23.07.13 너비 우선 탐색 알고리즘에 대해 study하였습니다.
BFS(Breadth-First Search, 너비 우선 탐색)는 그래프에서 모든 정점을 방문하는 방법 중 하나로, 시작 정점에서부터 인접한 정점들을 모두 방문한 후에 방문한 정점을 기준으로 다시 인접한 정점들을 차례로 방문하는 순환이 진행되는 방식입니다.
이 방식을 통해 그래프의 모든 정점을 누락없이 한 번씩 방문할 수 있습니다.
BFS, 너비우선 탐색

BFS(Breadth-First Search, 너비 우선 탐색)는 그래프에서 모든 정점을 방문하는 방법 중 하나로, 시작 정점에서부터 인접한 정점들을 모두 방문한 후에 방문한 정점을 기준으로 다시 인접한 정점들을 차례로 방문하는 순환이 진행되는 방식입니다.
이 방식을 통해 그래프의 모든 정점을 누락없이 한 번씩 방문할 수 있습니다.
BFS는 두 정점 사이의 최단 경로를 찾는 문제나 그래프의 높이를 계산하는 문제에서 효과적으로 사용됩니다.
너비 우선 탐색은 선입선출(FIFO) 방식으로 탐색하므로 큐를 이용해 구현합니다.
CODE
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.Queue;
class Graph {
private int V; // 정점의 수
private ArrayList<ArrayList<Integer>> adjList; // 인접 리스트
public Graph(int V) {
this.V = V;
adjList = new ArrayList<ArrayList<Integer>>(V);
for (int i = 0; i < V; i++) {
adjList.add(new ArrayList<Integer>());
}
}
// 무방향 그래프이므로 양쪽 정점에 모두 간선 추가
public void addEdge(int v, int w) {
adjList.get(v).add(w);
adjList.get(w).add(v);
}
public void BFS(int startVertex) {
boolean[] visited = new boolean[V];
Queue<Integer> queue = new LinkedList<Integer>();
visited[startVertex] = true;
queue.add(startVertex);
while (!queue.isEmpty()) {
int currentVertex = queue.poll();
System.out.print(currentVertex + " ");
for (int i : adjList.get(currentVertex)) {
if (!visited[i]) {
visited[i] = true;
queue.add(i);
}
}
}
}
}
public class Main {
public static void main(String[] args) {
Graph graph = new Graph(6);
graph.addEdge(0, 1);
graph.addEdge(0, 2);
graph.addEdge(1, 3);
graph.addEdge(1, 4);
graph.addEdge(2, 4);
graph.addEdge(3, 4);
graph.addEdge(3, 5);
System.out.print("Breadth-First Search: ");
graph.BFS(0);
}
}로직
- 시작 정점을 큐에 넣고 방문했다고 표시합니다.
- 큐에서 정점을 하나 꺼냅니다. (큐에서 제거)
- 꺼낸 정점에 인접한 정점들을 확인합니다.
(인접한 정점이 방문되지 않았다면 방문 표시를 하고 해당 정점을 큐에 넣습니다) - 큐가 비어있지 않은 경우, 2~3 과정을 반복합니다.
시간복잡도
- BFS에서 정점(Vertex)의 수를 V, 간선(Edge)의 수를 E라고 했을 때, 시간 복잡도는 다음과 같습니다.
-
인접 리스트로 구현된 경우: O(V + E)
각 정점을 한 번씩 방문하고, 정점별로 인접한 간선을 확인해야 하므로 V번과 E번의 시간을 합한 시간이 소요됩니다. -
인접 행렬로 구현된 경우: O(V^2)
각 정점에서 다른 모든 정점과의 관계를 확인하므로, 정점의 개수 V에 대해 V번의 검사를 수행합니다.
따라서 너비 우선 탐색(BFS)의 시간 복잡도는 그래프의 표현 방식에 따라 O(V+E) 또는 O(V^2)가 됩니다.
핵심이론
시작 정점에서부터 동일한 거리에 있는 정점들을 차례로 방문한 후에, 그 다음 거리의 정점들을 방문해 가며 그래프를 순회하는 것입니다. 이는 그래프의 모든 정점을 차례대로 방문하고자 하는 경우에 효율적이며, 최단 경로 문제와 같은 몇몇 사례에서 좋은 결과를 얻을 수 있습니다.
또한, BFS의 핵심 이론은 다음과 같은 특징이 있습니다.
-
동일한 레벨의 정점들을 먼저 방문: 시작 정점에서부터 거리에 따라 동일한 레벨에 있는 정점들을 먼저 방문하며, 모든 정점이 끝난 뒤 다음 레벨의 정점들을 방문합니다.
-
큐(Queue) 사용: BFS는 정점에 방문한 순서를 기록해야 하므로, 먼저 들어온 정점이 먼저 나가는 자료구조인 큐(Queue)를 이용합니다.
-
종료 조건: 큐가 비어있거나 모든 정점을 방문한 경우에 BFS는 종료됩니다.
-
방문 표시: 정점을 방문할 때마다 해당 정점이 방문된 것임을 표시해야 합니다. 이 방법은 중복해서 정점을 방문하는 것을 방지하며, BFS 과정의 효율성을 높입니다.
이러한 방법들을 통해, 최단 경로를 찾는 문제나 그래프의 높이를 계산하는 문제 등 다양한 문제에 효과적으로 접근할 수 있습니다.
간단히 정리하면
- BFS를 시작할 노드를 정한 후 사용할 자료구조 초기화
- 큐에서 노드를 꺼낸 후 꺼낸 노드의 인접 노드를 다시 큐에 삽입하기
- 큐 자료구조에 값이 없을 때까지 반복하기
이렇게 이해하기 쉽게 정리할 수 있습니다.
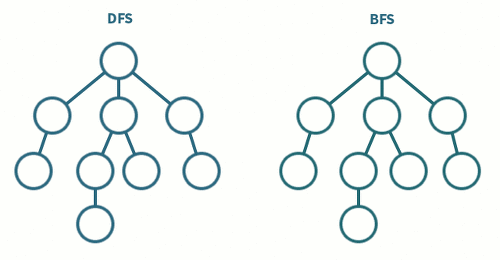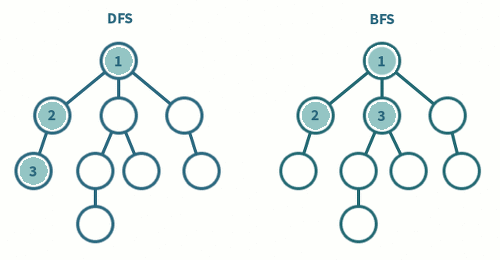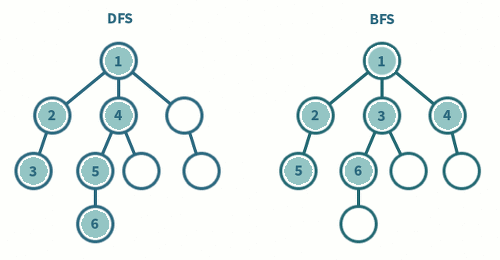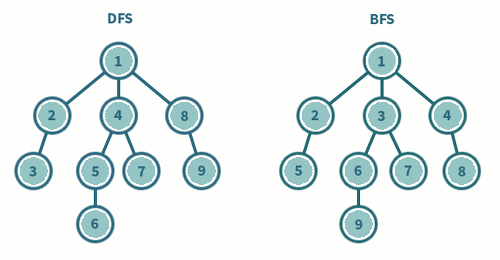
BFS와 DFS 의 차이점
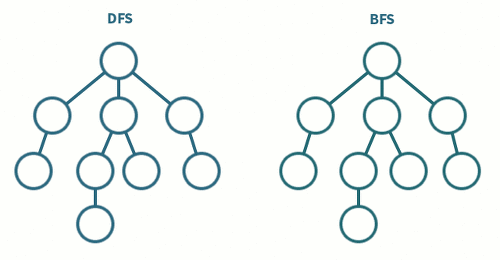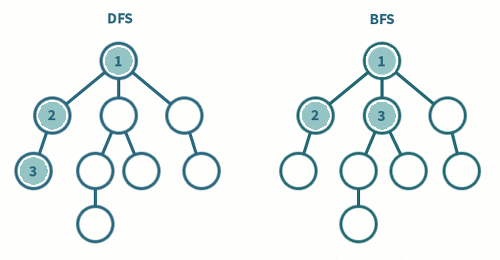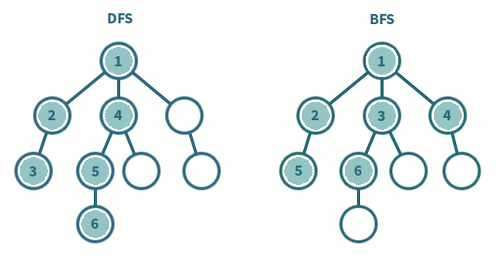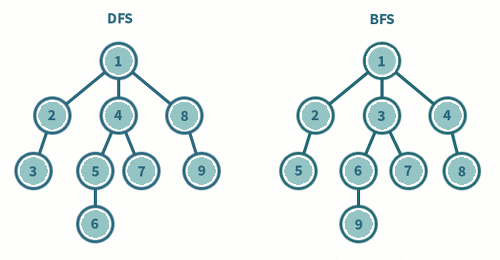
둘 다그래프를 돌아다니며 모든 정점을 방문하는 두 가지 대표적인 알고리즘입니다. 이들의 차이는 탐색 방식과 사용되는 자료구조의 차이가 있습니다.
탐색 방식
-
BFS: 시작 정점에서 동일한 거리에 있는 정점들을 먼저 방문하고, 차례로 다음 거리의 정점들을 방문하는 방식입니다. BFS에서는 모든 인접한 정점들을 먼저 방문한 후에 다음 레벨의 정점들로 이동합니다.
-
DFS: 시작 정점에서 한 방향으로 가능한 깊이까지 탐색한 후, 다시 돌아와 다른 방향으로 계속해서 깊이를 탐색하는 방식입니다. DFS에서는 한 경로의 정점들을 끝까지 탐색하고 다시 돌아와 방문하지 않은 정점으로 나아갑니다.
사용되는 자료구조
-
BFS: 정점의 방문 순서를 기록하기 위해 큐를 사용합니다.
-
DFS: 깊이를 따라 정점을 방문하는 순서를 기록하기 위해 스택이나 재귀를 사용합니다.
시간복잡도
시간 복잡도 측면에서 BFS와 DFS는 유사한 특성을 가지고 있습니다.
무방향 그래프를 기준으로 BFS와 DFS의 시간 복잡도는 다음과 같습니다.
인접 리스트로 구현된 경우
-
BFS: O(V + E)
-
DFS: O(V + E) 이 때, V는 정점의 수고, E는 간선의 수입니다.
인접 행렬로 구현된 경우
-
BFS: O(V^2)
-
DFS: O(V^2)
정리
여기서 둘 간의 차이는 문제의 특성에 따라 이러한 시간 복잡도가 실제로 어떻게 동작하는지에 따라 결정하게 됩니다.
예를 든다면, 최단 경로를 찾는 문제에서는 BFS가 더 적합하며, 그래프의 모든 경로를 찾는 문제에서는 DFS가 더 적합합니다.
따라서, 문제가 어떤 것을 요구 하는지에 따라 맞는 알고리즘을 선택하여 풀이하시면 될 것 같습니다.
