
개요
Bookking 프로젝트에서는 사용자의 검색 편의성을 향상시키기 위해 자동완성 기능을 구현하였으며,
목표는 사용자가 입력 중인 키워드에 대해 도서 제목을 정확히 연관되어있는 것으로 추천하는 것이었습니다.
기능은 다음과 같은 단계로 점진적으로 고도화되었습니다.
- V1 : match_phrase_prefix를 활용한 형태소 기반 자동완성
- V2 : prefix 쿼리를 활용하여 "문장 접두어" 기반 필터링 도입
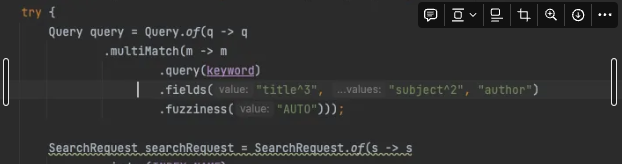
- V3 : multi_match + 필드에 부스트(가중치) 설정으로 연관도 기반 정렬 기능 강화
이 과정에서 다양한 검색 결과 이상 현상, 기대와 다른 정렬 결과, 중복 응답 등의 문제가 발생했고,
그에 따라 정확한 원인 분석 및 해결 방안을 적용했습니다.
문제상황
자동 완성 기능 V1 (match_phrase_prefix)
- “자” 입력 시, “모던자바인액션”, “이팩티브 자바” 등 “자”로 시작하지 않는 제목도 결과에 포함되었습니다.
이는 nori 토큰이저가 문장을 형태소 단위로 분리하기 때문에, 제목에 “자”로 시작하는 단어가 포함되기만 해도 결과에 포함되는 현상이었습니다. (정확도 낮음)
자동 완성 기능 V2 (prefix)
- “자”로 시작하는 문장만 정확히 추출되었지만, elasticsearch가 relevance 점수를 계산하지 않기 때문에 ,사용자가 기대하는 연관도 순 정렬이 불가능했고, 결과가 의미없이 나열된 것처럼 보이는 현상이 발생했습니다.
- prefix 쿼리는 "자"로 시작하는 문장 전체를 찾는 데에는 성공.
- 즉, title.keyword 필드 기준 "자"로 시작하는 도서만 결과에 포함됨.
- 예)
O : "자바의 정석", "자바 인 액션"
X : "이펙티브 자바", "모던자바인액션"은 제외됨
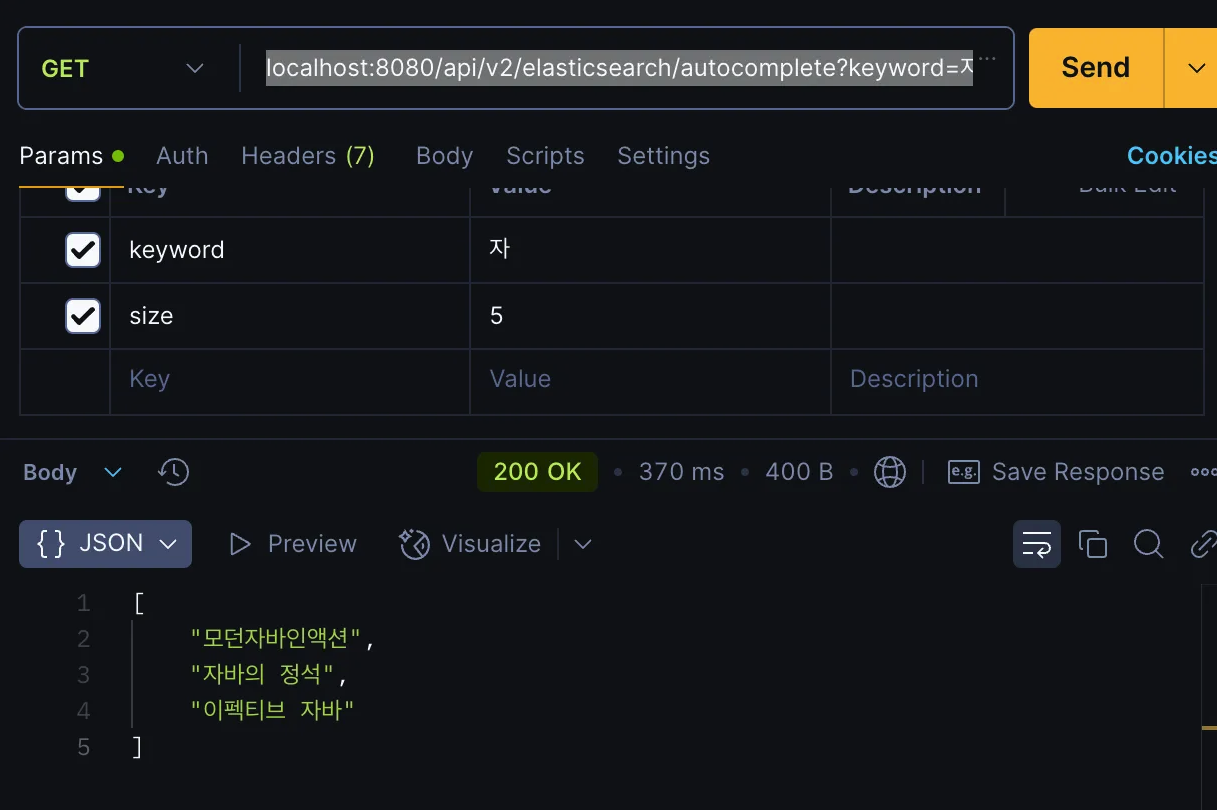
“자”로 시작되는 단어가 나와야하는데 전부 다 나옴
원인 분석
V1 : nori_tokenizer로 인해 “자”(키워드)가 포함된 단어만 있어도 검색됨 (정확도가 낮음)
V2 : 문장 접두어 필터링 (prefix 쿼리는 score를 계산하지 않기에 정렬 기준 없음)
title 필드에 "analyzer": "korean_analyzer"가 적용되어 있어서, 형태소 분석된 토큰의 일부가 '자'로 시작하면 전체 문장이 일치된다고 착각해서 위와같이 결과가 나왔었음.
즉, title에 분석기(korean_analyzer)가 붙은 상태에서 prefix를 쓰면,
"모던자바인액션" → ["모던", "자바", "인", "액션"] 중 "자바"에서 prefix match가 걸려버리게 되는거.
해결방법
V2
“문장 전체가 자로 시작하는 것”만 찾으려면?
.keyword 필드를 지정해서 “분석되지 않은 원본 문자열”을 기준으로 prefix 검색.
{
"query": {
"prefix": {
"title.keyword": {
"value": "자"
}
}
}
}이렇게 해줌으로써 “모던자바인액션” 같은 중간에 키워드가 들어간 것들은 아예 빠지고,
진짜로 “자”(키워드)로 시작하는 “자바의 정석”, “자바의 남궁성”, 등만 나오게 됨.
그래서 title 로만 하면 형태소 분석으로 인해 자바 단어만 매치되어서 잘못된 결과가 나오니까 title.keyword로 줘서 정확하게 접두어로 시작하는 전체 문장만 매칭되게 하면 됩니다.
적용
| 버전 | 쿼리 방식 | 주요 처리 |
|---|---|---|
| V1 | match_phrase_prefix | 형태소 기준 접두어 검색 (정확도 낮음) |
| V2 | prefix + title.keyword | 문장 접두어 필터링 |
| V3 | multi_match + boost | 부스트, 자동 정렬(multi_match), 오타 대응(fuzziness를 AUTO로) |
문제 해결 및 결과
V2
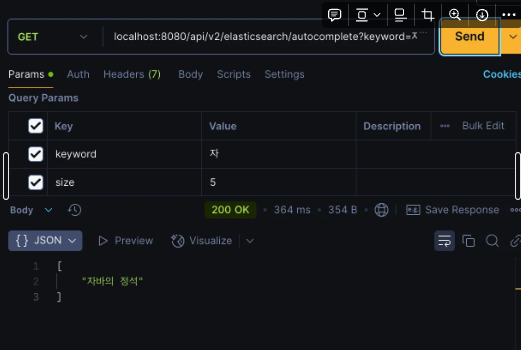
title.keyword 필드와 prefix 쿼리를 활용하여, "자"로 시작하는 도서 제목만 필터링에 성공하였습니다.
"자바의 정석", "자바 인 액션" 등은 포함되었고,
"모던자바인액션", "이펙티브 자바"는 제외됨으로써 정확도는 크게 향상되었습니다.
다만, 정렬 기준이 없어 결과 순서는 색인 순서에 의존하게 되었습니다.
V3
mulit_match 쿼리와 필드별 boost(title^3,…)를 설정하고, fuzziness: AUTO 를 적용하여 오타 대응까지 처리함으로써, 정확도 기반 relevance 정렬 자동 적용이 가능해져
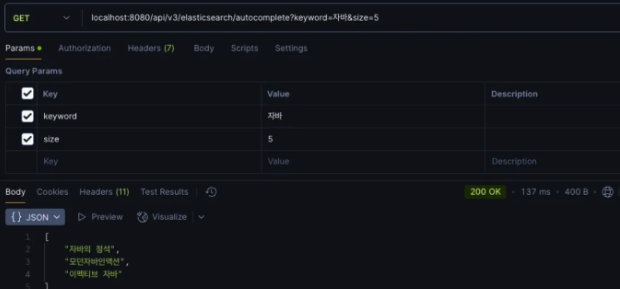
- 자바의 정석이 가장 먼저 출력된 것은 title 필드에 가중치가 적용되었기 때문이며,
모던자바인액션, 이펙티브 자바는 자바 키워드와의 유사성 기준으로 적절하게 정렬되었습니다.
V1~V2에서 발견된 정확도/정렬 문제를 V3에서 완전히 해결했으며, 실사용 환경에서도 자연스러운 추천 결과를 보장할 수 있는 수준까지 고도화하였습니다.
