 노드를 방문하는 것을 말한다.- 두 노드가 간선으로 연결되어 있다면 두 노드는 인접하다
adjacency라고 표현한다.
그래프의 표현
프로그래밍에서 그래프는 2가지 방식으로 표현한다.
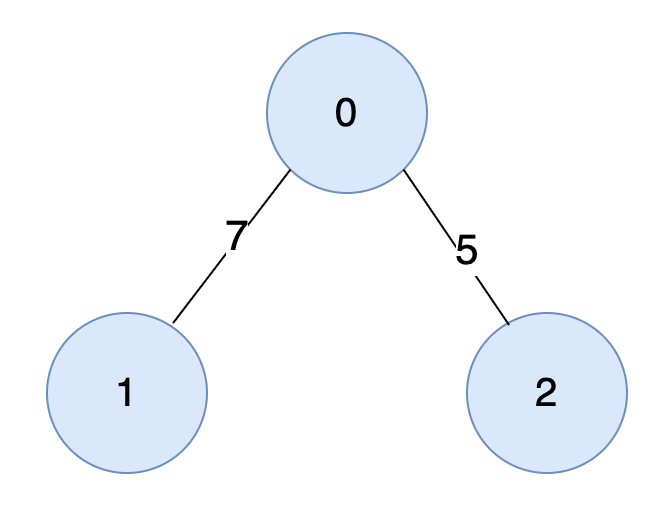
인접 행렬 (Adjacency Matrix)
2차원 배열에 각 노드가 연결된 형태를 기록하는 방식
연결되어 있지 않은 노드끼리는 무한의 비용이라고 작성한다. 위의 그래프를 인접 행렬로 나타내면 다음과 같다.
INF = 999999999
graph = [
[0, 7, 5],
[7, 0, INF],
[5, INF, 0],
]인접 리스트 (Adjacency List)
리스트로 그래프의 연결 관계를 표현하는 방식
인접 리스트의 방식에서는 다음 그림처럼 모든 노드에 연결된 노드에 대한 정보를 차례대로 연결하여 저장한다.
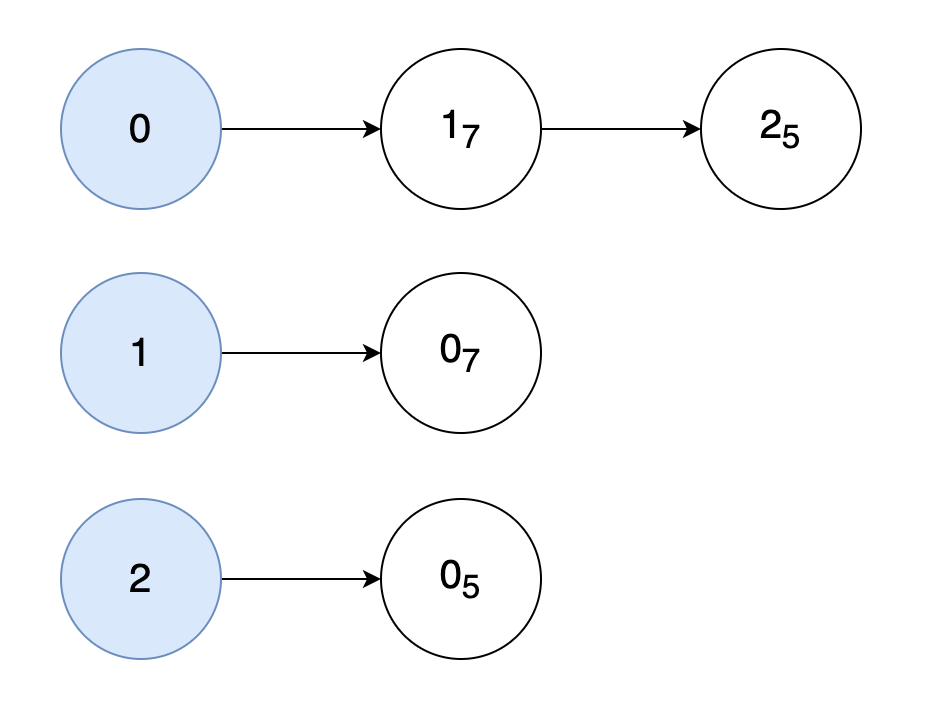
graph = [[] for _ in range(3)]
graph[0].append((1, 7))
graph[0].append((1, 5))
graph[1].append((1, 7))
graph[2].append((0, 5))
print(graph) # [[(1, 7), (1, 5)], [(1, 7)], [(0, 5)]]두 방식의 차이
- 메모리 측면 (인접 리스트 is better)
- 인접 행렬: 모든 관계를 저장→ 노드 개수가 많을수록 메모리가 불필요하게 낭비됨
- 인접 리스트: 연결된 정보만을 저장 → 메모리 효울적으로 사용
- 속도 측면 (인접 행렬 is better)
- 인접 리스트: 인접 행렬에 비해 특정한 두 노드가 연결되어 있는지에 대한 정보를 얻는 속도가 느림 (연결된 데이터를 하나씩 확인해야 하므로)
