
이번 글에서는 컴퓨터의 기본적인 memory system, hierarchy에 대해서 살펴보고 그 중 cache 동작의 아주 간단한 원리를 살펴보고자 합니다.
Memory Access
우리가 사용하는 컴퓨터는 기본적으로 폰 노이만 아키텍처를 따르고 있기 때문에 연산을 처리하기 위한 부분인 CPU와 data를 저장하기 위한 memory가 서로 구분되어 있습니다. 따라서 CPU에서 memory에 있는 data를 가져오거나 memory로 data를 저장하려 할 때에는 bus라는 일종의 통로를 통해서 접근해야 합니다. bus의 자세한 동작 원리에 대해서는 나중에 더 자세히 다뤄보도록 하고 지금은 CPU와 memory 사이에 data가 어떻게 오가는지에 대해 간략히 살펴보겠습니다.
아래 그림은 CPU와 memory 사이에 data를 주고 받는 bus structure를 표현한 예시입니다. CPU에서 register 내의 data를 이용한 연산을 처리하는 것은 register file과 ALU 사이의 transaction만 필요하기 때문에 동작을 구현하기 어렵지 않지만 main memory와 transaction 해야 하는 경우는 그렇지 않습니다. 그림에서와 같이 system bus와 memory bus를 통한 transaction이 수행되어야 memory에 access할 수 있기 때문에 그 동작이 더 복잡합니다. 또한 I/O bridge에는 memory 뿐만 아니라 키보드, 마우스 등의 다른 device와도 transaction이 진행되기 때문에 이를 고려해야 합니다. 지금은 main memory와의 transaction만을 살펴보도록 하겠습니다.
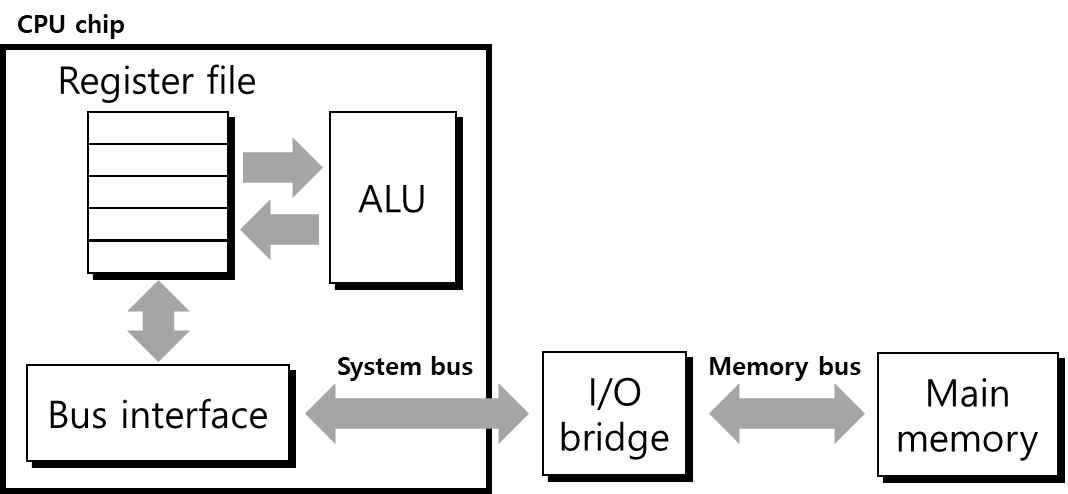
- Read transaction
먼저 movq A, %rax라는 instruction을 수행하는 것을 생각해 보겠습니다. 이는 %rax register에 address A의 data를 load하는 instruction으로 memory에서 data를 가져오도록 해야 합니다. 이를 read transaction이라 합니다. memory read transaction의 과정은 아래 그림과 같이 진행됩니다. 먼저 system bus와 memory bus를 통해 main memory로 address A를 전달합니다. main memory는 address signal을 받아 A에 저장된 data x를 반대로 CPU로 보내줍니다. bus를 통해 전달받은 data x는 %rax register에 저장되면서 read transaction이 마무리됩니다.
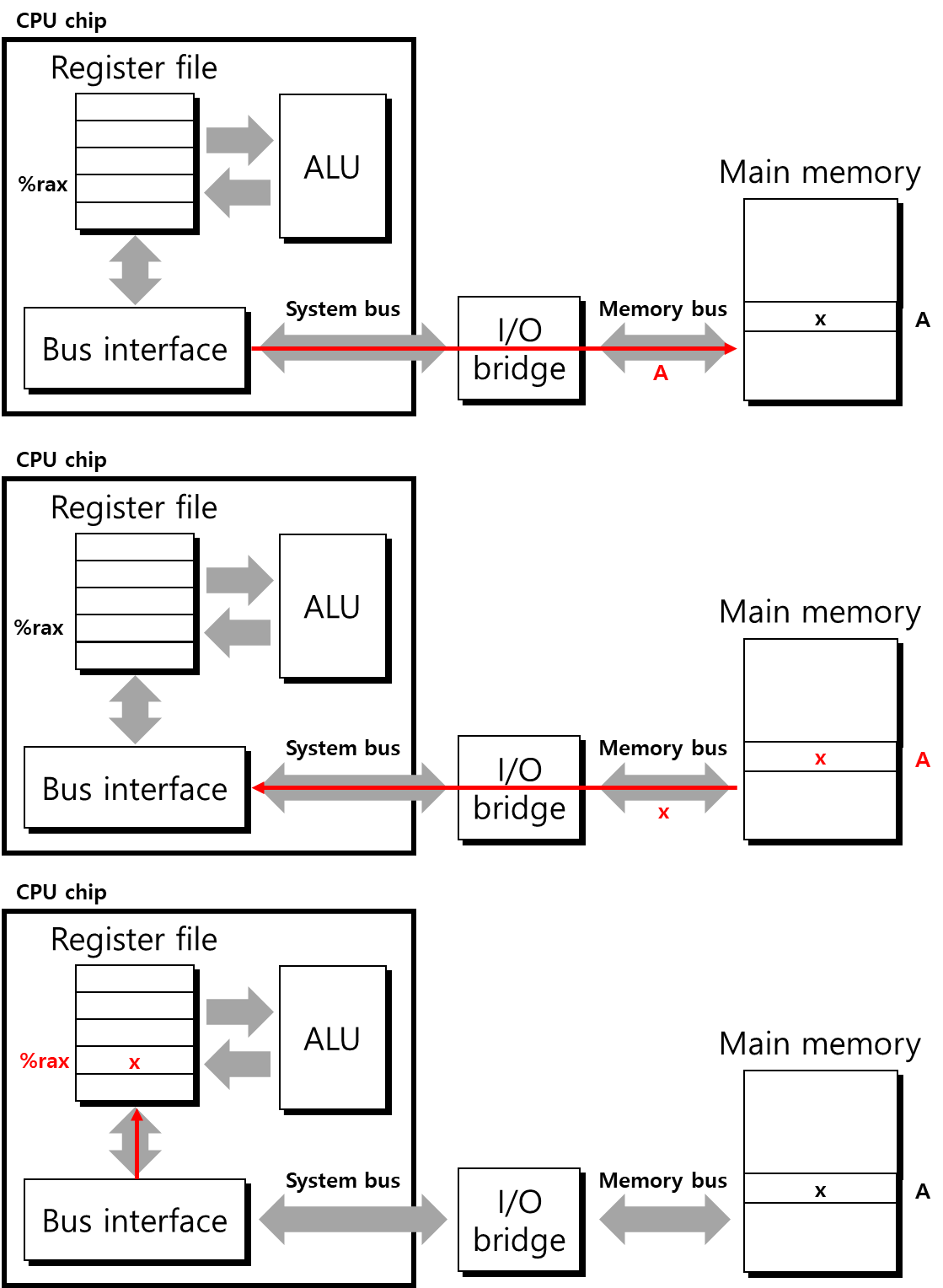
- Write transaction
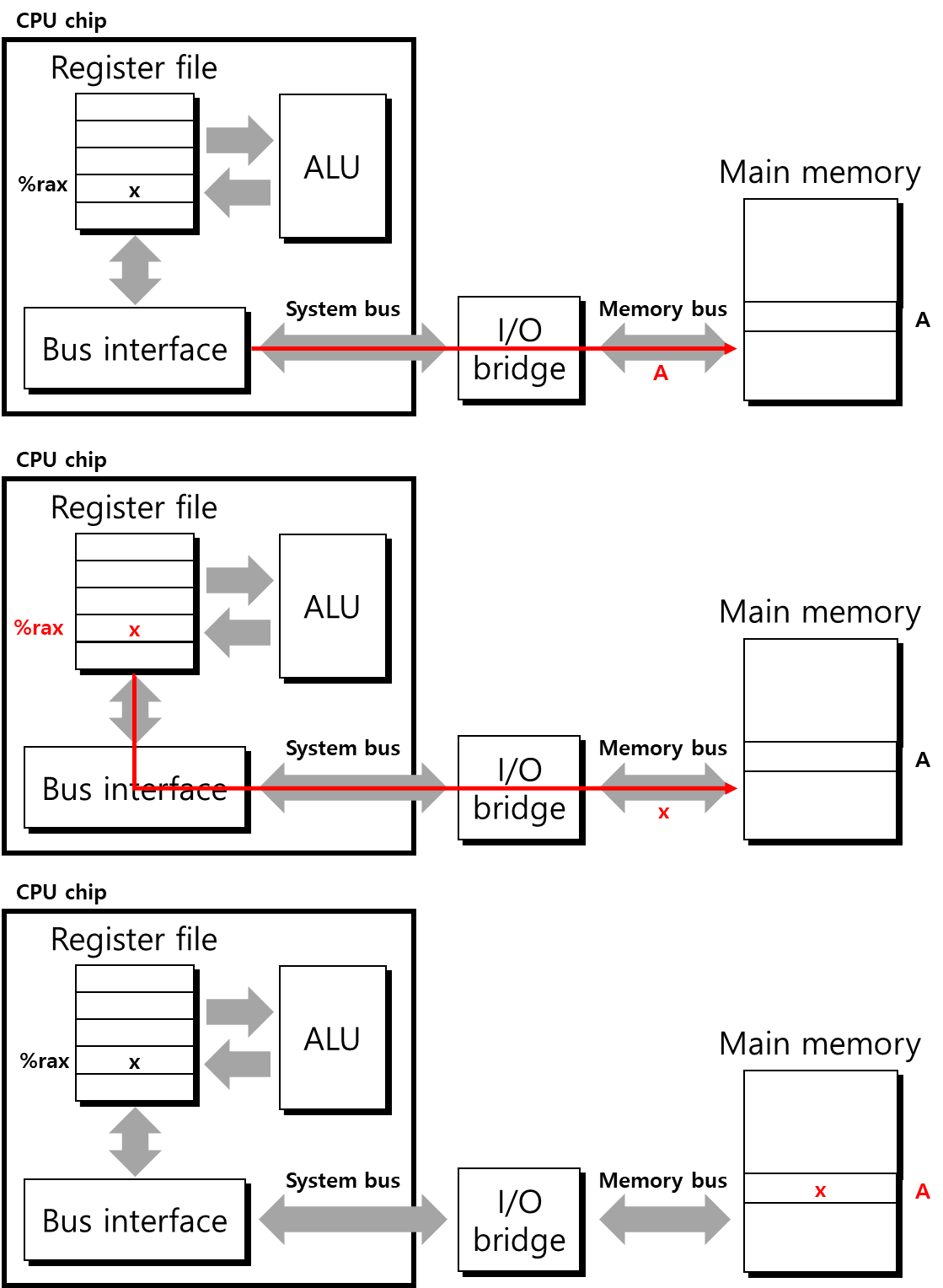
다음으로 movq %rax, A instruction을 보겠습니다. 앞의 예시와는 반대로 %rax register에서 main memory의 address A로 data를 store하는 instruction으로, write transaction에 해당합니다. 이는 아래 그림과 같이 진행됩니다. read transaction과 마찬가지로 먼저 main memory에 address A를 전달합니다. address를 전달받은 main memory는 data를 전달받기 위해 기다립니다. CPU에서는 %rax에 저장된 data x를 copy해 bus로 전달해주고 최종적으로 main memory에서 data를 전달받아 address A에 x를 저장합니다.
Locality
위의 CPU-memory transaction에서 잠시 본 것과 같이 memory에서 data를 가져오거나 저장하는 transaction은 register file 내에 저장된 data를 활용하는 것에 비해 매우 큰 overhead가 존재합니다. 또한 main memory에 사용되는 DRAM의 경우 data를 read, write하기 위한 속도가 SRAM에 비해 매우 느려 이에 대한 overhead도 존재합니다. 하지만 overhead가 어느 정도 완화될 수 있는데, 이는 principle of locality 때문입니다. program이 실행될 때 data와 instruction은 최근 사용한 것과 가까운 위치 또는 동일한 경우가 많다는 것이 principle of locality이며, 비슷한 위치의 data 또는 instruction을 자주 사용하는 program 일수록 locality가 높다고 말합니다. locality에는 다음의 두 가지 종류가 있습니다.
- temporal locality
가장 최근에 reference된 item은 가까운 시간 내에 다시 사용될 가능성이 높다. - spatial locality
근처의 address에 있는 item은 연이어 reference될 가능성이 높다.
아래의 code를 예시로 두 locality에 대해 자세히 알아보겠습니다.
sum = 0;
for (i = 0; i < n; i++)
sum += a[i];
return sum;위의 code는 array a의 n개의 element를 더하는 code입니다. 여기서 data reference의 경우 a의 element가 순차적으로 reference되는 것은 spatial locality에 해당하며, sum이 매 iteration마다 reference되는 것은 temporal locality에 해당합니다. instruction의 경우 instruction들이 순차적으로 실행되는 것이 spatial locality에 해당하며 loop을 통해 동일한 code를 반복해서 실행하는 것을 temporal locality라 합니다.
locality를 고려하여 code를 작성하는 것과 그렇지 않은 것에는 code 동작 시간에 큰 차이를 보여줍니다. 예시로 아래 두 code를 먼저 보겠습니다.
// code1: row majer
int rowmajor(int array[M][N]) {
int i, j, sum = 0;
for (i = 0; i < M; i++) {
for (j = 0; j < N; j++) {
sum += array[i][j];
}
}
return sum;
}
// code2: column major
int columnmajor(int array[M][N]) {
int i, j, sum = 0;
for (i = 0; i < M; i++) {
for (j = 0; j < N; j++) {
sum += array[j][i];
}
}
return sum;
}두 code는 array에 access하는 방식에 차이를 가지고 있습니다. asymtotic analysis로는 두 code의 동작 시간에 차이가 없지만 실제로 code를 실행해보면 rowmajor()가 훨씬 빨리 실행되는 것을 확인할 수 있습니다. 간단하게 M = 3, N = 3인 경우에 두 함수의 access order를 살펴보면 다음과 같습니다.
| address | 0 | 4 | 8 | 12 | 16 | 20 | 24 | 28 | 32 |
|---|---|---|---|---|---|---|---|---|---|
| contents | a00 | a01 | a02 | a10 | a11 | a12 | a20 | a21 | a22 |
rowmajor() | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
columnmajor() | 1 | 4 | 7 | 2 | 5 | 8 | 3 | 6 | 9 |
rowmajor()는 memory address 순서에 맞춰 access하는 반면 columnmajor()는 비슷한 address를 연속적으로 access하는 경우가 없는 것을 볼 수 있습니다. M, N의 크기가 커질수록 columnmajor()에서 access하는 address의 stride가 더 커져 spatial locality가 더 나빠지게 되고, 이는 후에 설명한 cache memory에 관련해 성능을 크게 떨어뜨리는 요인이 됩니다.
Memory hierarchy

위의 그림은 일반적인 컴퓨터의 memory hierarchy에 대한 모식도입니다. 그림에서 위로 갈수록(high level) 더 빠르지만 값이 비싸 많이 사용할 수 없는 memory이고, 반대로 아래로 갈수록(low level) 값이 싸 많은 용량을 구축할 수 있지만 그 속도가 느린 memory입니다. 이 중에서 이번에는 cache에 대해 집중적으로 파악해 보겠습니다.
- Caching in the memory hierarchy
cache는 SRAM으로 만들어지며 access하기 위해 수 cycle이 필요합니다. 수십에서 수백 cycle이 필요한 DRAM에 비해 속도가 빠른 대신 MB 단위의 data만 저장할 수 있기 때문에 processor에서 access하기 위한 data를 DRAM에서 가져와 저장해두는 식으로 활용합니다. 마찬가지로 L2 cache와 L1 cache 사이에도 동일하게 data를 가져와 저장합니다. 이렇게 느린 저장공간의 data object를 빠른 저장공간에 가져와 저장해두는 행위를 caching이라 합니다. 아래 그림과 같이 더 느린 level k+1 storage의 data를 더 빠른 level k storage에 저장하고, 최종적으로 가장 높은 level의 storage인 register에 가져와 process에서 연산을 진행합니다.
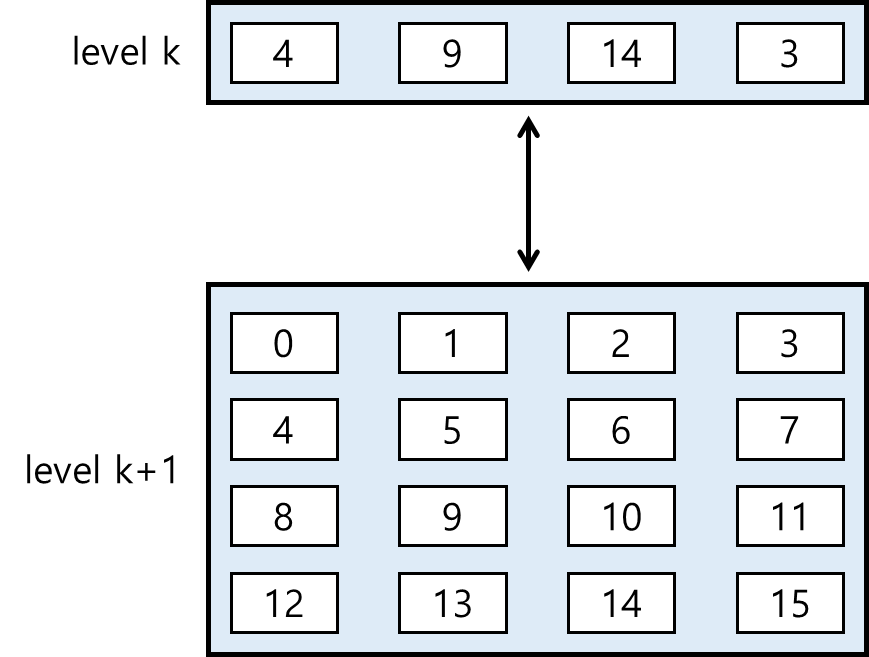
data를 lower level의 memory unit에서 가져올 때 해당 memory에 data가 존재하는 지의 여부에 따라 동작이 달라야 할 것입니다. 예를 들어 위의 그림에서 k = 1, 즉 L1 cache라 생각할 때 process에서 3을 가져오려 한다면 L1 cache에서 data를 바로 가져올 수 있습니다. 이와 같이 원하는 data가 cache에 존재할 때 cache hit이라 합니다. 반면 process에서 1을 가져오려 한다면 이는 L1 cache에 없으므로 L1 cache에서 data 하나를 evict하고 L2 cache에서 1을 가져와야 합니다. 이와 같이 원하는 data가 cache에 없는 경우를 cache miss라 합니다. cache miss는 다음과 같은 이유로 발생할 수 있습니다.
-
cold miss (compulsory miss)
비어있는 cache block에 access해 cache miss가 발생하는 경우 -
conflict miss
placement policy에 의해 cache miss가 발생하는 경우 (같은 cache block에 mapping된 data를 access하려 할 때 발생) -
capacity miss
program의 working set이 cache size보다 커 cache miss가 발생하는 경우
cache miss가 발생하는 경우 더 느린 memory unit에 access해 data를 가져와야 하기 때문에 그 penalty가 매우 큽니다. 따라서 cache miss를 줄이는 것은 processor의 성능을 높이는 데 매우 중요합니다. 실제로 program을 실행시키면 cache miss가 자주 일어나지 않는 것을 볼 수 있는데, 이는 locality에 의한 영향입니다. locality가 높은 경우 같은 address에 자주 access하게 되며 cache에 해당 data가 존재할 확률이 높기 때문에 cache hit이 더 자주 일어나게 됩니다.
앞서 rowmajor()와 columnmajor()를 다시 살펴보면, rowmajor()는 연속된 address의 data를 access하는 반면 columnmajor()는 그 간격이 매우 커질 수 있습니다. 일반적으로 cache에 data를 저장할 때에는 여러 data를 모은 block 단위로 저장하기 때문에 첫 번째 address에 access한 경우 그 다음 몇 개의 address에 저장된 data 또한 cache에 같이 올라오게 됩니다. 이로 인해 rowmajor()로 구현된 code가 더 빠르게 실행되는 결과를 볼 수 있게 됩니다.
reference
Computer System: A Programmer's Perspective, 3rd ed (CS:APP3e), Pearson, 2016
