Caching Data 번역 및 요약
데이터 가져오기 2번째 항목인 Cachind Data 문서다. 번역하고 요약해보자.
데이터 가져오기: 캐싱
Next.js는 데이터 캐싱을 지원하며, 이는 요청별로 또는 전체 라우트 세그먼트에 대해 적용할 수 있습니다.
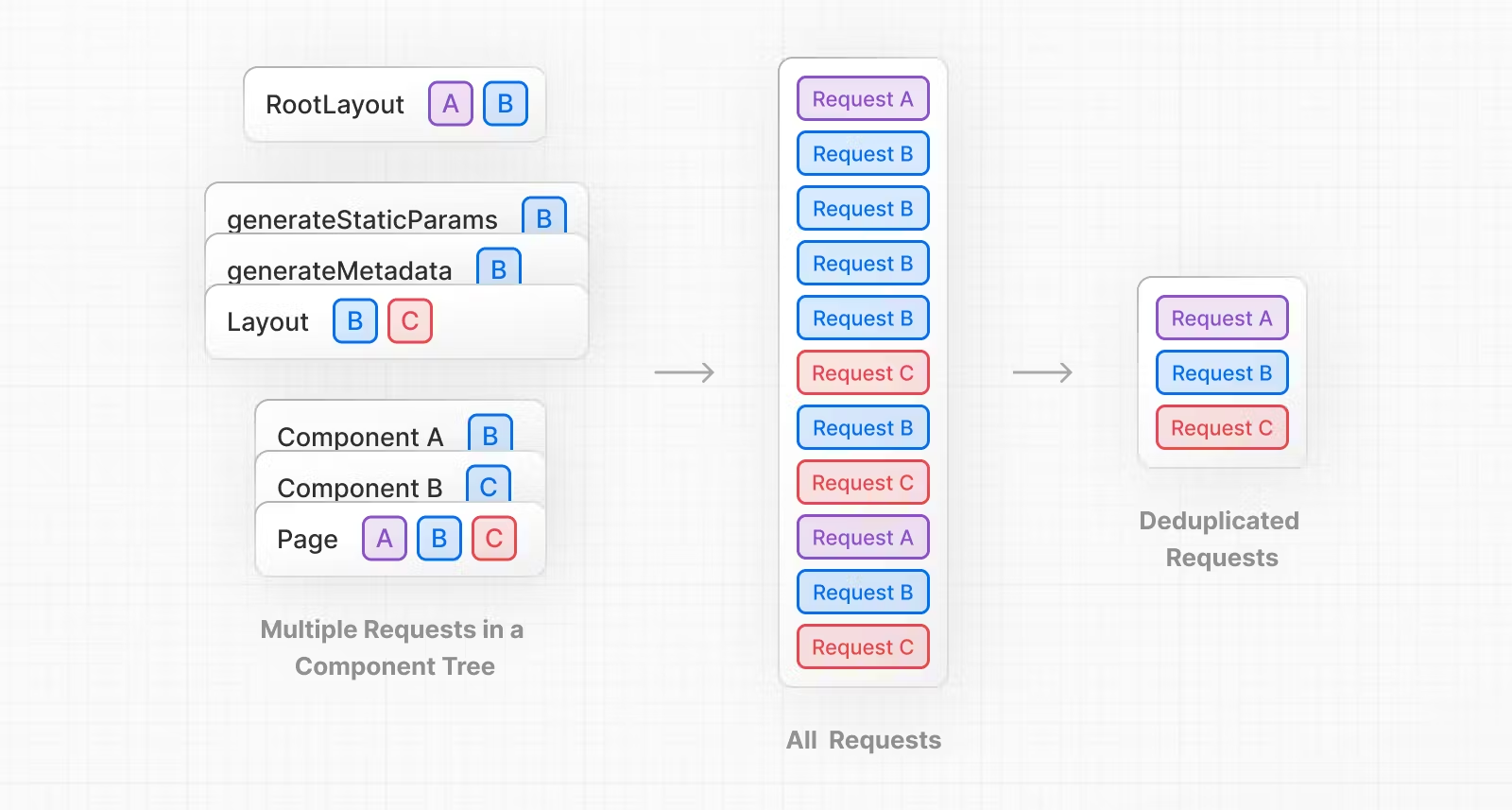
요청별 캐싱
기본적으로 모든 fetch() 요청은 자동으로 캐시되고 중복 제거됩니다. 즉, 동일한 요청을 두 번하면 두 번째 요청은 첫 번째 요청의 결과를 재사용합니다.
async function getComments() {
const res = await fetch('https://...') // 결과가 캐시됩니다.
return res.json()
}
// 이 함수는 두 번 호출되지만 결과는 한 번만 가져옵니다.
const comments = await getComments() // 캐시 MISS
// 두 번째 호출은 애플리케이션의 어디에서나 가능합니다.
const comments = await getComments() // 캐시 HIT요청이 캐시되지 않는 경우는 다음과 같습니다:
- 동적 메서드(
next/headers,export const POST등)가 사용되고 fetch가POST요청이거나 Authorization 또는 쿠키 헤더를 사용하는 경우 fetchCache가 기본적으로 캐시를 건너뛰도록 구성된 경우- 개별 fetch에
revalidate: 0또는cache: 'no-store'가 구성된 경우
fetch를 사용하여 요청을 할 때 revalidate 옵션을 지정하여 요청의 revalidate(재검증) 빈도를 제어할 수 있습니다.
export default async function Page() {
// 이 데이터를 최대 10초마다 revalidate 합니다.
const res = await fetch('https://...', { next: { revalidate: 10 } })
const data = res.json()
// ...
}React cache()
React는 cache()를 사용하여 요청을 캐시하고 중복 제거하며, 래핑된 함수 호출의 결과를 메모이제이션합니다. 동일한 함수가 동일한 인수로 호출되면 함수를 다시 실행하는 대신 캐시된 값을 재사용합니다.
import { cache } from 'react'
export const getUser = cache(async (id: string) => {
const user = await db.user.findUnique({ id })
return user
})
import { getUser } from '@utils/getUser'
export default async function UserLayout({ params: { id } }) {
const user = await getUser(id)
// ...
}
import { getUser } from '@utils/getUser'
export default async function Page({
params: { id },
}: {
params: { id: string }
}) {
const user = await getUser(id)
// ...
}위의 예에서 getUser() 함수는 두 번 호출되지만, 데이터베이스에는 한 번의 쿼리만 발생합니다. 이는 getUser()가 cache()로 래핑되어 있어, 두 번째 요청이 첫 번째 요청의 결과를 재사용할 수 있기 때문입니다.
알아두면 좋은 점:
POST 요청과 cache()
POST 요청은 fetch()를 사용할 때 자동으로 중복 제거됩니다. 하지만 이들이 POST 라우트 핸들러 내부에 있거나 headers() / cookies()를 읽은 후에 올 경우에는 그렇지 않습니다. 예를 들어, 위의 경우에서 GraphQL과 POST 요청을 사용하고 있다면, 요청을 중복 제거하기 위해 cache를 사용할 수 있습니다. 캐시 인수는 평평해야 하며 기본값만 포함해야 합니다. 깊은 객체는 중복 제거를 위해 일치하지 않습니다.
import { cache } from 'react'
export const getUser = cache(async (id: string) => {
const res = await fetch('...', { method: 'POST', body: '...' })
// ...
})cache()와 함께하는 preload 패턴
패턴으로서, 데이터를 가져오는 유틸리티나 컴포넌트에서 선택적으로 preload() export를 노출하는 것을 제안합니다.
import { getUser } from '@utils/getUser'
export const preload = (id: string) => {
// void는 주어진 표현식을 평가하고 undefined를 반환합니다.
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/void
void getUser(id)
}
export default async function User({ id }: { id: string }) {
const result = await getUser(id)
// ...
}preload를 호출함으로써, 필요할 것으로 예상되는 데이터를 적극적으로 가져오기 시작할 수 있습니다.
import User, { preload } from '@components/User'
export default async function Page({
params: { id },
}: {
params: { id: string }
}) {
preload(id) // 사용자 데이터를 지금 로드하기 시작합니다.
const condition = await fetchCondition()
return condition ? <User id={id} /> : null
}알아두면 좋은 점:
preload()함수는 어떤 이름이든 될 수 있습니다. 이는 패턴이며 API가 아닙니다.- 이 패턴은 완전히 선택적이며, 경우에 따라 최적화를 위해 사용할 수 있습니다.
- 이 패턴은 병렬 데이터 가져오기 위의 추가 최적화입니다. 이제 promise를 props로 전달할 필요가 없으며, 대신 preload 패턴에 의존할 수 있습니다.
cache, preload, server-only 결합하기
cache 함수, preload 패턴, server-only 패키지를 결합하여 앱 전체에서 사용할 수 있는 데이터 가져오기 유틸리티를 만들 수 있습니다.
import { cache } from 'react'
// getUser를 서버 발생으로만 쓰기 위해 클라이언트 서버 코드 사용을 방지하기 위한 패키지
import 'server-only'
export const preload = (id: string) => {
void getUser(id)
}
export const getUser = cache(async (id: string) => {
// ...
})이 접근 방식을 사용하면, 데이터를 적극적으로 가져오고 응답을 캐시하며, 이 데이터 가져오기가 서버에서만 발생하도록 보장할 수 있습니다. getUser.ts export는 레이아웃, 페이지 또는 컴포넌트에서 사용될 수 있으며, 이를 통해 사용자의 데이터가 언제 가져와지는지 제어할 수 있습니다.
세그먼트-레벨 캐싱
번역자: 세그먼트-레벨은 어감상 분리된 라우터, fetch 등을 뜻한다.
알아두면 좋은 점: 캐싱에 대한 더 나은 세분화와 제어를 위해 요청별 캐싱을 사용하는 것을 권장합니다.
세그먼트-레벨 캐싱을 사용하면 라우트 세그먼트에서 사용하는 데이터를 캐시하고 revalidate할 수 있습니다. 이 메커니즘을 통해 경로의 다른 세그먼트가 전체 라우트의 캐시 수명을 제어할 수 있습니다. 라우트 계층구조의 각 page.tsx와 layout.tsx는 라우트의 revalidate 시간을 설정하는 revalidate 값을 내보낼 수 있습니다.
export const revalidate = 60 // 이 세그먼트를 60초마다 revalidate합니다.알아두면 좋은 점:
- 페이지, 레이아웃, 컴포넌트 내부의 fetch 요청이 모두 revalidate 빈도를 지정하면, 세 가지 중 가장 낮은 값이 사용됩니다.
- 고급: fetchCache를 'only-cache' 또는 'force-cache'로 설정하여 모든 fetch 요청이 캐싱에 참여하도록 보장할 수 있지만, 개별 fetch 요청에 의해 revalidate 빈도가 여전히 낮아질 수 있습니다. fetchCache에 대한 자세한 정보는 여기를 참조하세요.
요약
-
요청별 캐싱: Next.js의
fetch()는 기본적으로 모든 요청을 자동으로 캐시하고 중복 제거. 동일한 요청을 두 번하면 두 번째 요청은 첫 번째 요청의 결과를 재사용. 요청의 revalidate 빈도를 제어하려면 fetch()에서 revalidate 옵션을 사용할 수 있음. -
React cache(): React는cache()를 사용하여 요청을 캐시하고 중복 제거하며, 래핑된 함수 호출의 결과를 메모이제이션함. 동일한 함수가 동일한 인수로 호출되면 함수를 다시 실행하는 대신 캐시된 값을 재사용. -
cache()와preload패턴: 선택적으로 preload() export를 노출하여 데이터를 적극적으로 가져오기 시작할 수 있음. 이 패턴은 선택적이며, 경우에 따라 최적화를 위해 사용할 수 있음. -
세그먼트-레벨 캐싱: 세그먼트-레벨 캐싱을 사용하면 라우트 세그먼트에서 사용하는 데이터를 캐시하고 revalidate 할 수 있음. 이 메커니즘을 통해 경로의 다른 세그먼트가 전체 라우트의 캐시 수명을 제어할 수 있음.
