스택과 큐는 배열에서 발전된 형태의 자료구조입니다.
스택
- 삽입과 삭제 연산이 LIFO (Last In First Out) --> 후입 선출 로 이루어진 자료구조입니다.
- 삽입 삭제가 단방향입니다. (운영체제 참고)
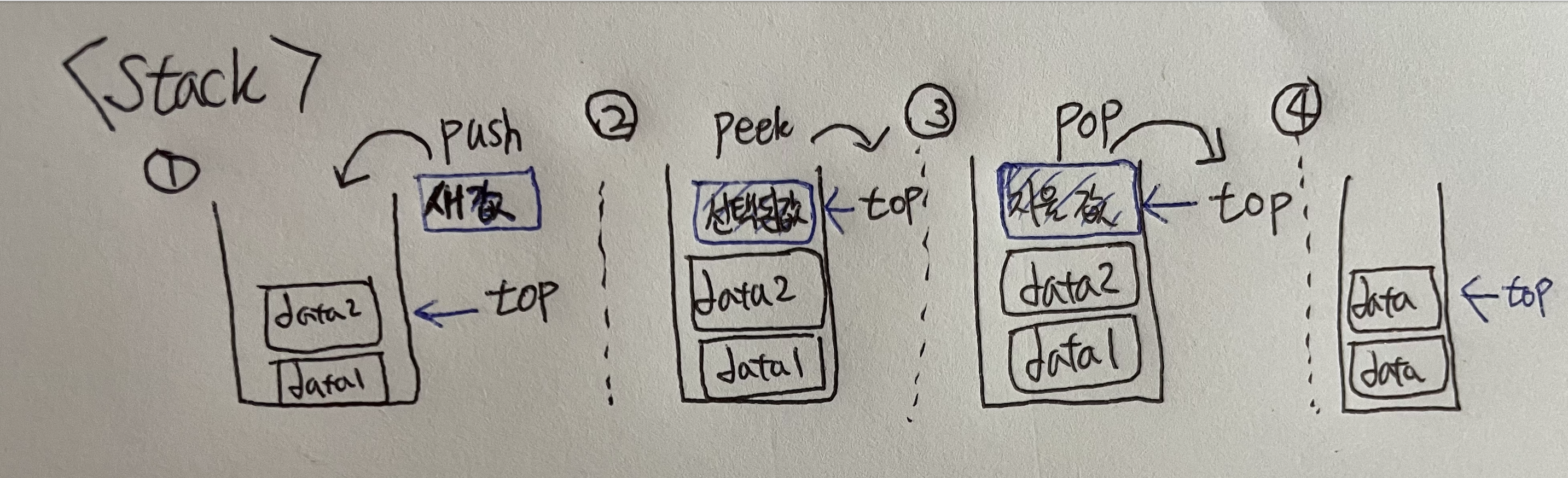
로직 및 그림설명
- 스택에 들어가면, top이 새 값을 가리킴.
- 스택에서 값을 빼낼 때,
pop은top이 가리키는 값을 스택에서 빼내옴. --> 후입선출로 진행됨
장독대를 생각하면 쉽습니다.
장독대에 김치를 보관하며, 제일 위에 있는 김치부터 꺼내먹는다고 생각하시면 됩니다.
(제일 아래 김치는 꺼내기 어려워서 보통 위에서 부터 먹지않나요..? ㅎㅎ)
스택 용어
-
top: 삽입 및 삭제가 일어나는 현재 위치 -> 팝 작업의 스택은 맨 위(top)에 있는 데이터를 삭제하고 반환함. -
pop: top 위치에 현재 있는 데이터를 삭제하고 확인하는 연산. --> 스택에서 데이터 삭제하는 과정을pop -
push: top 위치에 새로운 데이터를 삽입하는 연산 --> 스택에서 데이터 추가할 때, 사용한다고 보면됨. -
peek: top 위치의 데이터를 확인할 때 씀.
참고
스택은 DFS (깊이 우선 탐색, Depth First Search), 백트래킹 종류의 코테에 효과적임.
애초에, 후입선출 LIFO 자체가 재귀 함수 알고리즘 원리와 동일하기 때문입니다.
스택 공부하는 순서
큐
- 삽입과 삭제 연산이 FIFO (선입선출, First In First Out) --> 선입 선출로 이루어진 자료구조
- 삽입과 삭제가 양방향입니다.
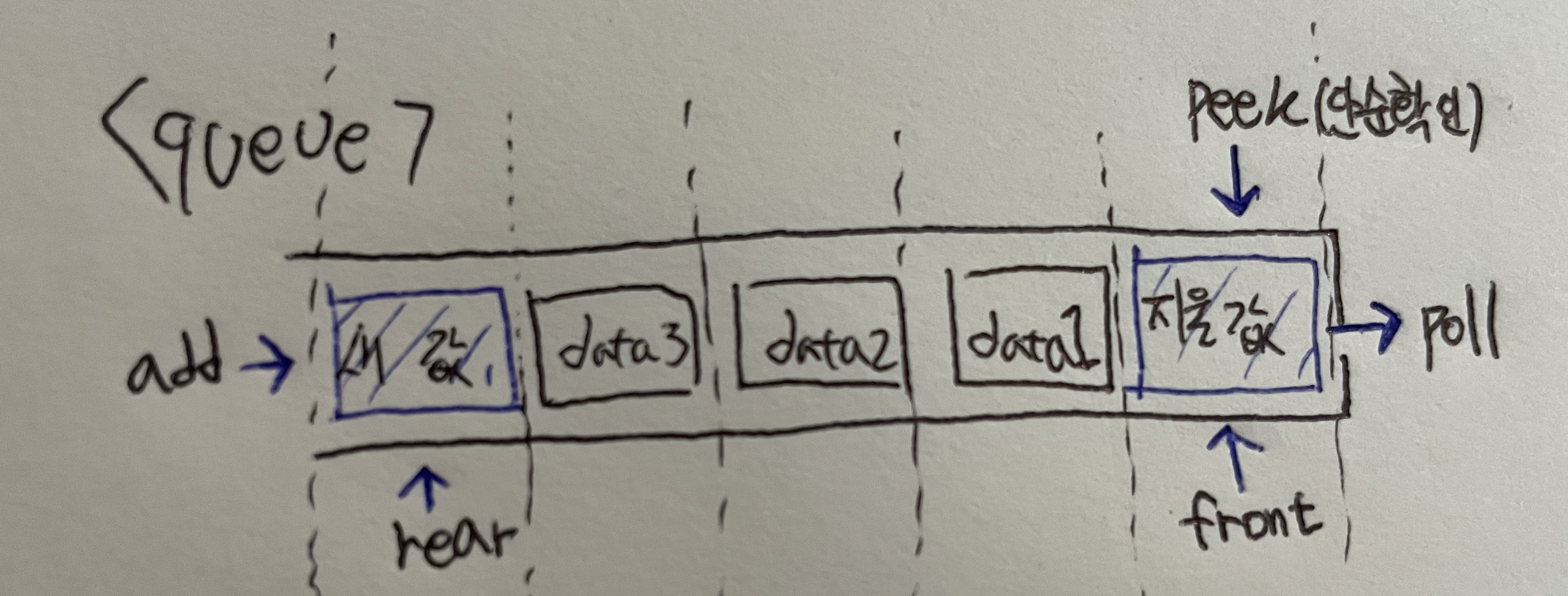
로직 및 그림설명
새 값 추가는 큐의 rear에서 이루어지며, 삭제는 큐의 front에서 이루어집니다.
지금 스펙트럼처럼 일자로 설명했지만, 이해하기 쉽게 생각하면 종이컵 보관함이라고 보시면 됩니다.
(먼저 추가된, 아래에서부터 뽑아먹기 때문+ 새로운 컵은 위에서부터 채움)
큐 용어
-
rear: 큐에서 가장 끝 데이터를 가리킴 --> 마지막으로 추가된 데이터 -
front: 가장 앞 데이터 --> 처음 추가된 데이터 -
add: rear 부분에 새로운 데이터 삽입(추가) --> 마지막으로 추가된 데이터에 추가한다고 보면됨. -
poll: front 부분에 있는 데이터를 삭제하고 확인하는 연산 --> 처음 추가된 데이터 확인 및 연산함. -
peek: 큐의 front의 데이터를 확인할 때 사용함
참고
큐는 BFS (너비 우선 탐색, Breadth First Search) 에서 자주 사용함.
쉽게 비교 한다면
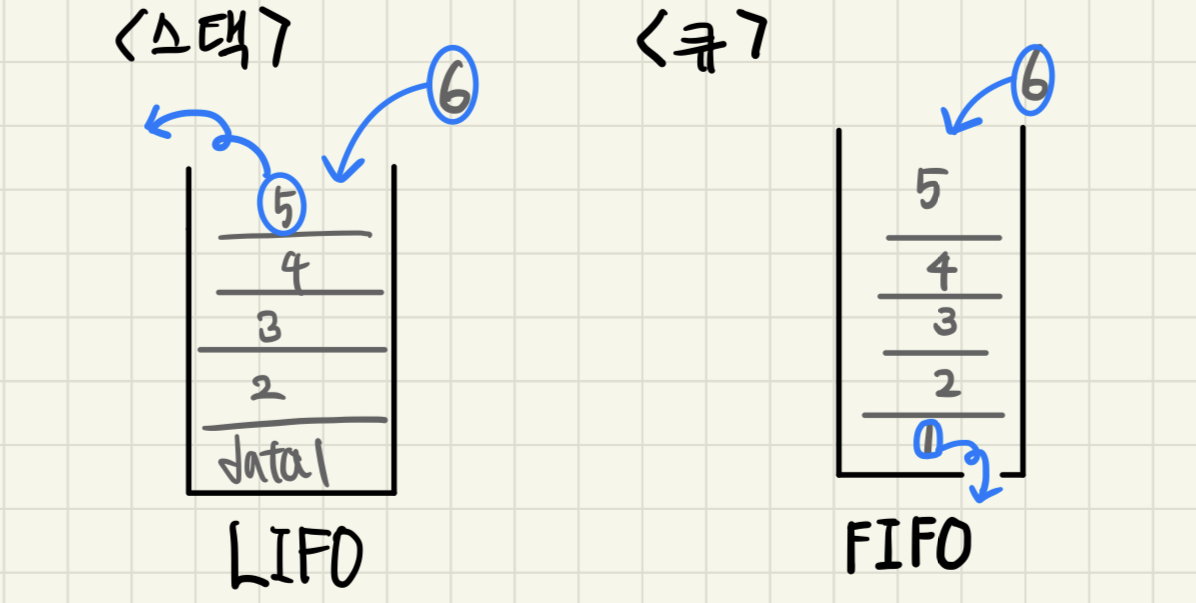
위 그림으로 확인해보면, 스택과 큐의 차이를 쉽게 인지할 수 있습니다.
우선순위 큐
추가적으로, 우선순위 큐는 우선순위가 높으면 데이터가 먼저 나오는 자료구조입니다.
큐 설정에 따라 front에 항상 최대 또는 최소값이 위치합니다.
쉽게 생각하면, 우선순위 스케줄링을 떠오르거나 비선점의 HRN (Highest Response Ratio Next, 최고 응답률 스케줄링)을 생각하시면 될 것 같습니다.
