서울 시의 유동인구, 가게, SNS 데이터 등을 활용하여 시각화해보는 프로젝트이다.
3. 가게
서브웨이 우리동네만 없어….

내가 사는 동네의 상권이 괜찮은지, 핫플레이스라고 할 수 있는지, 소위 말하는 ‘시내’(서울은 전역이 시내이긴 하다) 인지 확인할 수 있는 지표가 있을까 하는 의문에서 출발했다. 친구들끼리 우스갯소리로 이런 말을 하곤 했다.
❓ ‘스타벅스, 버거킹, 올리브영 3대장이 모두 모여있으면 그 주변은 왠만하면 핫플이다.’
과연 실제로 그럴까? 확인해보자.
이 3가지 프렌차이즈에다가 네이버가 선정한 100대 맛집과 서브웨이를 합쳐 ‘동네 핫플레이스 지표’를 만들어보고자 한다.
(이는 서울시에만 적용되는 것은 아니고 전국에 적용될 수 있음을 미리 알린다.)
Preprocessing
1) image → data url
import base64
import pandas as pd
import os
import pickle
os.chdir('F:/Competitions/SeoulHotPlace')
MAPBOX_API_KEY = 'pk.eyJ1IjoibHNqOTg2MiIsImEiOiJja3dkNjMxMDczOHd1MnZtcHl0YmllYWZjIn0.4IFNend5knY9T_h3mv8Bwg'
def image_to_data_url(filename):
ext = filename.split('.')[-1]
prefix = f'data:image/{ext};base64,'
with open(filename, 'rb') as f:
img = f.read()
return prefix + base64.b64encode(img).decode('utf-8')pydeck의 icon layer input으로 이미지를 넣기 위해선 이미지 파일을 url로 변환해주는 작업이 필요하다.
2) icon data 생성 및 데이터 병합
팀원들이 크롤링한 네이버 맛집 Top100, 올리브영, 서브웨이, 버거킹, 스타벅스 데이터를 불러와 ‘icon data’ 컬럼을 생성한다.
icon data는 dictionary 형태로 url, width, height, anchorY 4개의 key를 가지고 있다.
### 1. Naver Top100
# 1.1. Load Data
df_1 = pd.read_csv('https://raw.githubusercontent.com/SungJun98/Seoul_Viz/SungJun98/data/naver_Gabozza_detail.csv', index_col=0)
coordinates = [[x, y] for x, y in zip(df_1.longitude, df_1.latitude)]
df_1['coordinates'] = coordinates
NAVER_ICON_URL = 'https://s.pstatic.net/static/www/mobile/edit/2016/0705/mobile_212852414260.png'
icon_data = {
"url": NAVER_ICON_URL,
"width": 128,
"height": 128,
"anchorY": 128,
}
df_1['icon_data'] = None
for i in df_1.index:
df_1["icon_data"][i] = icon_data
df_1['layer'] = "naver"
### 2. OliveYoung
# 2.1. Load Data
df_2 = pd.read_csv(r'https://raw.githubusercontent.com/SungJun98/Seoul_Viz/SungJun98/data/oliveyoung.csv', index_col=0)
coordinates = [[x, y] for x, y in zip(df_2.longitude, df_2.latitude)]
df_2['coordinates'] = coordinates
OLIVEYOUNG_ICON = r'F:\Competitions\SeoulHotPlace/oliveyoung_logo.png'
icon_64 = image_to_data_url(OLIVEYOUNG_ICON)
icon_data = {
"url": icon_64,
"width": 128,
"height": 128,
"anchorY": 128,
}
df_2['icon_data'] = None
for i in df_2.index:
df_2["icon_data"][i] = icon_data
df_2['layer'] = "oliveyoung"
### 3. Subway
# 3.1. Load Data
df_3 = pd.read_csv(r'https://raw.githubusercontent.com/SungJun98/Seoul_Viz/SungJun98/data/subway.csv', index_col = 0)
coordinates = [[x, y] for x, y in zip(df_3.longitude, df_3.latitude)]
df_3['coordinates'] = coordinates
SUBWAY_ICON_URL = r'F:\Competitions\SeoulHotPlace/subway_logo.png'
icon_64 = image_to_data_url(SUBWAY_ICON_URL)
icon_data = {
"url": icon_64,
"width": 128,
"height": 128,
"anchorY": 128,
}
df_3['icon_data'] = None
for i in df_3.index:
df_3["icon_data"][i] = icon_data
df_3['layer'] = "subway"
### 4. BurgerKing
# 4.1. Load Data
df_4 = pd.read_csv(r'https://raw.githubusercontent.com/SungJun98/Seoul_Viz/SungJun98/data/burgerking.csv', index_col = 0)
coordinates = [[x, y] for x, y in zip(df_4.longitude, df_4.latitude)]
df_4['coordinates'] = coordinates
BURGERKING_ICON = r'https://raw.githubusercontent.com/SungJun98/Seoul_Viz/SungJun98/data/burgerking_logo.png'
#icon_64 = image_to_data_url(BURGERKING_ICON)
icon_data = {
"url": BURGERKING_ICON,
"width": 128,
"height": 128,
"anchorY": 128,
}
df_4['icon_data'] = None
for i in df_4.index:
df_4["icon_data"][i] = icon_data
df_4['layer'] = "burgerking"
### 5. Starbucks
# 5.1. Load Data
df_5 = pd.read_csv(r'https://raw.githubusercontent.com/SungJun98/Seoul_Viz/SungJun98/data/starbucks.csv')
coordinates = [[x, y] for x, y in zip(df_5.longitude, df_5.latitude)]
df_5['coordinates'] = coordinates
STARBUCKS_ICON = r'https://image.istarbucks.co.kr/common/img/common/favicon.ico?v=2008'
icon_data = {
"url": STARBUCKS_ICON,
"width": 128,
"height": 128,
"anchorY": 128,
}
df_5['icon_data'] = None
for i in df_5.index:
df_5["icon_data"][i] = icon_data
df_5['layer'] = "starbucks"
df_list = [df_1, df_2, df_3, df_4, df_5]
df = pd.concat(df_list, ignore_index=True).fillna('None')
with open(r'F:\Competitions\SeoulHotPlace/df.pickle', 'wb') as f:
pickle.dump(df, f, pickle.HIGHEST_PROTOCOL)합친 결과 df는 다음과 같다.
| name | type | address | latitude | longitude | coordinates | icon_data | layer | |
|---|---|---|---|---|---|---|---|---|
| 0 | 런던 베이글 뮤지엄 | 베이커리 | 서울특별시 종로구 북촌로4길 20 | 37.57929 | 126.9861 | [126.9861472, 37.5792893] | {'url':'https://s.pstatic.net/static/www/mobile/edit/2016/0705/mobile_212852414260.png', 'width': 128, 'height': 128, 'anchorY': 128} | naver |
| 1 | 몰또 이탈리안 에스프레소바 | 카페,디저트 | 서울특별시 중구 명동길 73 | 37.56433 | 126.9861 | [126.9860873, 37.564327] | {'url':'https://s.pstatic.net/static/www/mobile/edit/2016/0705/mobile_212852414260.png','width': 128, 'height': 128, 'anchorY': 128} | naver |
| 2 | 난포 | 한식 | 서울특별시 성동구 서울숲4길 18-8 | 37.54705 | 127.0424 | [127.0424257, 37.5470545] | '{url':'https://s.pstatic.net/static/www/mobile/edit/2016/0705/mobile_212852414260.png', 'width': 128, 'height': 128, 'anchorY': 128} | naver |
{kind=link}
{kind=link}
(1,318 rows X 8 columns)
Mapping
잘 합쳐진 데이터프레임을 이전의 유동인구 mapping과 거의 유사한 형태로 진행한다.
app.callback의 input으로 가게의 종류를 checklist형태로 받으면 알맞게 df를 filtering하여 지도에 그려주게 된다.
이번엔 layer를 미리 정의하고 사용하는 것이 아닌 callback 이후에 선언할 함수에 한꺼번에 선언하여 사용해주겠다.
import os
import pydeck as pdk
import dash
import pickle
from dash import dcc, html
from dash.dependencies import Input, Output, State
import dash_deck
os.chdir('F:/Competitions/SeoulHotPlace')
MAPBOX_API_KEY = 'pk.eyJ1IjoibHNqOTg2MiIsImEiOiJja3dkNjMxMDczOHd1MnZtcHl0YmllYWZjIn0.4IFNend5knY9T_h3mv8Bwg'
with open(r'F:\Competitions\SeoulHotPlace/df.pickle', 'rb') as f:
df = pickle.load(f)
with open('./seoul_boundary.pickle', 'rb') as f:
dff = pickle.load(f)1) dash - app.layout
dcc.Checklist에 5개의 가게 형태를 multi input으로 받을 수 있게 주고 update 버튼을 누르면 반영되게 만든다.
colors = {
"background": "#111111",
"text": "#ffffff"
}
app = dash.Dash(__name__)
app.layout = html.Div(
style={"backgroundColor": colors["background"], "width" : "100%"}, children = [
html.Div(
dcc.Checklist(
[
{"label" : "naver", "value": "naver"},
{"label" : "oliveyoung", "value": "oliveyoung"},
{"label" : "subway", "value": "subway"},
{"label" : "burgerking","value": "burgerking"},
{"label" : "starbucks", "value": "starbucks"}
],
value = ["naver", "burgerking"],
id = "store_select",
persistence=True
), style = {'display' : 'inline-block', 'color' : 'white', 'textAlign': 'center','padding': 20}
),
html.A(html.Button('update'), href='/', id = 'update-button'), # 페이지 새로고침 버튼
html.Br(),
html.Div(
id = "deck-gl",
style={
"width": "90%",
"padding-left" : "5%",
"padding-right" : "5%",
"height": "93vh",
"display": "inline-block",
"position": "relative"
},
children = []
)
]
)코드를 구현할 때 약간의 트릭(?)을 사용하였는데, 초반부의 시도에서 Checklist에서 multi=True 옵션으로 interactive하게 적용시키는 방법이 통하지 않았기 때문이다.
checklist를 잘 구현해서 여러 개의 가게를 체크해도 updating 된다는 표현만 뜨고 실제로 지도는 업데이트 되지 않았기 때문이다. (icon이 뜨지 않는 것은 덤이였다.)
❗ 다른 시도가 모두 실패하자 **오히려 이 사실을 이용하는 방법을 생각해봤다.
실제로 checklist에 여러 개의 가게를 체크한 이후 페이지를 새로고침해도 체크한 것들이 유지된다는 사실을 이용해서
update 버튼을 새로고침 버튼으로 만들었다.(html.Button 함수의 href 인자의 값을 ‘/’로 주면 새로고침 버튼이 된다! )
2) dash - app.callback
유동인구와 마찬가지로 서울시 경계 layer를 쌓고 그 위에 icon layer를 쌓아서 지도가 구현되게 만들었다.
@app.callback(
Output(component_id = "deck-gl", component_property = "children"),
[Input(component_id = "store_select", component_property = "value"),
State(component_id = "update-button", component_property = "n_clicks")]
)
def make_layer(store_type, n_clicks):
dat = df[df.layer.isin(store_type)]
# boundary layer
boundary_layer = pdk.Layer(
'PolygonLayer',
dff,
get_polygon = 'coordinates',
get_fill_color = '[128, 128, 128]',
pickable = True,
auto_highlight = True,
opacity = 0.05
)
# icon layer
icon_layer = pdk.Layer(
"IconLayer",
dat,
get_icon="icon_data",
get_size=6,
size_scale=3,
get_position="coordinates",
pickable=True,
auto_highlight=True
)
### Set the viewport location
center = [126.986, 37.565]
view_state = pdk.ViewState(longitude=center[0], latitude=center[1], zoom=11)
r = pdk.Deck(layers=[boundary_layer, icon_layer], initial_view_state=view_state, mapbox_key=MAPBOX_API_KEY)
return dash_deck.DeckGL(r.to_json(), id = "deck-gl", tooltip = True, mapboxKey=r.mapbox_key)
if __name__ == "__main__":
app.run_server(debug=True)Visualization
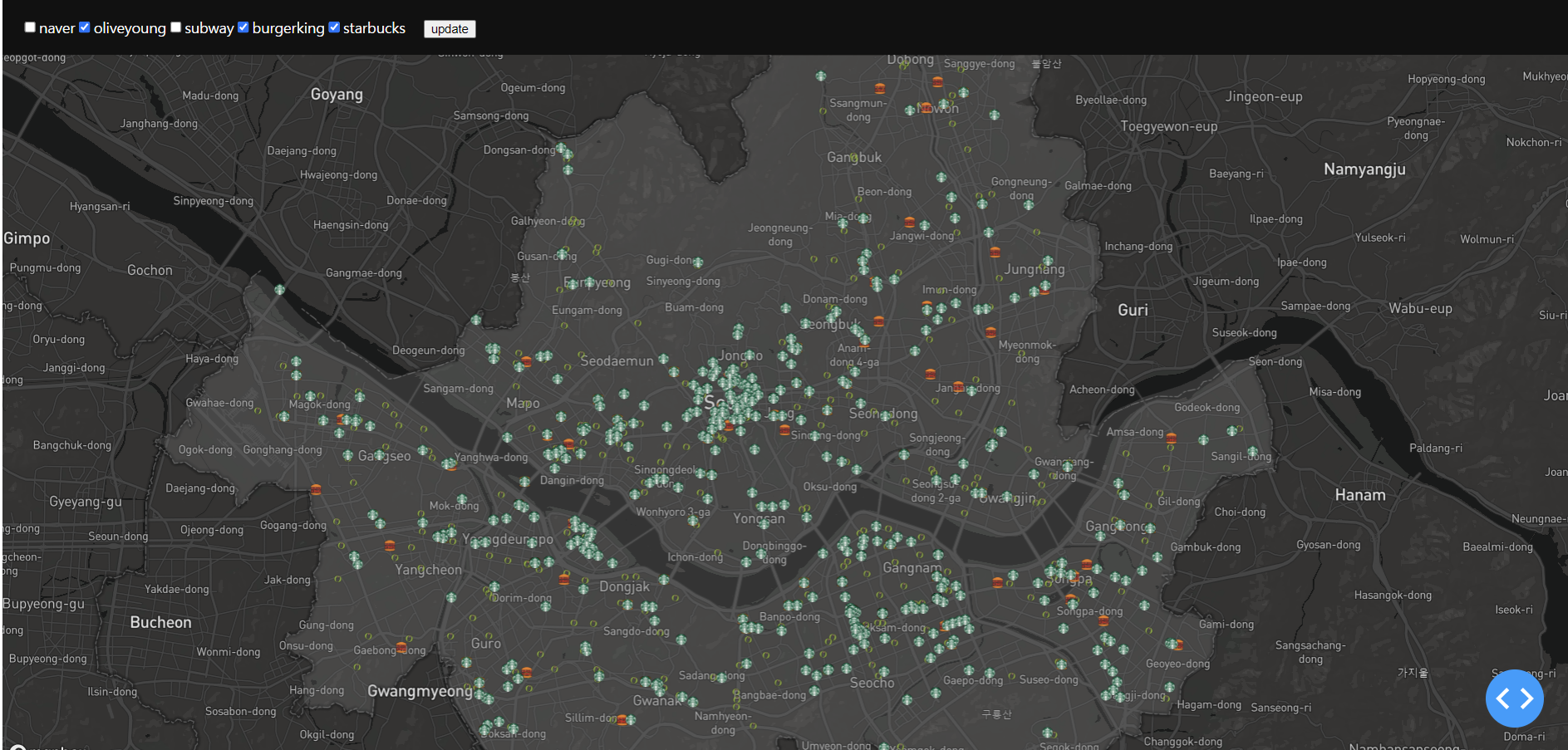
3대장(스타벅스, 올리브영, 버거킹)을 체크하고 update한 결과이다.
역시나 강남, 신촌, 홍대, 여의도가 강세를 보이고 다크호스 종로가 등장했다. 건대는 상대적으로 약세를 보인다.
스타벅스, 올리브영, 버거킹이 함께있는 지역이 핫플레이스 지역으로 불리기에 손색이 없어 보인다.
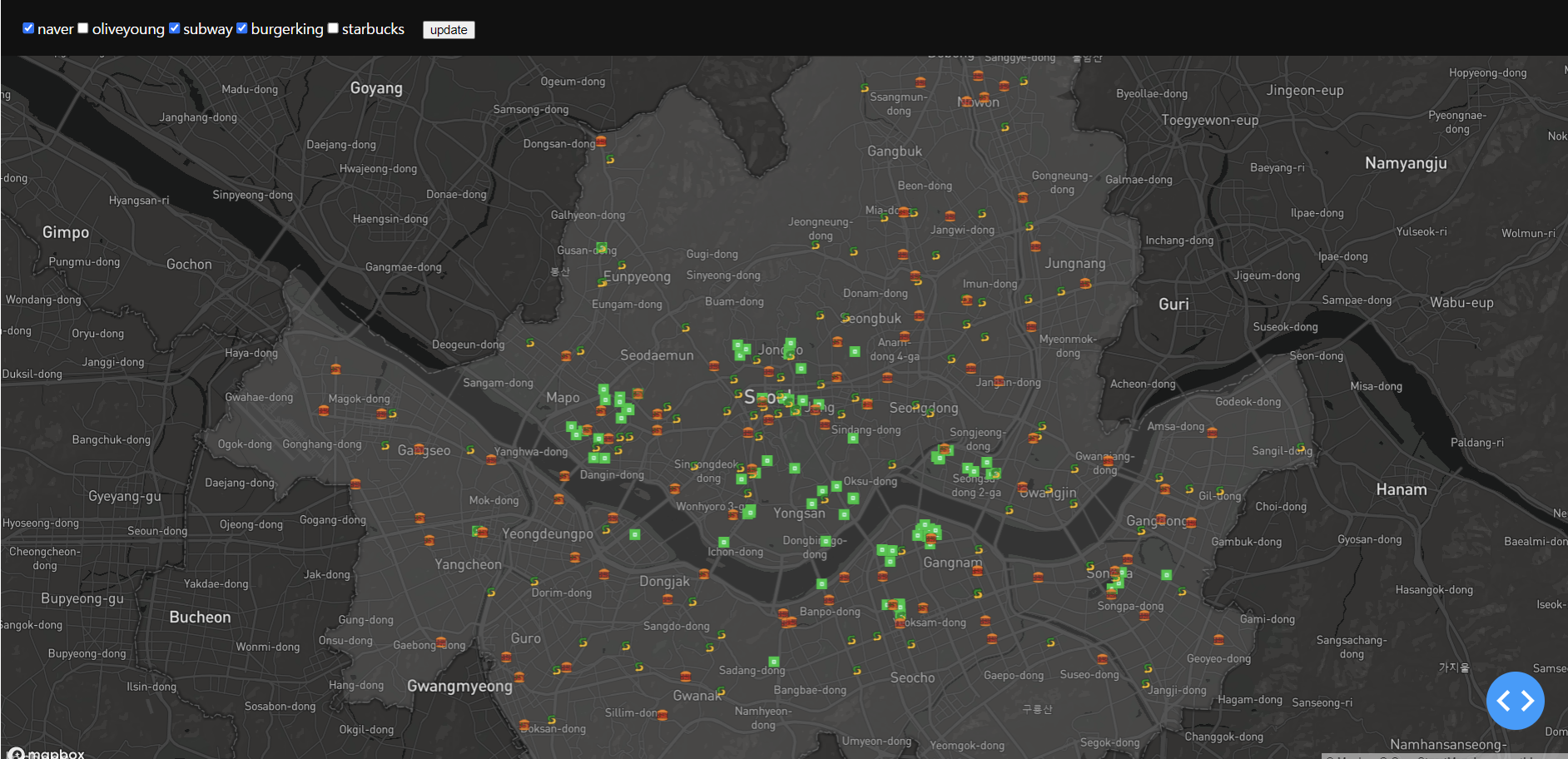
여기서 만약 올리브영과 스타벅스를 제거하고 naver top100과 서브웨이를 check하면 이런식으로 나오게 된다.
네이버 맛집이 추가되자 더 확실하게 구분되는 모습이 보인다.
4. 인스타그램 크롤링
인스타는 답을 알고있다…..
바야흐로 사진, 인증샷의 시대가 도래하였고 핫플레이스를 찾는다면 인스타그램을 이용할 수 밖에 없어졌다.
자신이 얼마나 맛있는 음식을 먹었는지, 얼마나 이쁜 카페에 왔는지, 얼마나 멋진 장소에서 시간을 보내는지 앞다투어 사진으로 찍어서 올린다.
그리고 함께 태그를 단다. 사진을 크롤링하여 분석하기엔 무리가 있으니 게시물과 함께 올라온 글과 태그를 크롤링하여 그려보고자 한다.
from konlpy.tag import Okt
import numpy as np
import pandas as pd
import os
import pickle
import itertools
import re
from collections import Counter
import matplotlib.pyplot as plt
from tqdm import tqdm
import bar_chart_race as bcr
from wordcloud import WordCloud
from PIL import Image
os.chdir(r'C:\Users\itsme\Desktop\seoul-viz')Crawled Data BarChartRace
1) Preprocessing
게시글 내용을 크롤링한 데이터를 활용하여 Bar Chart Race를 그려보았다.
여기서 Bar Chart Race란 시계열 index를 가진 데이터에서 시간이 지날수록 feature가 어떻게 변화하는지를 움직이는 막대그래프로 보여주는 라이브러리이다.
이를 그리기 위해선 하나의 데이터프레임으로 그려야하므로 팀원이 한땀한땀 크롤링한 데이터를 가져와 하나의 main_df로 합쳐주었다.
크롤링한 원천 데이터는 다음과 같이 생겼다. 크롤링 기간은 22년 7월 9일부터 8월 26일 까지이다.
| location_info | location_href | date_time | daste_title | main_text | |
|---|---|---|---|---|---|
| 0 | 25분 전 | 2022-07-13T13:47:40.000Z | 7월 13, 2022 | 수강생분의 라이언 플레이트 #강남도자기공방#동화담#서울원데이클래스#서울데이트#강남공방#공방원데이클래스#도자기만들기#커플데이트#커플스타그램 #컵만들기#접시만들기#도자기공예#물레체험#공방체험#서울가볼만한곳#양재천 | |
| 1 | 10시간 전 | 2022-07-13T03:22:36.000Z | 7월 13, 2022 | 음식들이 너무너무 정성스럽다..#미도인 #종각맛집#광화문스테이크#종로맛집#종로맛집미도인#종로고깃집#종각고깃집#인사동맛집#인사동고깃집#JMT#서울데이트 |
### 1. extracted_main data
## 1) 데이터 로드 및 합치기
lst = os.listdir('./main')
path = './main/'
main_df = pd.DataFrame(columns = ['daste_title', 'main_text'])
for i in lst:
dat = pd.read_csv(path + i, index_col=0).drop(['location_info', 'location_href', 'date_time'], axis=1)
main_df = pd.concat([main_df, dat])
main_df = main_df.dropna().reset_index(drop=True)
main_df.columns = ['time', 'text']
## 2) time column 정리
def time_format(text):
a = re.sub(",", "", text).split()
if len(a[1]) == 1:
res = a[0] + ' 0' + a[1] + '일'
else:
res = a[0] + ' ' + a[1] + '일'
return res
main_df['time'] = [time_format(i) for i in main_df['time']]
main_df['idx'] = pd.to_datetime(main_df['time'], format = "%m월 %d일")
main_df = main_df.sort_values('idx').drop('idx', axis=1).reset_index(drop=True)2) Text Preprocessing
konlpy의 okt 형태소분석기를 활용하여 텍스트 전처리를 진행하였다. 불용어를 제거하고 한글, 공백을 제외한 모든 문자를 제거해주었다.
인스타 게시글엔 상당히 많은 이모지나 특수문자가 많았기 때문이다.(이런 비언어적인(?) 표현들이 중요한 비중을 차지할 가능성이 있지만 지금 당장은 무시해준다.)
데이터가 거의 없는 기간은 제외하고 빈 리스트 또한 제거해주었다.
## 3) text 전처리
okt = Okt()
stop_words = pd.read_table(r'./Korean_stopwords.txt',sep='\n', names=['text'])
stop_word = stop_words.values
# 명사 추출 및 정제
def preprocessing(text, okt, remove_stopwords=False, stop_words=[]):
text_text = re.sub("[^가-힣ㄱ-ㅎㅏ-ㅣ\\s]", "", text) # 한글, 공백 제외 문자 모두 제거
word_text = okt.nouns(text_text) # okt 객체 활용, 명사 단위로 나누기
if remove_stopwords == True:
word_texts = [token for token in word_text if not token in stop_words]
return word_texts
clean_df = []
for text in tqdm(main_df['text']):
clean_df.append(preprocessing(text, okt, remove_stopwords=True,stop_words=stop_word))
main_df['clean_text'] = clean_df
# 기타 처리
main_df['a'] = " "
for i in range(len(main_df['clean_text'])):
if main_df.loc[i, 'clean_text'] == []:
main_df.loc[i, 'a'] = 1
index = main_df[main_df['a'] == 1].index
main_df.drop(index, inplace=True) # 빈 리스트 제거
main_df.drop(['a', 'text'], axis=1, inplace=True)
main_df = main_df.iloc[77:5713, :] # 데이터 부족한 날짜 제거 (7월 8일 ~ 8월 26일로 고정)
main_df.reset_index(drop=True, inplace=True)| time | clean_text | |
|---|---|---|
| 0 | 7월 08일 | ['피드', '결혼기념일', '맞이', '우주', '파파', '우주', '얼집', '행복', '구경', '우주', '얼집', '하원', '외출', '우주', '부부', '그날', '하루', '종일', '결기', '일이', '연차', '어제', '오빠', '코로나', '확진', '우주'] |
| 1 | 7월 08일 | ['광고', '오픈', '매장', '층', '럭셔리', '브랜드', '향수', '존', '백화점', '보지', '못', '향수','향', '부담', '럭셔리', '브랜드', '제품', '체험', '공간', '층', '컬러', '스튜디오', '네일', '퍼스','널', '진단', '통해', '메이크업', '헤어', '컨설팅', '네일케어', '맞춤', '특화된', '공간', '지하', '마켓', '포토', '존', '최대', '할인', '제품', '가성', '비', '비', '층', '안쪽', '핑크', '부스', '포토', '존', '꼭', '공간', '만', '뷰티', '제품', '가득', '강남', '강남', '역점', '핫', '강남', '핫', '뷰티', '뷰티'] |
| 2 | 7월 08일 | ['전시', '예술', '문화', '페이스', '갤러리', '시작', '세계', '정상', '갤러리', '진출', '불과', '해도', '아시아', '갤러리', '진출', '시장', '홍콩', '상하이', '그다음', '도쿄', '거론', '뿐', '이제', '아시아', '핵심', '아트', '마켓', '팬데믹', '상황', '폭발', '성장', '글로벌', '갤러리', '관심', '집중', '국내', '전문가', '일순간', '상황', '안정', '상황', '대중', '공공', '미술관', '균형', '원로', '작가', '신진', '작가', '예술', '관심', '대중', '존재', '마켓', '형성', '규모', '면', '타', '도시', '비교', '마켓', '사이즈', '지속', '긍정', '예술', '인프라', '차곡차곡', '우리나라', '예술', '문화', '예정', '오늘', 꼭', '갤러리', '한남동', '위치', '볼', '하루', '핫', '전시', '전시회', '갤러리', '한남동', '전시', '한남동', '갤러리', '미술관', '리움', '미술관', '우스', '파운드리', '리만', '머핀', '갤러리', '박', '부스','갤러리', '카드', '스토리', '페이스', '갤러리', '오드', '삼삼'] |
3) Count & Accumulate
본격적으로 race 그래프를 그리기 위해 데이터를 정리해준다.
- 같은 날짜가 나뉘어져 있는 경우들이 많으므로 날짜별로 list 형태로 키워드들을 합쳐준다. - itertools를 활용하여 각 리스트의 원소들을 그대로 가져와서 붙인다.
- 전체 단어(각 날짜당 갯수 top50)을 자체 컬럼으로 만들어 시간이 갈수록 몇개가 있는지를 누적합을 구해준다. - Counter 함수를 이용하여 세준다.
## 4) bar chart race를 위한 데이터 구축
# 날짜 별 키워드 합치기
main_df = main_df.groupby('time')['clean_text'].apply(list).reset_index()
for i in range(len(main_df)):
val = list(itertools.chain.from_iterable(main_df.at[i, 'clean_text']))
main_df.at[i, 'clean_text'] = val
# counted 데이터 생성
for i in range(len(main_df)):
a = Counter(main_df.loc[i, 'clean_text']).most_common(50)
for j in a:
main_df.loc[i, '{}'.format(j[0])] = j[1]
main_df.drop('clean_text', axis=1, inplace=True)
main_df = main_df.fillna(0)
main_df.iloc[:, 1:] = main_df.iloc[:, 1:].cumsum()
main_df.set_index('time', inplace=True)최종적으로 정리된 main_df는 다음과 같다.
상대적으로 빈도수가 높았던 단어 905개의 갯수를 날짜가 지남에 따라 누적합을 구한 데이터이다.
| time | 갤러리 | 전시 | 예술 | 마켓 | 핫 | 신촌 | 상황 | 미술관 | 한남동 |
|---|---|---|---|---|---|---|---|---|---|
| 7월 08일 | 21 | 10 | 8 | 7 | 7 | 7 | 6 | 6 | 6 |
| 7월 09일 | 21 | 19 | 8 | 7 | 112 | 18 | 6 | 6 | 6 |
| 7월 10일 | 21 | 19 | 8 | 7 | 233 | 18 | 6 | 6 | 6 |
| 7월 11일 | 21 | 23 | 8 | 7 | 233 | 18 | 6 | 6 | 6 |
| 7월 12일 | 21 | 35 | 8 | 7 | 313 | 18 | 6 | 6 | 6 |
| 7월 13일 | 21 | 67 | 8 | 7 | 367 | 18 | 6 | 6 | 6 |
| 7월 14일 | 21 | 67 | 8 | 7 | 401 | 62 | 6 | 6 | 6 |
| 7월 15일 | 21 | 67 | 8 | 7 | 401 | 62 | 6 | 6 | 6 |
| 7월 16일 | 21 | 67 | 8 | 7 | 401 | 62 | 6 | 6 | 6 |
| 7월 17일 | 21 | 67 | 8 | 7 | 401 | 62 | 6 | 6 | 6 |
| 7월 18일 | 21 | 100 | 8 | 7 | 448 | 62 | 6 | 6 | 6 |
(50 rows X 905 columns)
4) Visualization
bar_chart_race 함수로 그래프를 그린다. mp4 형태로 output을 저장할 수 있다.
가장 많이 등장한 상위 10개 단어의 race를 그려보았다.
## 5) 그래프 그리기
plt.figure(figsize=(24, 16), dpi=1000)
fig, ax = plt.subplots(nrows=1, ncols=1)
fig.patch.set_facecolor('black')
ax.set_facecolor('black')
ax.set_title('Instagram Hottest Keywords (07/08 ~ 08/26)', fontsize=15, color= 'white', fontweight='bold')
bcr.bar_chart_race(df = main_df,
filename = "./insta_race.mp4",
orientation='h',
n_bars = 10,
fixed_max=True,
steps_per_period=60,
perpendicular_bar_func='median',
period_length=200,
period_label={'x': .98, 'y': .3, 'ha': 'right', 'va': 'center'},
shared_fontdict={'family' : 'NanumGothic', 'color' : 'white', 'weight' : 'bold', 'size' : 10},
bar_size=.9,
scale='linear',
bar_kwargs={'alpha': .7},
figsize=(12,8),
filter_column_colors=True,
fig=fig,
sort='desc')함수인자들에 특이사항은 없지만 몇 가지 특이사항을 첨언하자면,
- n_bars = 10 : 상위 10개의 단어를 보여준다.
- steps_per_period : 숫자가 클수록 부드럽다.
- period_length : 차트 증가 속도
- shared_fontdic : 전체적인 폰트 스타일 설정, 나눔 고딕의 경우 matplotlib이 베이스라 폰트 설치를 해줘야 한글이 보인다!
그려진 bar chart race는 다음과 같다.
영어 폰트의 경우 이정도로 화질구지가 되지 않는데 한글 구현의 한계 때문인지 아무리 figure의 dpi를 높여도 글자가 깨지는건 어쩔수가 없었다.
역시나 ‘카페’가 1등을 차지하였다. 차례대로 핫, 맛, 사진, 코스, 여행, 고기, 메뉴, 술집, 길 단어가 상위 10개 단어로 나타났다.
핫플레이스가 어디인지 확인하기에 적합한 방법은 아니지만 사람들이 어떤 키워드를 가지고 핫플레이스나 글에 대한 정보를 올리는지 간접적으로 알 수 있었다.
Tag Data WordCloud
이번엔 해시태그를 크롤링한 데이터로 wordcloud를 그려보도록 하자.
1) Data Load & Preprocessing
팀원이 같이 크롤링한 날짜별 태그 데이터를 하나로 모아서 합쳐준다.
## 1) 데이터 로드
lst = os.listdir('./tag')
path = './tag/'
okt = Okt()
stop_words = pd.read_table(r'./Korean_stopwords.txt',sep='\n', names=['text'])
stop_word = stop_words.values
tag_df = pd.DataFrame(columns = ['tag'])
for i in lst:
dat = pd.read_csv(path + i, index_col=0)
tag_df = pd.concat([tag_df, dat])
tag_df = tag_df.dropna().reset_index(drop=True)
## 2) 전처리
def listToString(str_list):
result = ""
for s in str_list:
result += s + " "
return result.strip()
seoul_mask = np.array(Image.open(r'.\seoul.png'))
clean_tag = listToString(tag_df['tag'])
clean_tag = re.sub("[^가-힣ㄱ-ㅎㅏ-ㅣ\\s]", "", clean_tag)
clean_tag = okt.nouns(clean_tag)
clean_tag = listToString(clean_tag)이전과 다른 점은 날짜별로 구분하지 않고 모든 태그 데이터를 하나로 모아서 하나의 str 객체로 만든 것이다.
또한 그냥 네모 모양으로 그리면 재미가 없으니 서울시 지도모양을 가져와 맞춰서 그려보았다.
태그 데이터 역시 불용어 및 한글 제외 제거하고 명사만 추출하여 진행하였다.
2) Visualization
WordCloud 함수로 그려준다. 편하게도 불용어와 배경모양을 설정해주는 인자가 존재하여 이용하였다.
## 3) wordcloud 그리기
wordcloud = WordCloud(font_path=r".\NanumGothic.ttf",
background_color='black',
max_font_size=200,
relative_scaling = 0.2,
stopwords=set(stop_words['text']),
mask=seoul_mask).generate(str(clean_tag))
plt.figure(figsize=(64, 36), dpi=600)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()최종적으로 그려진 WordCloud이다.

여기서도 또다시 등장한 카페, 코스, 술집 등이 보인다. 이전 데이터보단 핫플레이스라는 키워드에 좀 더 근접해보인다.
종로, 홍대, 신촌, 강남, 연남동, 인사동, 이태원 등 전통적인 핫플레이스 강자(?)가 많이 포진되어 있음을 알 수 있다.
5. Conclusion
제가 맡은 파트는 여기까지랍니다
서울시의 핫플레이스를 데이터로 확인해보고자 하는 대장정이 막을 내렸다.
우리가 흔히 알던 핫한 지역 - 강남, 신촌, 홍대, 건대 등 - 이 데이터로도 핫플임을 보여줄 수 있는가가 프로젝트의 주된 목적이였다.
- 유동인구 데이터는 사람들이 주로 어디로 이동하고 모이는지 를 보여주었다.
- 가게 데이터는 특정 가게들이 밀접되어 있는 곳이 핫플인지 를 보여주었다.
- 인스타그램 데이터는 사람들이 어떤 것에 관심이 있고 어디를 가는지 를 보여주었다.
😆 유동인구, 가게, 인스타그램 데이터를 통해 확인해본 결과 이런 지역들이 데이터에서도 핫플로 나타남을 확인할 수 있었다.
마무리가 된 시점에서 돌아보면 작성한 코드의 길이가 들인 시간에 비해 그리 길진 않지만 완성하기까지 수많은 오류와 시행착오가 있었다.
단순히 지도에 원하는 데이터를 띄우는 것만으로도 애를 먹었고, 또 그것을 dash와 같은 다른 라이브러리와 연동시키는 부분에서 한참 헤맸다.
몇 시간을 헤메다가 겨우 찾은 해답이 겨우 한 두줄 바꾸는 것일땐 허탈했던 기억도 많았다.(물론 늘 그런 것 같다..)
하지만 노력 끝에 원하던 그림이 나오는 순간의 기쁨은 언제 느끼든 기분 좋은 감정이다!
이렇게 말하니 뭔가 대단한 걸 한 것 같지만 전혀 아니다.
Next?
사실 아직 끝난게 아니다!
지금까지 한 모든 일련의 작업들은 서울시의 핫플을 소개하는 우리만의 사이트에 들어갈 콘텐츠를 만든 작업이였다.
이 다음 작업은 Heroku라는 사이트를 통해 dashboard를 배포하고 이를 html 형태로 사이트에 올리는 것이다.
- 2023.01.31, 안타깝게도 Heroku의 무료 서비스가 2022.11부로 종료되어 마무리하지 못하게 되었다 ㅠㅠ 파이썬 Django를 활용해봐야겠다.
References
