
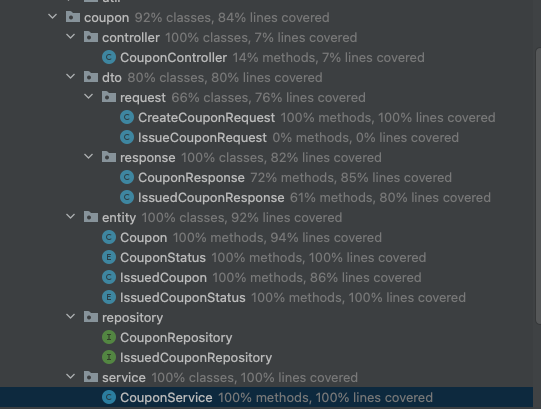
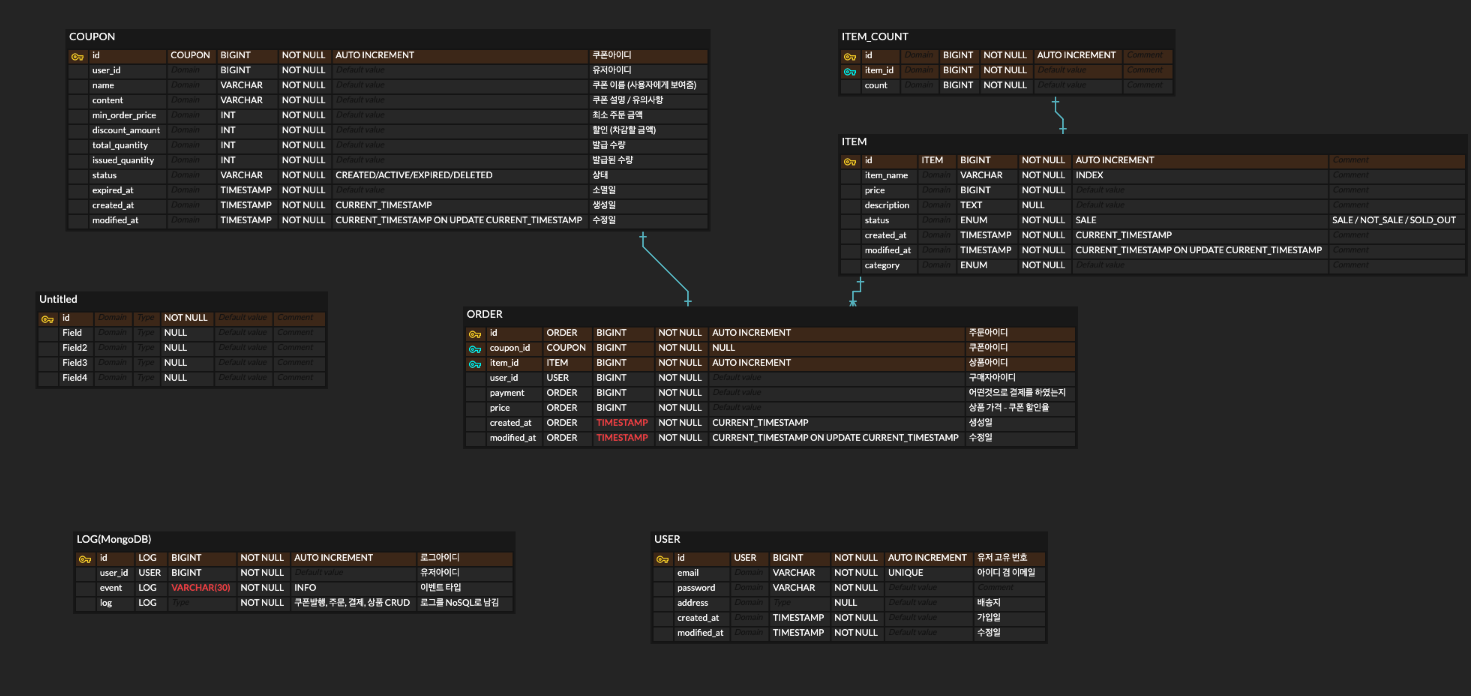
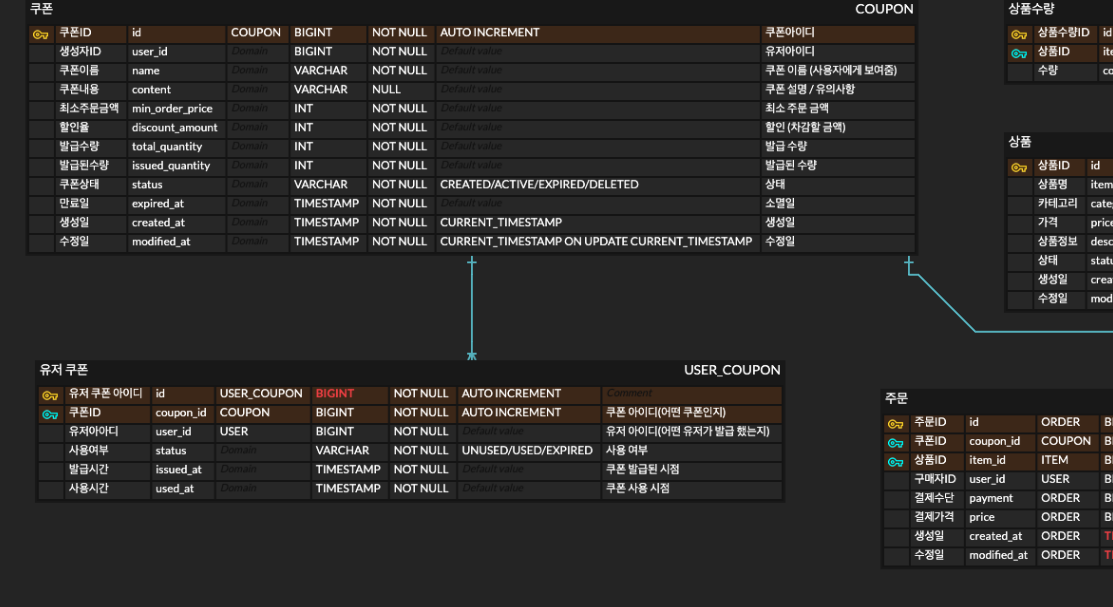
erd 작성부터.
저는 coupon을 맡게 되었습니다.
coupon테이블로만 하려했는데, user_id가 걸려서 고민하다가 테이블 하나 새로 파는게 더 관리하기 좋을 것 같아 분리하는 것으로 결정했습니다.
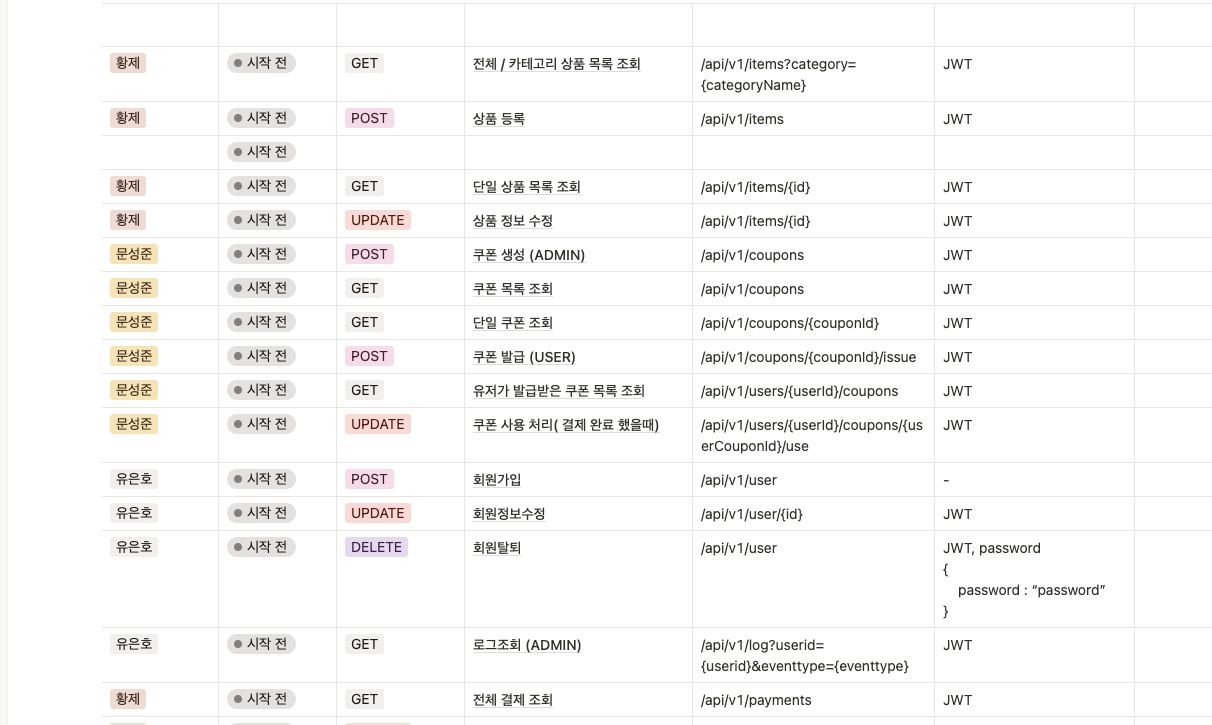
api 명세서는 이렇게 되었으며, 수정 및 추가 사항이 있다면 그때그때 수정하려합니다.
코드 컨벤션은 naver꺼 가져올 것이고, 이것을 InteliJ에서 세팅하고 하려합니다.
https://naver.github.io/hackday-conventions-java/#_intellij
<code_scheme name="Naver-coding-convention-v1.2">
<option name="CLASS_COUNT_TO_USE_IMPORT_ON_DEMAND" value="99" />
<option name="NAMES_COUNT_TO_USE_IMPORT_ON_DEMAND" value="1" />
<option name="IMPORT_LAYOUT_TABLE">
<value>
<emptyLine />
<package name="" withSubpackages="true" static="true" />
<emptyLine />
<package name="java" withSubpackages="true" static="false" />
<emptyLine />
<package name="javax" withSubpackages="true" static="false" />
<emptyLine />
<package name="org" withSubpackages="true" static="false" />
<emptyLine />
<package name="net" withSubpackages="true" static="false" />
<emptyLine />
<package name="com" withSubpackages="true" static="false" />
<emptyLine />
<package name="" withSubpackages="true" static="false" />
<emptyLine />
<package name="com.nhncorp" withSubpackages="true" static="false" />
<emptyLine />
<package name="com.navercorp" withSubpackages="true" static="false" />
<emptyLine />
<package name="com.naver" withSubpackages="true" static="false" />
<emptyLine />
</value>
</option>
<option name="RIGHT_MARGIN" value="120" />
<option name="ENABLE_JAVADOC_FORMATTING" value="false" />
<option name="JD_KEEP_EMPTY_LINES" value="false" />
<option name="FORMATTER_TAGS_ENABLED" value="true" />
<XML>
<option name="XML_LEGACY_SETTINGS_IMPORTED" value="true" />
</XML>
<codeStyleSettings language="JAVA">
<option name="LINE_COMMENT_AT_FIRST_COLUMN" value="false" />
<option name="LINE_COMMENT_ADD_SPACE" value="true" />
<option name="KEEP_FIRST_COLUMN_COMMENT" value="false" />
<option name="KEEP_CONTROL_STATEMENT_IN_ONE_LINE" value="false" />
<option name="KEEP_BLANK_LINES_IN_DECLARATIONS" value="1" />
<option name="KEEP_BLANK_LINES_IN_CODE" value="1" />
<option name="KEEP_BLANK_LINES_BEFORE_RBRACE" value="1" />
<option name="ALIGN_MULTILINE_PARAMETERS" value="false" />
<option name="SPACE_AFTER_TYPE_CAST" value="false" />
<option name="SPACE_BEFORE_ARRAY_INITIALIZER_LBRACE" value="true" />
<option name="CALL_PARAMETERS_WRAP" value="1" />
<option name="METHOD_PARAMETERS_WRAP" value="1" />
<option name="EXTENDS_LIST_WRAP" value="1" />
<option name="METHOD_CALL_CHAIN_WRAP" value="5" />
<option name="THROWS_LIST_WRAP" value="5" />
<option name="EXTENDS_KEYWORD_WRAP" value="1" />
<option name="BINARY_OPERATION_WRAP" value="1" />
<option name="BINARY_OPERATION_SIGN_ON_NEXT_LINE" value="true" />
<option name="TERNARY_OPERATION_WRAP" value="1" />
<option name="ARRAY_INITIALIZER_WRAP" value="1" />
<indentOptions>
<option name="CONTINUATION_INDENT_SIZE" value="4" />
<option name="USE_TAB_CHARACTER" value="true" />
</indentOptions>
</codeStyleSettings>
</code_scheme>
하기에 앞서 동시성 관련 테스트를 어떻게 할 수 있을까 ?
redis를 공부하면 되는 것일까? 뭘 공부해야할까 ? 라는 고민과 생각에 빠졌습니다.
동시성 관련해서 쿠폰 관련된 동시성 처리에 관련한 어떤 공부들을 해야하는 것이지 ?
테스트의 목적, 동시성 테스트로 무엇을 검증하는 것일까 ?
1. 중복 발급 방지 : 한 유저가 쿠폰 여러 번 못 받도록
2. 발급 수량 초과 방지 : 100개가 제한인데, 110개 발급되면 안되는거.
3. 레이스 컨디션 방지 : 동시에 요청해도 발급 수량 안정적으로 증가.
4. 선착순 쿠폰 발급 (2번이랑 유사한 것 같긴 한데, 생각한거라 일단 적어둠)
그렇다면 나는 어떤 것들을 공부해야 하는 것일까 ??
Step 1: 멀티스레드 테스트 코드 작성법
여러 스레드가 동시에 API or 서비스 메서드 호출
- ExecutorService, CountDownLatch, CompletableFuture 등
예: 동시에 100개 요청 날리는 테스트 만들기
📘 검색 키워드: ava concurrent testing, ExecutorService concurrency test, Junit with concurrency
Step 2: Redis 분산락 개념과 사용법
동시 요청을 Redis Lock으로 어떻게 막을 수 있는가?
- Redisson or Lettuce로 락 구현하기
- TTL, deadlock 방지, 재시도 전략 등 이해하기
📘 공부 키워드: Redis distributed lock, Redisson tryLock, Lettuce with Redis lock
Step 3: 테스트 환경에서 실제 동시성 검증
실제로 100명이 동시에 요청 보냈을 때 어떻게 되는가?
- JUnit + 멀티스레드
- JMeter, Postman Runner, Apache Benchmark 등으로 API 부하 테스트
(안형욱 튜터님의 피드백으로 인해, JMeter를 학습하고 적용할 계획입니다)
Step 4: DB 트랜잭션 격리 수준 + 비관적/낙관적 락
DB 레벨의 동시성 전략 이해
- @Transactional
- @Lock(LockModeType.PESSIMISTIC_WRITE) 등 JPA 사용법
- SELECT FOR UPDATE, version 필드 등
📘 공부 키워드: Spring @Transactional with concurrency, JPA pessimistic lock vs optimistic lock
Redis는 수단일 뿐이지, 전부가 아닙니다.
즉, Redis 분산락은 좋은 도구이지만, 테스트하려면 Java의 동시성 처리 + 락 전후 상태 확인법 + API 테스트 도구 사용법 까지 알아야 합니다.
즉,

이렇게 생각해서 Redis 락으로 고려했지만, 트랜잭션 중심의 JPA 환경이라 비관적 락을 선택해서 진행하려 합니다.

Jpa 락을 선호하는 이유
- redis 락은 별도 인프라 필요
- Redis 락 쓰려면 Redis를 설치하고, 설정하고, 연결해야 함.
그리고 락은 잘못 쓰면 Deadlock이나 락 풀리지 않는 문제도 생길 수 있고,
과제나 소규모 프로젝트에선 오버엔지니어링일 수 있다고 생각합니다.
❗ JPA 락은 이미 사용하는 DB와 트랜잭션 안에서 해결 가능
- Jpa 락은 트랜잭션에 완~~전히 통합돼 있음
- 비관적 락: @Transactional 범위 내에서 DB가 직접 락을 보장
- 낙관적 락: @Version만 써도 동시 수정 감지 가능
👉 별도 락 관리 안 해도 되고, 스프링 트랜잭션만 잘 설정하면 됨
- 적은 트래픽, 단일 서버 환경엔 jpa 락이 더 적합하다고 판단
- Redis 락은 분산 환경에서 여러 인스턴스 간 락을 공유해야 할 때 강력
하지만 로컬 개발 or 단일 서버 or 컨트롤된 테스트 상황이면 JPA 락이 훨씬 간단하고 안정적임.
실무에서도 작은 서비스는 DB 락으로 충분히 커버함
- 테스트와 디버깅이 쉬워짐
- Redis 락은 잘못 설정하면 무한 대기, TTL 문제 등 디버깅 어려움
- JPA 락은 그냥 DB 트랜잭션 안에서 발생 → 로그로 다 확인 가능
- 결론
- 제가 생각 했을때, Redis 락 도입하면 -> 의존성, 설정, 레디슨 클라이언트, TTL 관리 등 신경 쓸 게 많아진다.
- 과제의 포커싱을 생각해봤을때, 포커싱은 "동시성 문제 인지 + 제어 능력"이라고 판단했습니다.
즉, 이번 프로젝트는 "인프라 구성 능력"이 아니라고 판단했기 때문입니다.
그래도 학습
실질적인 서비스에선 동시성을 처리하는 부분은 애플리케이션 단이기 때문에, db 단의 lock은 개념적인 부분으로 이해하고, 실무에서는 애플리케이션 단의 동시성 처리가 중요함 (출처)
(테스트 코드엔 트랜잭셔널 어노테이션이 들어가면 안된다)
테스트 코드의 여정, 통합에서 unit로, 그 너머 완성으로
처음에 테스트 코드를 작성 할 때엔 통합 테스트 단위로 하면서 데이터를 직접 때려박았었는데, 이후엔 피드백을 통해 목이랑 인젝션 목 쓰고 리플렉션 쓰면서 테스트 코드를 전반적으로 수정했습니다.
테스트 코드 여정
이번 쿠폰 기능을 구현하며 가장 공들인 부분 중 하나는 바로 테스트 코드였다.
1단계: 통합 테스트로 시작
시작은 통합 테스트였다.
처음에는 @SpringBootTest + 실제 DB(H2) 기반의 통합 테스트로 시작했다.
“기능 전체가 잘 돌아가는지 확인하는 게 우선”이라는 생각이었고,
실제 흐름을 따라가는 방식이라 안정감도 느껴졌었다.
초기 테스트는 서비스 메서드를 호출하고,
실제로 데이터베이스에 insert, update가 일어나는 걸 확인하며 검증했다.
“쿠폰이 실제로 발급되는가?”
“중복 발급 예외가 제대로 발생하는가?”
기능을 빠르게 확인하고, 한눈에 흐름을 볼 수 있다는 점에선 좋았지만…
문제는 곧 드러났다.
테스트가 늘어나자, 문제가 시작됐다
기능이 많아지고 테스트가 복잡해지면서
“이 테스트가 실패한 이유가 DB 때문인지, 서비스 로직 때문인지 헷갈리는” 상황이 생겼다.
한두 개 테스트는 빠르게 돌았지만, 수십 개로 늘어나자 속도도 느려졌고,
실패 로그가 나오면 원인이 DB 세팅인지, 트랜잭션인지, 서비스 로직인지 알기 어려워졌다.
또한, 매번 @Transactional, @Rollback, 데이터 초기화 등 복잡한 설정이 필요해졌고
특정 테스트는 다른 테스트와 충돌하는 일도 생겼다.
실패 로그가 나왔을때 명확하게, "어? 이거 저장이 안 된 건가?"
"아니면 예외가 안 터진 건가?", 아니면 "롤백이 안 된 건가…?"
이런 식으로 눈 빠지게 찾는 과정이 생각보다 잦아져 원인 추적이 생각보다 많이 번거롭고,
디버깅이 생각보다 까다롭고 불편했다.
2단계: 단위 테스트로 전환
그래서 방향을 바꿨다.
“정말 이 메서드의 로직만 검증하고 싶다면 굳이 전체 어플리케이션을 띄울 필요가 있을까?”
➡ 바로 Mockito 기반의 단위 테스트로 전환하기 시작했다.
- @Mock과 @InjectMocks를 활용해 Repository나 의존 객체를 가짜로 설정했다.
(ReflectionTestUtils.setField()를 사용해 엔티티의 ID 등도 직접 세팅했다)
덕분에 DB 연결 없이도 로직 검증이 가능해졌고,
예외 발생 여부, 내부 조건 분기, 호출 여부 등을 명확하게 테스트할 수 있었다.
- “쿠폰이 이미 발급된 경우 예외가 잘 나는가?”
- “수량 초과 시 발급을 막는가?”
- “정상적인 경우엔 발급이 이루어지는가?”
하나하나 로직을 쪼개서, 명확하게 책임을 나눠 테스트할 수 있게 되었다.
이와 더불어 실제 DB 없이도 예외 상황을 컨트롤할 수 있어, 예외 메시지나 동작 흐름 테스트가 수월해짐에 편안함을 느끼게 되었다.
3단계: Reflection으로 엔티티 ID 세팅
단위 테스트 중 ID 값을 필요로 하는 경우가 있었는데, JPA에선 ID가 DB 저장 후에 자동 생성되기 때문에 애를 먹었다.
이 문제는 ReflectionTestUtils.setField()를 사용해 직접 엔티티 ID를 세팅하는 방식으로 해결했다.
ReflectionTestUtils.setField(coupon, "id", 1L);
이 방식 덕분에 JPA에 의존하지 않고도 ID 기반 로직을 테스트할 수 있었고, 전체 테스트 흐름도 더 단단해졌다.
결과
처음엔 “돌아가기만 하면 된다”는 마음으로 통합 테스트를 썼지만,
점점 “정확히 무엇을 검증하고 싶은가”에 집중하며 테스트도 발전하다 보니,
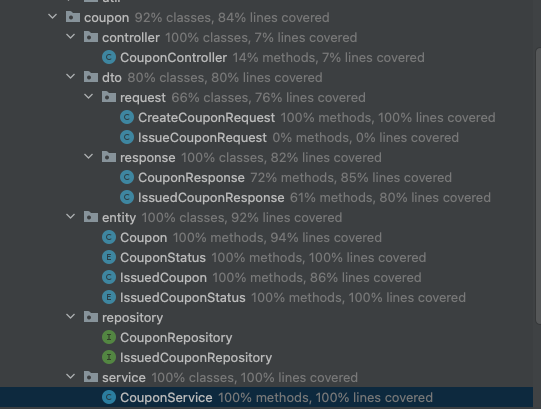
테스트 코드의 라인 커버리지 100%에 가깝게 최대한 열심히 작성하게 되었으며,
성공/실패, 예외 상황을 각각의 unit 테스트 메서드로 분리하며 명확하게 검증했다.
실제 운영 환경에서 발생할 수 있는 시나리오를 고민하고, 생각하여 모두 커버할 수 있도록 준비한 덕분에, JMeter 테스트 시에도 신뢰할 수 있는 결과를 얻을 수 있었다.
느낀점
이 테스트 코드 작성 경험은 단순히 "돌아가는 코드"를 넘어서,
"신뢰할 수 있는 코드"를 만ㄷ느느 방법을 배우는 값진 시간이자 경험이었으며,
이제는 테스트를 작성할 때마다 “이 로직은 단위 테스트로 빠질 수 있을까?”,
“여기서 어떤 예외를 검증해야 하지?”를 고민하게 됐고, 그 덕분에 서비스 로직도 더 명확하고 깔끔해졌다.
앞으로도 테스트는 단순 커버리지가 아니라 "품질과 구조를 점검하는 기회"로 삼아야겠다는 교훈을 얻게 되었다.
