
Error 객체를 구성하는 기본 요소 세 가지
https://ui.toast.com/weekly-pick/ko_20170306
1.name 오류 이름
2.message 오류 메시지
3.stack : stack(쌓여있는 형태-LIFO의 자료구조) 형태로 사용하는 메모리의 한 영역.
-heap/stack 영역 2가지가 존재 : heap은 전역변수나 동적할당된 값이 저장되는 메모리의 영역이고, stack은 지역변수나 내부 함수와 같은 값들이 저장되는 영역
try {
throw new Error("Something wrong happened!");
// throw 'hi';
} catch (e) {
console.log(`${e.name}: ${e.message}\n\n`);
console.log(e.stack);
// console.log(e);
}
예시) error fields
try{
throw new Error('sth wrong');
}
catch (error){
console.log(error.name);
console.log(error.message);
console.log(error.stack);
}try로 특정 상황에 발생할 에러를 지정, catch로 메시지를 받아서 출력
에러를 통해 가능한 영역을 고지하여 직관적인 코딩, 협업이 수월
Error "Propagation"
function testA(){
console.log('call testB');
testB();
}
function testB(){
console.log('call testC');
testC();
}
function testC(){
throw new Error('this is error');
}
try{
testA();
} catch (e){
console.log(e.message);
}
//call testB
//call testC
//this is errortry, catch를 안 하면 하나씩 버블링으로 올라가는데 try catch를 해주면 해당 스코프에서 더 올라가지 않음.
에러 전파가 없다면 각 에러에 대해 try/catch를 전부 처리해줘야 했을 것. 에러 전파가 있어서 최종 적인 곳에서 모아 한 번에 처리가 가능함.
함수는 항상 의도한 결과값 or 에러를 반환한다.
입력창에 숫자만 입력해야 하는데 문자를 넣는 경우도 개발자의 입장에서는 에러라고 볼 수 있으므로 throw를 통해 오류로 처리할 수 있다.
nested try-catch
try {
try {
throw new Error('why....');
} catch (e) {
console.log('inner:', e.message);
throw new Error('this is just for demo');
}
} catch (e) {
console.log('outer:', e.message);
}
//inner : why....
//outer : this is just for demoStack 요소 동작 방식
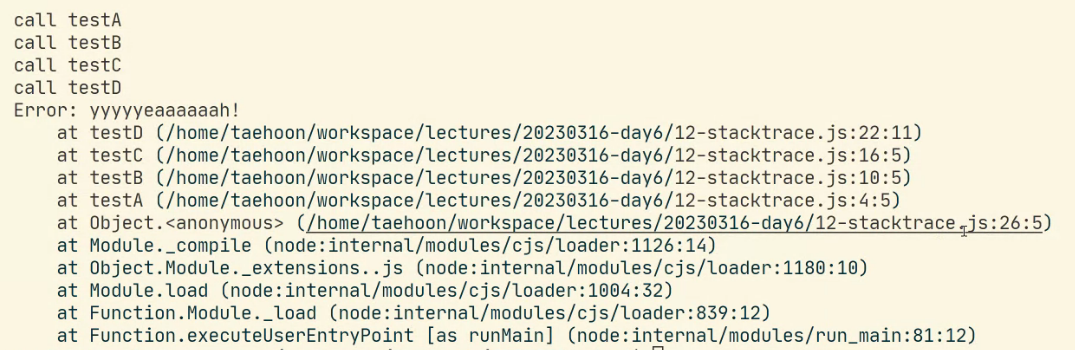
stacktrace : 에러 추적
function testA() {
console.log('call testA');
testB();
}
function testB() {
console.log('call testB');
testC();
}
function testC() {
console.log('call testC');
testD();
}
function testD() {
console.log('call testD');
throw new Error('yyyyyeaaaaaah!');
}
try {
testA();
} catch (e) {
console.log(e);
} .
.
object.anonymous 26:5 -> testA 4:5, testB 18:5, testC 16:5, testD 22:11(최종 에러 지점)
스택구조로 에러 추적 가능. ABCD 모두 에러 해결할 필요 없이 버블링이 발생한 지점에서 에러를 해결해주면 된다.
스택구조는 쌓이는 구조라 기능이 배열 같은 것에 비해 제한적인데 쓰는 이유는 뭘까?
->기능을 쉽게 유추 할 수 있다.(const처럼)
->성능:넣고 빼는 기능 정도면 충분하다
스택은 한 작업이 끝나고 이전으로 돌아갈 때 복귀주소라는 값을 통해 이전 작업의 영역으로 돌아갈 수있다.
finally
try/catch 처리를 끝내고 실행.
에러가 없어도 finally는 실행됨.
이 기능이 존재하는 이유 : 에러 발생 여부에 상관없이 처리해줘야 하는 작업이 존재할 때 사용. ex) 열려있는 파일 닫기.
function iWillThrowError() {
console.log('bye');
throw new Error('something wrong!'); //message
}
try {
iWillThrowError();
// 바로 위 코드 주석처리시에도 finally는 실행됨.
// 에러가 없어도 finally는 실행된다.
} catch (e) {
console.log(e.message);
} finally {
console.log('ok, finally');
}
//bye
//something wrong!
//ok, finally기본적으로 제공되는 에러
1.TypeError
2.ReferenceError
3.SyntaxError
try {
// TypeError
null[1]
// ReferenceError : hello is not defined
console.log(hello + 1);
// SyntaxError : invalid or unexpected token
1 ### 123;
} catch (e) {
if (e instanceof TypeError) {
console.log(`[Type] ${e.message}`);
} else if (e instanceof ReferenceError) {
console.log(`[Reference] ${e.message}`);
} else if (e instanceof SyntaxError) {
console.log(`[Syntax] ${e.message}`);
} else {
console.log(e);
}
}직접 에러 객체 확장하기 - custom error
디테일한 에러를 짜두면 유지보수가 용이함
class MyCustomError extends Error {
//에러 객체에 상태와 메소드를 상속받음
//name, message, stack 사용가능
somethingCustom;
constructor(message, somethingCustom) {
super(message);
this.name = 'MyCustomError';
this.somethingCustom = somethingCustom;
}
}
try {
throw new MyCustomError('this is my error', [1, 2, 3, 4, 5]);
} catch (e) {
// console.log(e);
console.log(e.name, e.message, e.somethingCustom);
}
//MyCustomError this is my error [1, 2, 3, 4, 5]
//이와 같이 에러를 셀프 정의 가능. 확장 가능성 자유로움.