개요
부캠 첫 대회인 STS 대회가 끝나고 1주일 정도 product serving 강의를 들었다. 변성윤(통칭 카일) 마스터님의 강의는 항상 느끼는데 정말 알차고 좋은 것 같다.
사실 부캠에 참여하게된 주된 이유가 내가 만든 모델을 배포하고 관리하는 ML engineering과 mlops에 대한 제대로된 공부를 하고 싶어서인데 딱 그 내용이 등장했다!
그리고 마침 대회 모델을 streamlit을 이용해서 웹에 띄워보라는 과제가 있어서 생애 첫 모델 서빙을 해봤다. 다 구현하고 나서 느끼는 거지만, 오류가 참 많았고 streamlit은 정말 편하다.

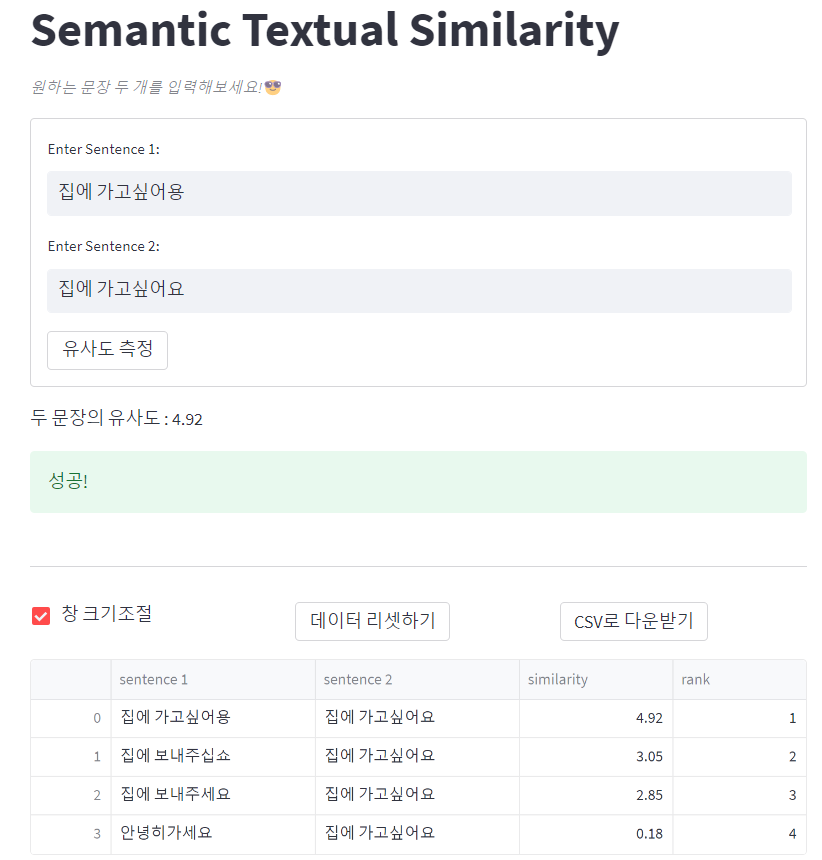
완성된 결과물은 다음과 같다.
체험해보기 : 문장 유사도 측정기

코드 구성
기존 프로젝트 repo에 streamlit_folder를 추가해서 predict.py, config.yaml을 추가하고 바로 바깥에 app.py를 추가해서 만들었다.
1) config.yaml
model_path: https://drive.google.com/uc?id=[your_model_path_id]
model_name: snunlp/KR-ELECTRA-discriminatorconfig 파일엔 학습이 완료된 모델의 경로와 이름을 지정해준다. 모델을 streamlit cloud로 배포까지 하기 위해 모델을 구글 드라이브에 업로드한 후 gdown 라이브러리를 통해 model을 가져오는 방식을 취했다. 이때문에 기본 구조에 있던 model.py 파일이 필요 없어졌다.
구글 드라이브에 업로드한 후 오른쪽 클릭을 해 공유하기를 눌러 링크를 복사해오면
https://drive.google.com/file/d/[your_model_path_id]/view?usp=sharing이렇게 뜨는데 [your_model_path_id]를 복사해서 위 config.yaml에 적절히 바꿔끼면 된다.
model_name은 Tokenizer를 불러올 때 사용한다.
2) predict.py
import os
import gdown
import torch
import streamlit as st
import yaml
from transformers import AutoTokenizer
import sys
from models import *
with open("streamlit_folder/config.yaml") as f:
config = yaml.load(f, Loader=yaml.FullLoader)
# 구글 드라이브를 이용한 모델 다운로드
def download_model_file(url):
output = "model.pt"
gdown.download(url, output, quiet=False)
@st.cache_resource
def load_model():
'''
Return:
model: 구글 드라이브에서 가져온 모델 return
'''
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if not os.path.exists("model.pt"):
download_model_file(config['model_path'])
model_path = 'model.pt'
model = torch.load(model_path, map_location=device)
return model
def get_prediction(model, sentence1: str, sentence2: str) -> float:
'''
Args:
model: 학습된 모델
sentence1: 유사도 측정 문장 1
sentence2: 유사도 측정 문장 2
Return:
유사도 측정값
'''
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(config['model_name'])
inputs = tokenizer(sentence1, sentence2, return_tensors="pt",
max_length=160, padding='max_length', truncation=True)['input_ids'].to(device)
outputs = model(inputs)
scalar_value = outputs.detach().cpu().item()
return min(5., max(0., round(scalar_value,2)))
predict.py에선 load_model 함수와 get_prediction 함수 두 개를 정의한다.
load_model
구글 드라이브에서 다운로드한 모델의 경로가 없다면 다운로드하고 해당 model_path를 torch.load를 통해 불러온다.
이때, 원래 repo에 있던 model.py 함수, 즉 학습할 때 사용했던 모델의 모듈들을 불러와야 정상적으로 동작한다. 이를 위해 from models import *를 통해 기존 모듈들을 불러와주었다. 이 안엔 model.py와 gru_model.py가 들어있다.
streamlit의 매번 전체를 다시 시작하는 특성 상 계속 모델을 다운로드하고 불러오면 반응시간과 같은 여러 문제가 생긴다. @st.cache_resource 데코레이터를 사용해 캐싱해서 메모리에 저장하자.
get_prediction
불러온 모델로 예측을 해서 유사도 결과를 뱉는 함수이다. model과 두 문장 sentence1, sentence2를 받아와서 토크나이징 하고 모델의 output을 출력한다.
3) app.py
import streamlit as st
import pandas as pd
from streamlit_folder.predict import load_model, get_prediction
def main():
st.title('Semantic Textual Similarity')
st.caption('*원하는 문장 두 개를 입력해보세요!*:sunglasses:')
model = load_model()
model.eval()
# 측정 결과들 모아두는 df
if "df" not in st.session_state:
st.session_state.df = pd.DataFrame({
'sentence 1': [],
'sentence 2' : [],
'similarity' : []
})
with st.form(key='문장입력 form'):
sentence1 = st.text_input("Enter Sentence 1:")
sentence2 = st.text_input("Enter Sentence 2:")
form_submitted = st.form_submit_button('유사도 측정')
if form_submitted:
if sentence1 and sentence2:
similarity_score = get_prediction(model, sentence1, sentence2)
# df에 이미 있는 유사도 쌍이면 추가 안함
if not ((st.session_state.df['sentence 1'] == sentence1) & (st.session_state.df['sentence 2'] == sentence2)).any():
# 새로운 데이터를 기존 df에 합치기
new_data = pd.DataFrame({
'sentence 1': [sentence1],
'sentence 2': [sentence2],
'similarity': [similarity_score]
})
st.session_state.df = pd.concat([st.session_state.df, new_data])
# similarity 기준으로 순위 매기기
st.session_state.df = st.session_state.df.sort_values(by='similarity', ascending=False).reset_index(drop=True)
# rank 컬럼 추가
st.session_state.df['rank'] = st.session_state.df.index + 1
st.write(f"두 문장의 유사도 : {similarity_score}")
st.success('성공!')
else:
st.write("Please enter both sentences.")
st.error('다시 한번 생각해보세요!')
st.divider()
col1, col2, col3 = st.columns(3)
# df 크기 조절
col1.checkbox("창 크기조절", value=True, key="use_container_width")
# df 리셋 버튼
if col2.button("데이터 리셋하기"):
st.session_state.df = pd.DataFrame({
'sentence 1': [],
'sentence 2' : [],
'similarity' : []
})
# df csv로 다운로드
@st.cache_data
def convert_df(df):
return df.to_csv(index=False, header=True).encode('cp949')
csv = convert_df(st.session_state.df)
col3.download_button(
label="CSV로 다운받기",
data=csv,
file_name='sts_data_outputs.csv',
mime='text/csv',
)
st.dataframe(st.session_state.df, use_container_width=st.session_state.use_container_width)
main()
로컬 실행
streamlit이 실제로 실행하는 파일이다. 로컬에선 CLI에서 다음 명령어를 입력하면 된다.
streamlit run app.pystreamlit의 기본 포트번호는 8501이기 때문에 만약 remote SSH과 같은 서버환경에서 띄우고 싶다면 해당 서버의 포트번호를 알아내서(이번 경우 30001) 추가명령어를 붙이면 된다.
streamlit run app.py server.port 30001코드
st.form에서 두 문장을 입력받고 st.form_submit_button을 누르면 form_submitted가 저장된다. 두 문장 입력에 문제가 없다면 get_prediction 함수로 점수를 예측해서 similarity_score에 저장한다.
원래는 두 문장을 입력받아 유사도 점수만 출력하는 형태만 구현하려 했으나 여러 기능들을 건드리다보니 욕심이 생겨 몇 가지 기능을 추가했다.
유사도 측정 결과를 dataframe 형태로 계속 저장하고 유사도에 따라 실시간으로 순위를 매겨서 보여주었다. dataframe에 이미 있는 조합이면 저장하지 않는다.
st.checkbox로 창 크기 조절기능과 st.button로 데이터셋을 리셋하는 기능을 만들었다. st.download_button으로 CSV로 dataframe을 다운받는 기능도 추가했다. 코드 상에선 col1.~ col2.~의 형태로 보이는데 이는 세 개의 박스로 분리해서 보여주기 위해 사용한 기능으로 st와 차이가 없다.
st.session_state는 streamlit이 매번 갱신되는 특성 때문에 값들이 계속 리셋되어서 특정 변수들을 global 변수 처리해줄 필요가 있을 때 사용한다. 즉, 뭔가 작업을 하면 main() 함수가 통째로 실행되기에 model 불러오는 것부터 시작된다. 재실행되어 초기화되지 않게하기 위해 사용한다.
streamlit sharing 배포
배포는 매우 간단하다.
-
https://share.streamlit.io 에서 sign in 한 후 오른쪽 상단의 Settings를 클릭 해 'Sign in with Github'를 통해 계정을 연동한다.
-
New app 버튼을 눌러서 배포하고자 하는 Github repo를 연결한다.
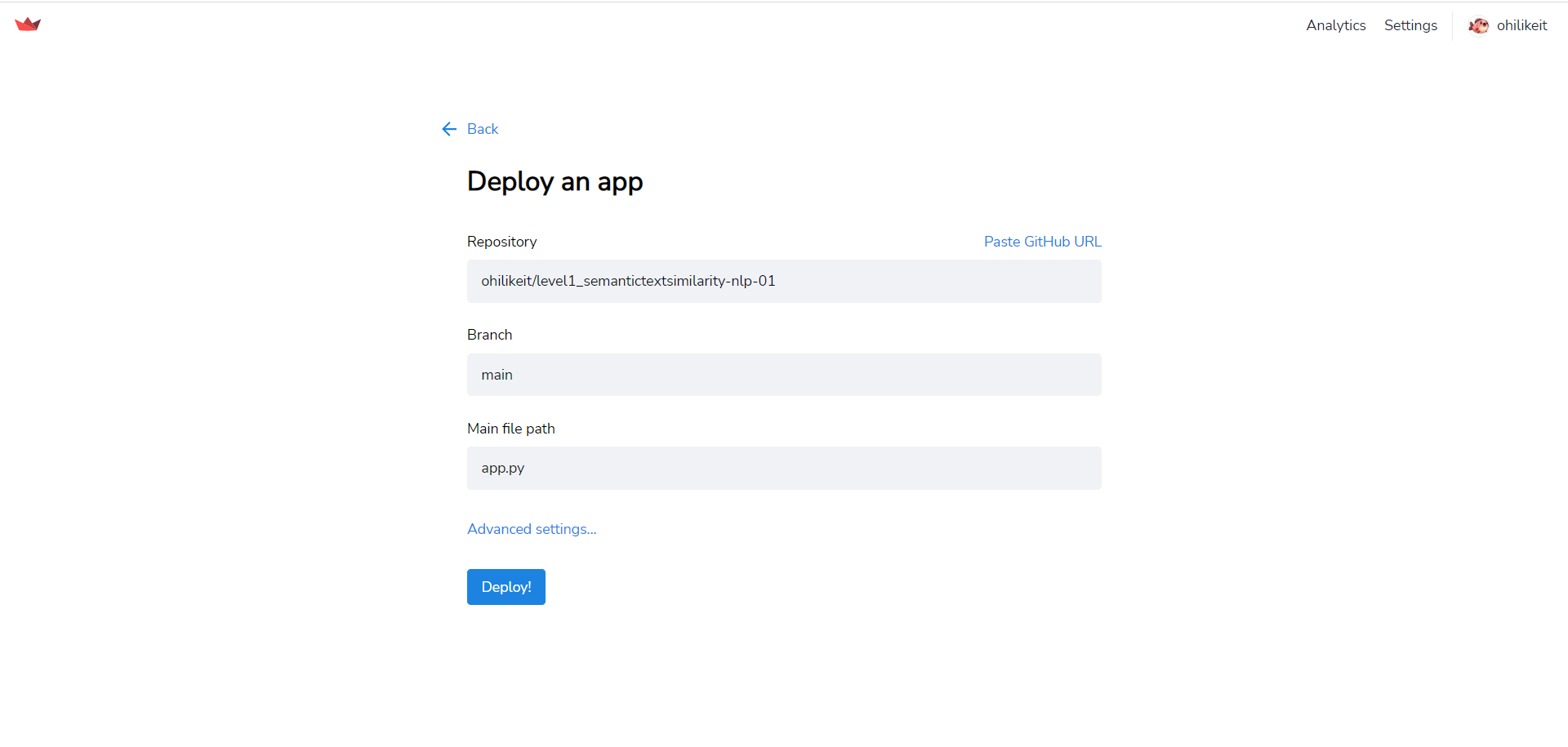
-
Deploy 버튼을 누르면 알아서 해준다. 이때 발생하는 오류는 다양하므로 오른쪽에 뜨는 에러 메세지들이 다양하므로 디버깅 해가면서 해결해야한다. 나의 경우 앞서 말했던 model load를 위해 필요한 model.py를 감지하지 못했던 오류가 있었고
from models import *로 해결했다. -
수정이 필요하면 처음 설정한 branch에서 수정하고 원격 저장소로 push만 해주면 된다.
결론
이렇게 간단하게 Streamlit Sharing 플랫폼으로 웹 어플리케이션을 배포해봤다. 예전엔 이런 웹들에 어떻게 ML 모델들을 올려놓은건지 마냥 신기했는데 직접 해보니 여전히 신기하다. 😁
만들면서 느낀 것이 미리 모델 틀을 만들어놓고 모델 학습결과를 눈으로 확인할 때 활용하면 좋았을 것 같다는 생각이 들었다. 로컬 환경이 cuda가 깔리지 않아 cpu inference를 했음에도 속도가 거의 차이가 없었으니 빠르게 확인이 가능하지 않을까 싶다.
Streamlit은 정말 웹 프론트엔드에 대한 지식이 전무해도 사용 가능한 것 같다. 이제 간단하게 모델 데모버전을 만들때 계속 사용할 것 같다. 다음 모델은 객체 관계추출 task라 이번처럼 간단하진 않겠지만 또 만들어볼 예정이다.
Reference
Introducing Streamlit Sharing
[KR] Streamlit 앱 정말 쉽게 배포하기 (ft. Streamlit Sharing)
Streamlit.io
