아키텍처
Node Express ↔ Spring 간 비대칭 키 기반 JWT 인증 도입
Admin(프론트) <-> Admin(백엔드) <-> Spring간 통신을 채택했다. 아직 Node Express를 Spring 프레임워크 만큼 잘 다루지는 못해 핵심 로직들을 Spring 에서 구현하고, 이를 Admin 노드 서버에서 요청하는 방식으로 설계했다.
Node ↔ Spring간 인증의 필요성
따라서 Node.js와 Spring 서버는 서로 신뢰할 수 있는 상대인지 검증하는 인증 절차가 필요했습니다. 처음에는 가장 흔한 로그인 방식의 JWT 발급이 떠올랐지만, 이 방식은 아래와 같은 이유로 적합하지 않음을 금방 알 수 있었습니다.
- 기존에 로그인에 흔히 사용하던 방식인 Node.js가 Spring 서버에 로그인을 요청하고 AccessToken을 발급받는 구조는 불필요함. 또한 대칭키 방식이기때문에 신뢰하기 어려움.
- 서버 간 통신에서 로그인 기반 토큰 관리는 효율적이지 않음.
이에 상사분께 조언을 구하여 비대칭 키 알고리즘(RS256)을 활용한 JWT를 도입하게 되었습니다.
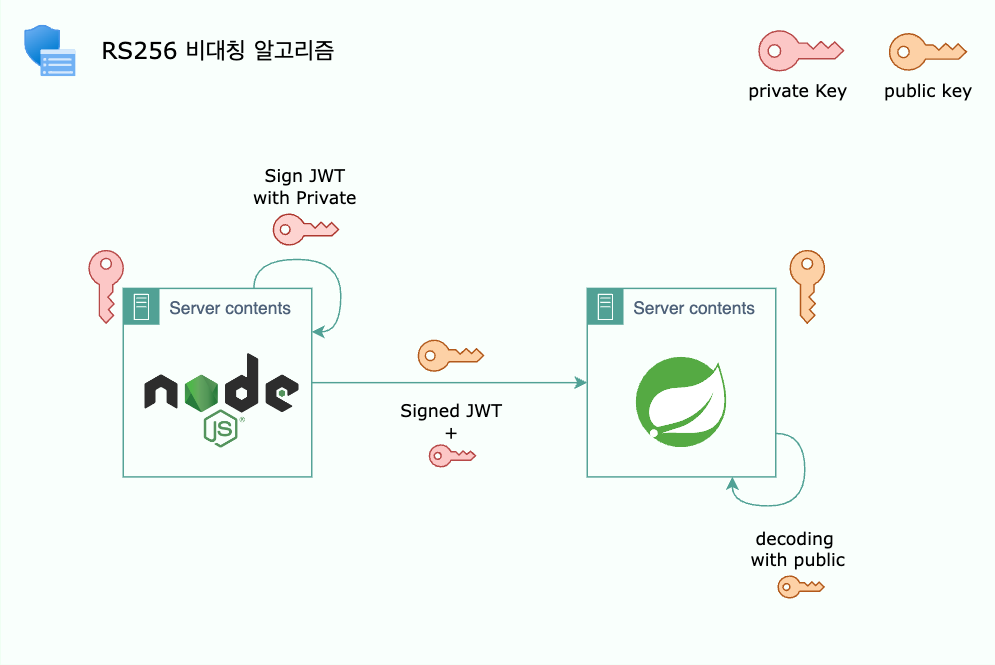
비대칭 키 기반 JWT 인증 설계
RS256
RS256은 비대칭 키를 기반으로 하여, 한 쪽에서 생성된 JWT가 다른 쪽에서 검증될 수 있도록 설계된 안전한 알고리즘입니다.
키 생성
Node.js 서버에서 OpenSSL을 사용하여 RSA 키 쌍(비공개키, 공개키)을 생성했습니다.
- 비공개키 생성 - RSA 알고리즘
openssl genpkey -algorithm RSA -out keys/private.key -pkeyopt rsa_keygen_bits:2048- 공개키 추출
openssl rsa -pubout -in keys/private.key -out keys/public.key사내에 인증서버가 따로 없어 비공개키는 Node 서버에서만 알고 있는 환경변수로, 공개키는 Spring 서버에 환경변수로 관리했습니다.
이를 통해 Node에서는 요청에 RS256 비대칭키 알고리즘으로 JWT를 생성하여 헤더에 담아 보내고, Spring 서버는 관리하고 있는 공개키를 통해 검증하도록 하여 양쪽 서버가 신뢰할 수 있는 통신이 가능하도록 검증 절차를 거쳤습니다.
만약 인증 서버가 있었다면 다음과 같은 방식으로 중앙화된 관리가 가능했을 것 같습니다.
- 비공개키와 공개키를 인증 서버에서 관리
- 인증서버에서 JWT 발급
- 공개키 동적 관리
-> Spring 서버는 인증 서버에서 정기적으로 공개키를 가져오거나, JWKS(JSON Web Key Set)형식으로 제공되는 키를 캐싱하여 사용
시스템 설계 다이어그램
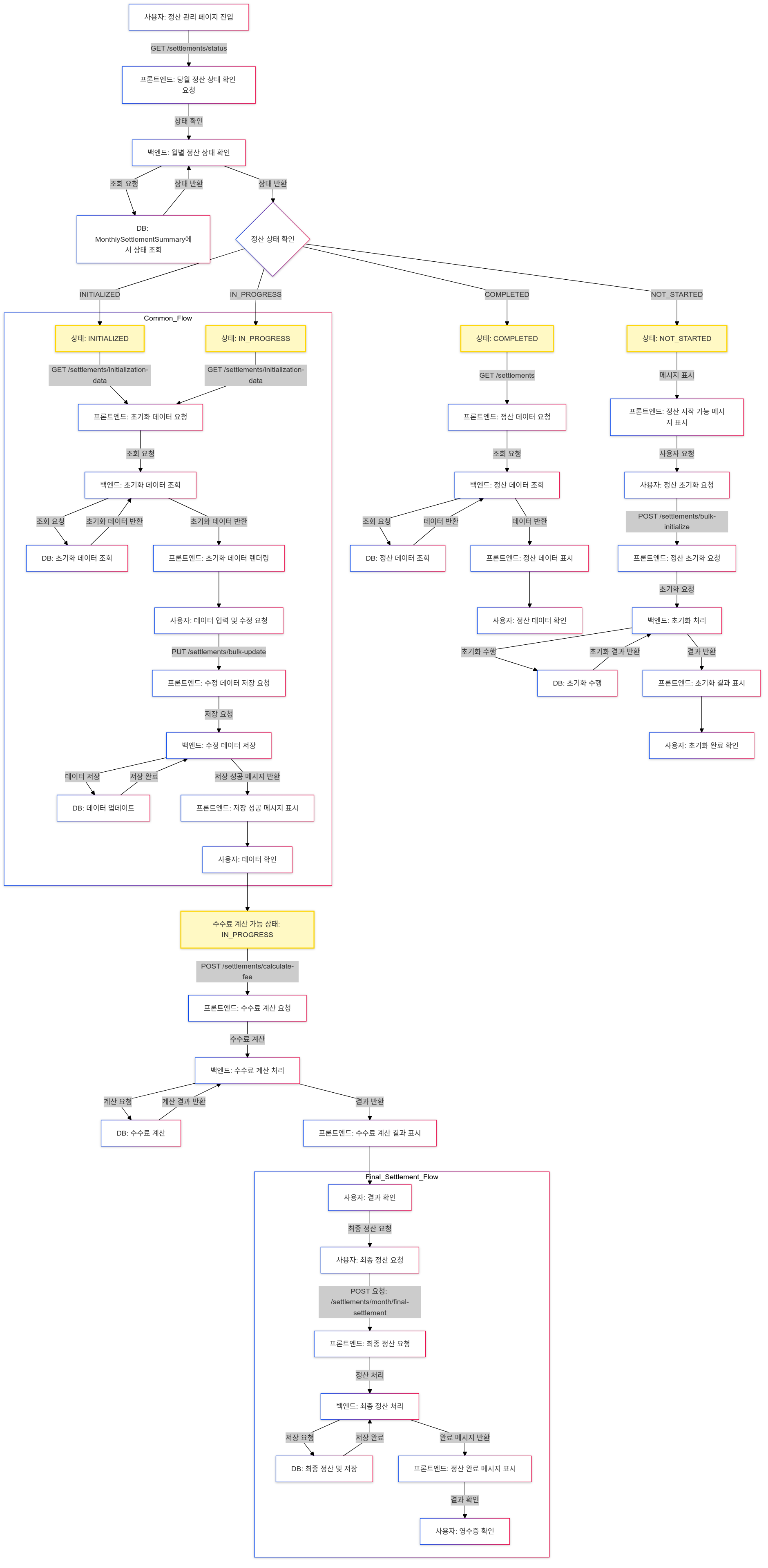
정산 관리 프로세스에서 상태 변화에 따른 데이터 흐름을 나타낸 다이어그램은 아래와 같습니다.
전체적인 정산 프로세스의 처음부터 끝까지
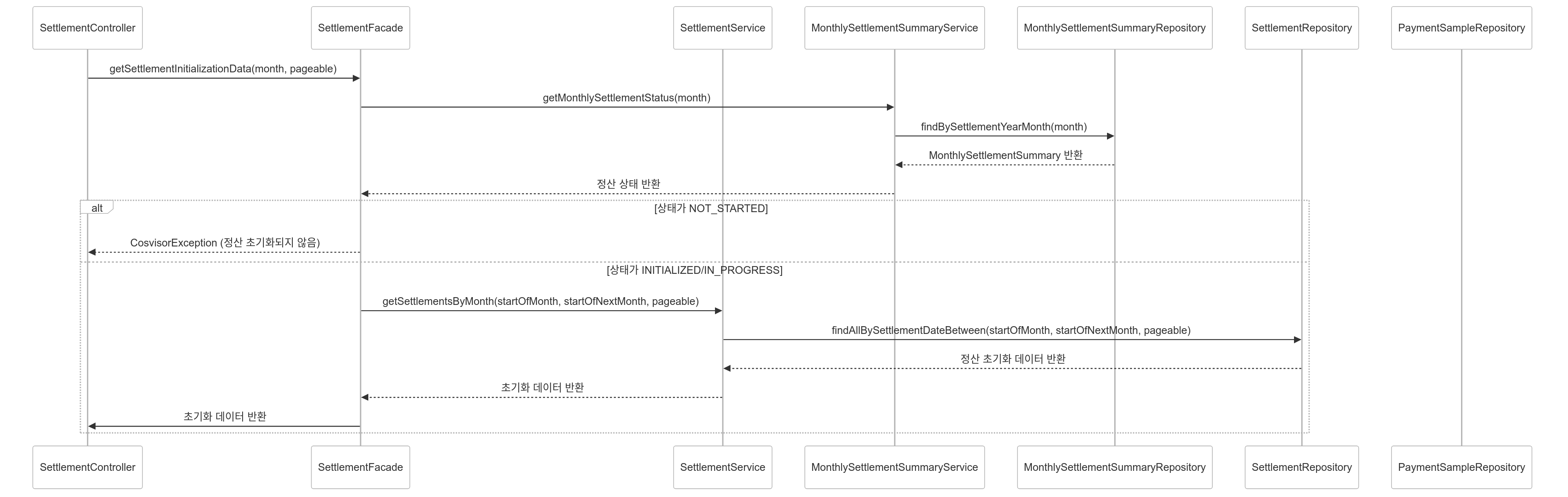
API 시퀀스 다이어그램
1. 당월 정산 상태 확인
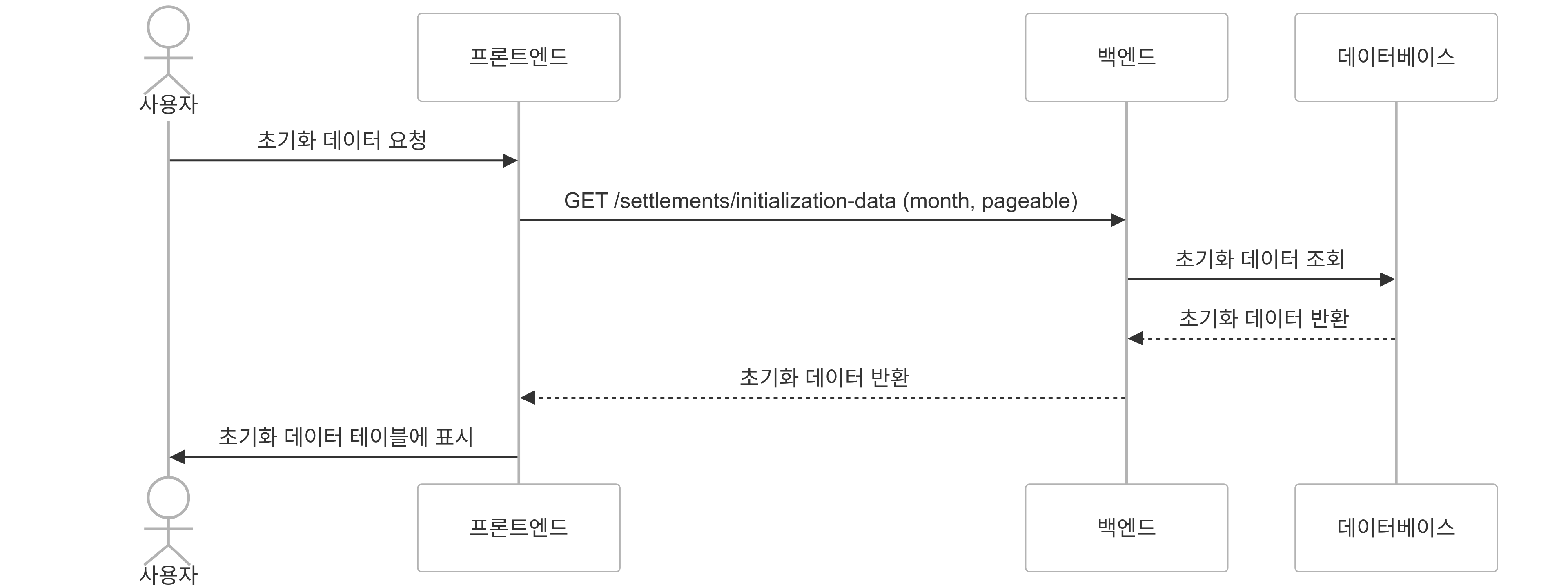
2. 스케줄링 / 수동 정산 데이터 초기화
정산을 위한 데이터 초기화
정산 초기화는 스케줄링을 통한 자동화, 수동화로 구분되어 있습니다.
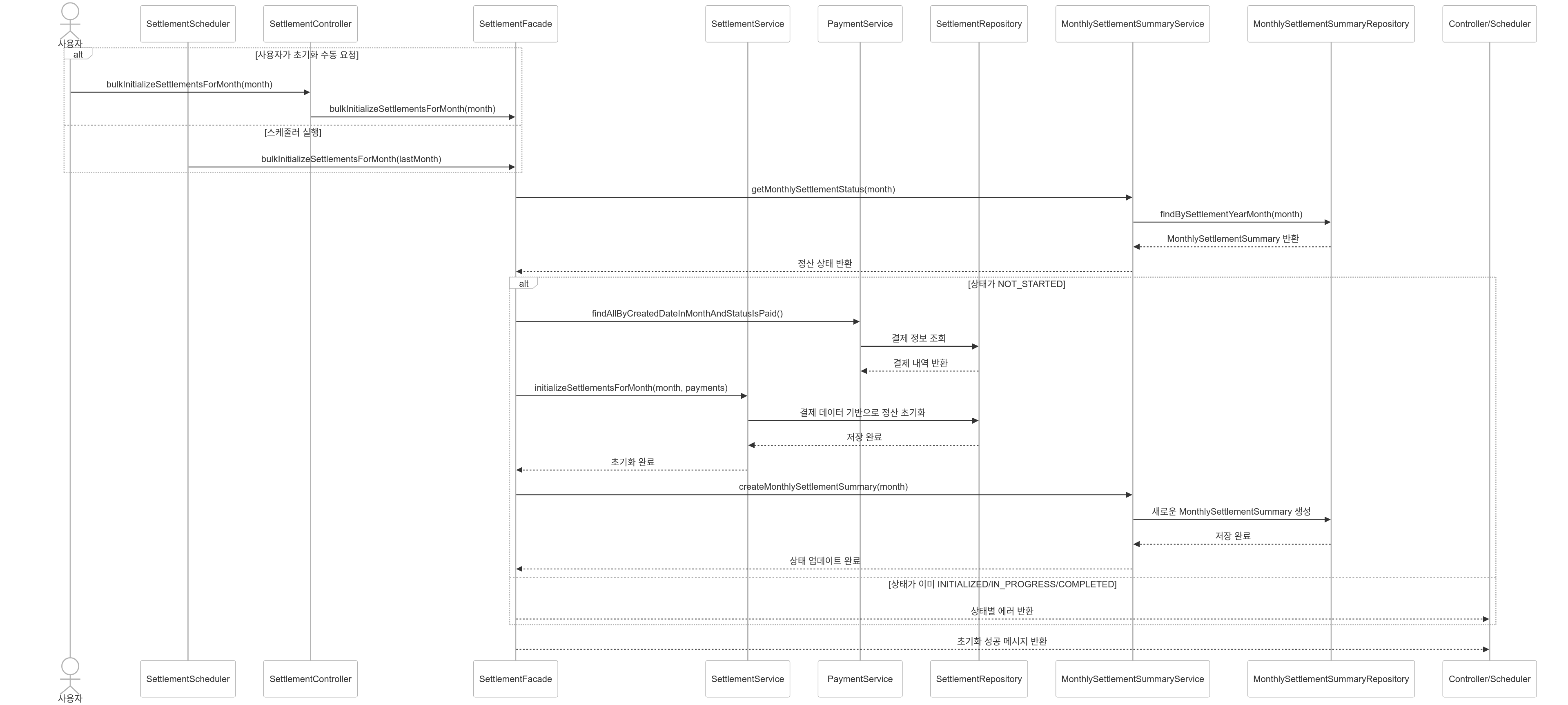
만약 수동으로 초기화를 해야할 경우 프로세스는 아래와 같습니다.
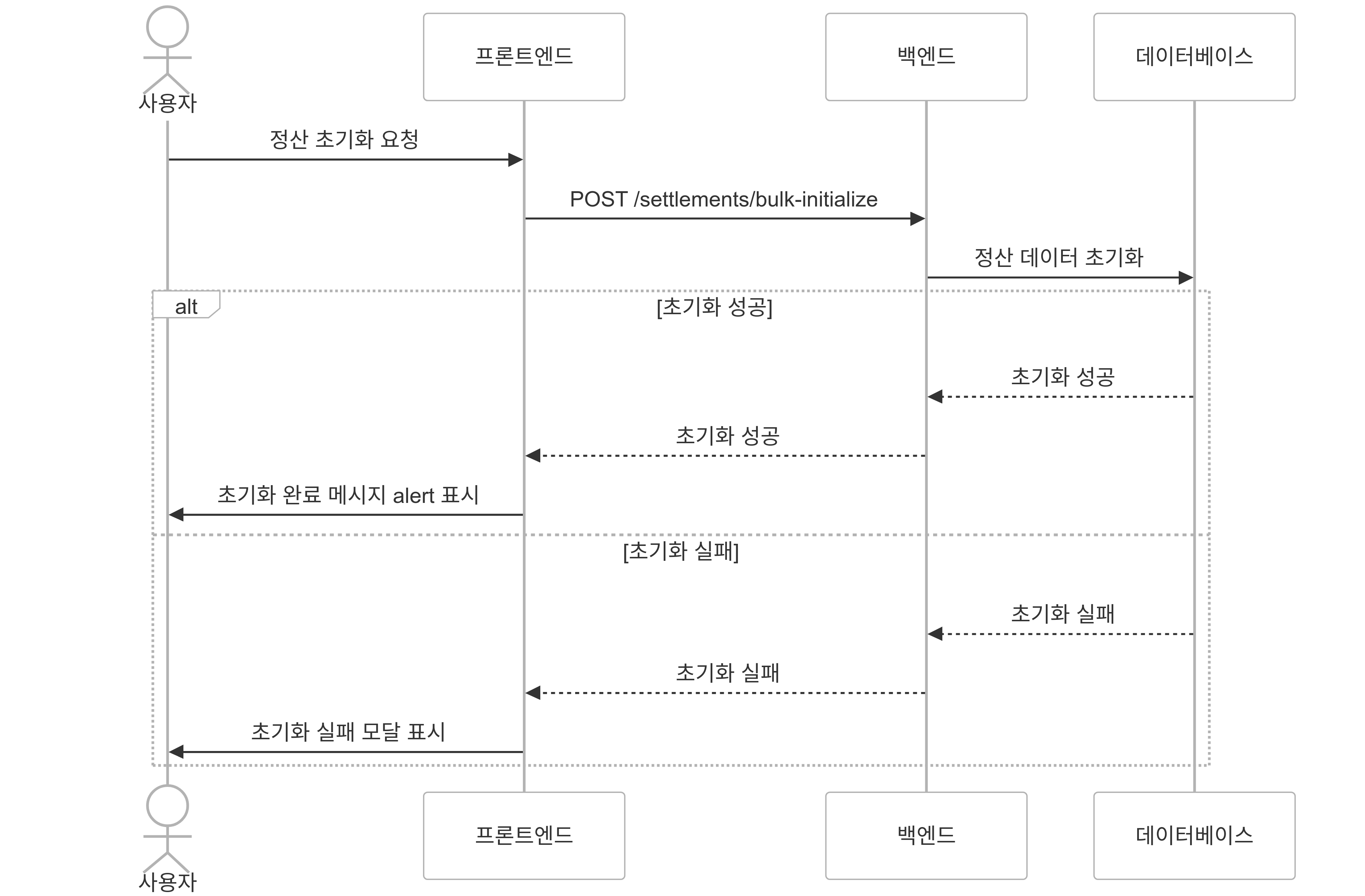
-
당월 정산 전 필수 정보 업데이트를 위해 초기화 정보 조회
-
정산 시작 전 필수 정보 업데이트
-
정산 수수료 계산
-
최종 정산 계산
-
당월 정산 페이징 조회
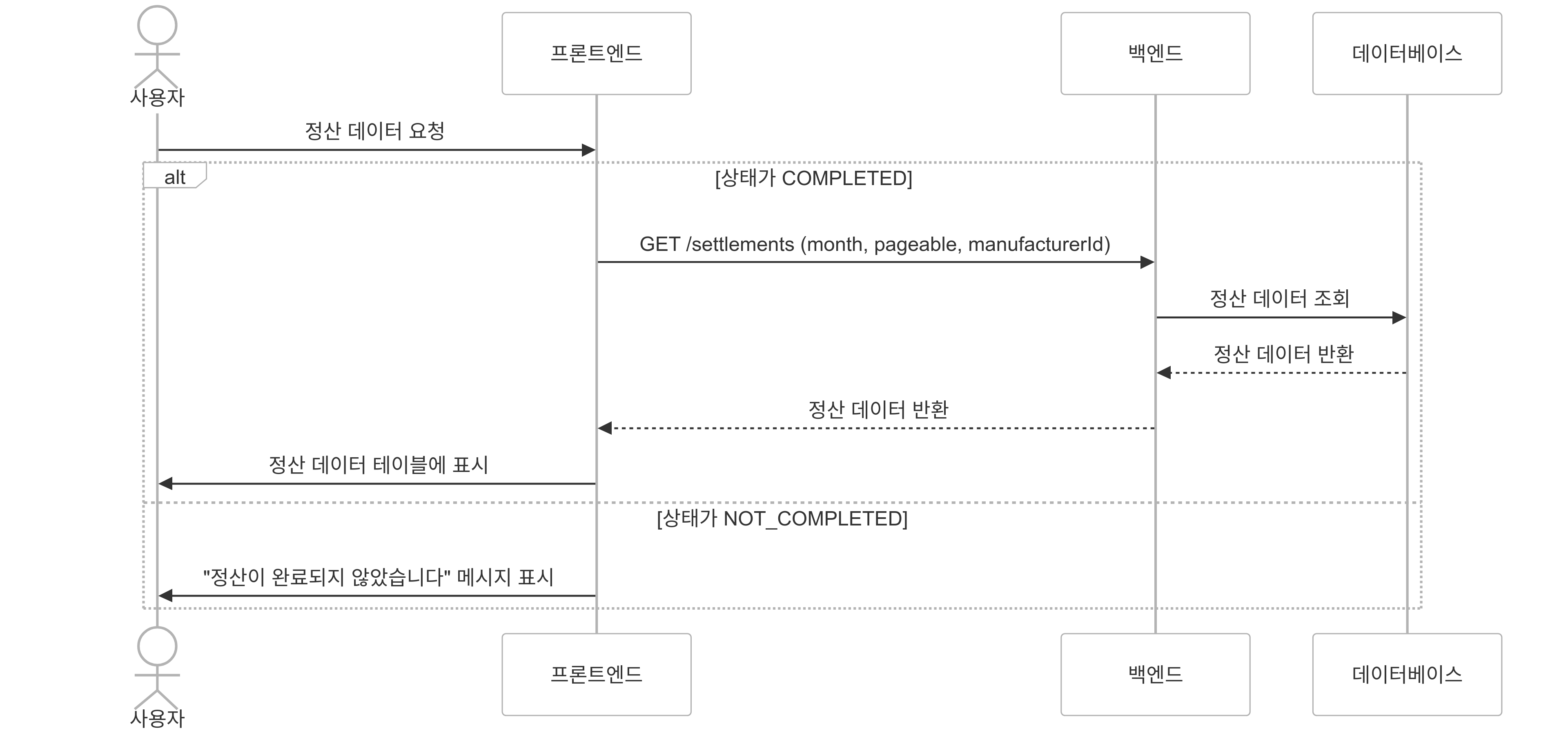
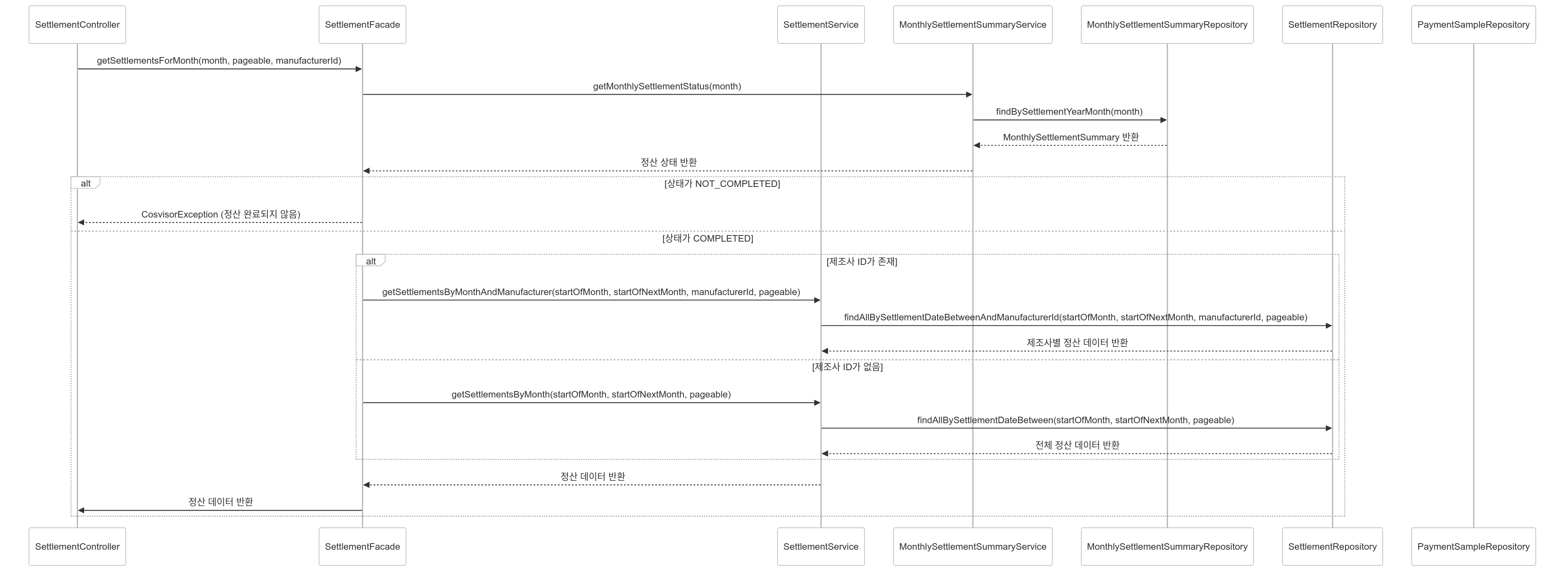
- 초기화된 정산 페이징 조회
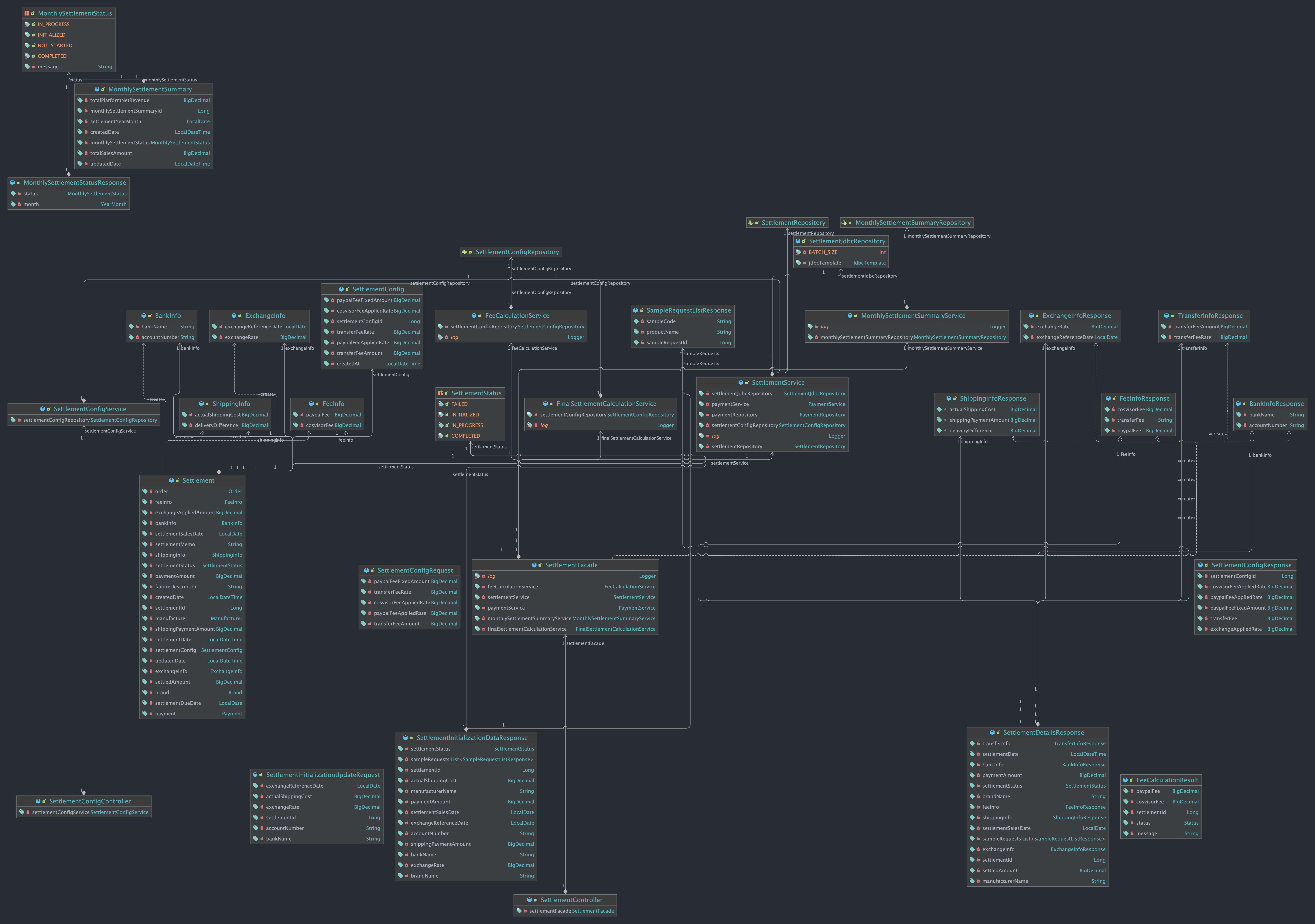
클래스 다이어그램
로직에 관한 고민
-
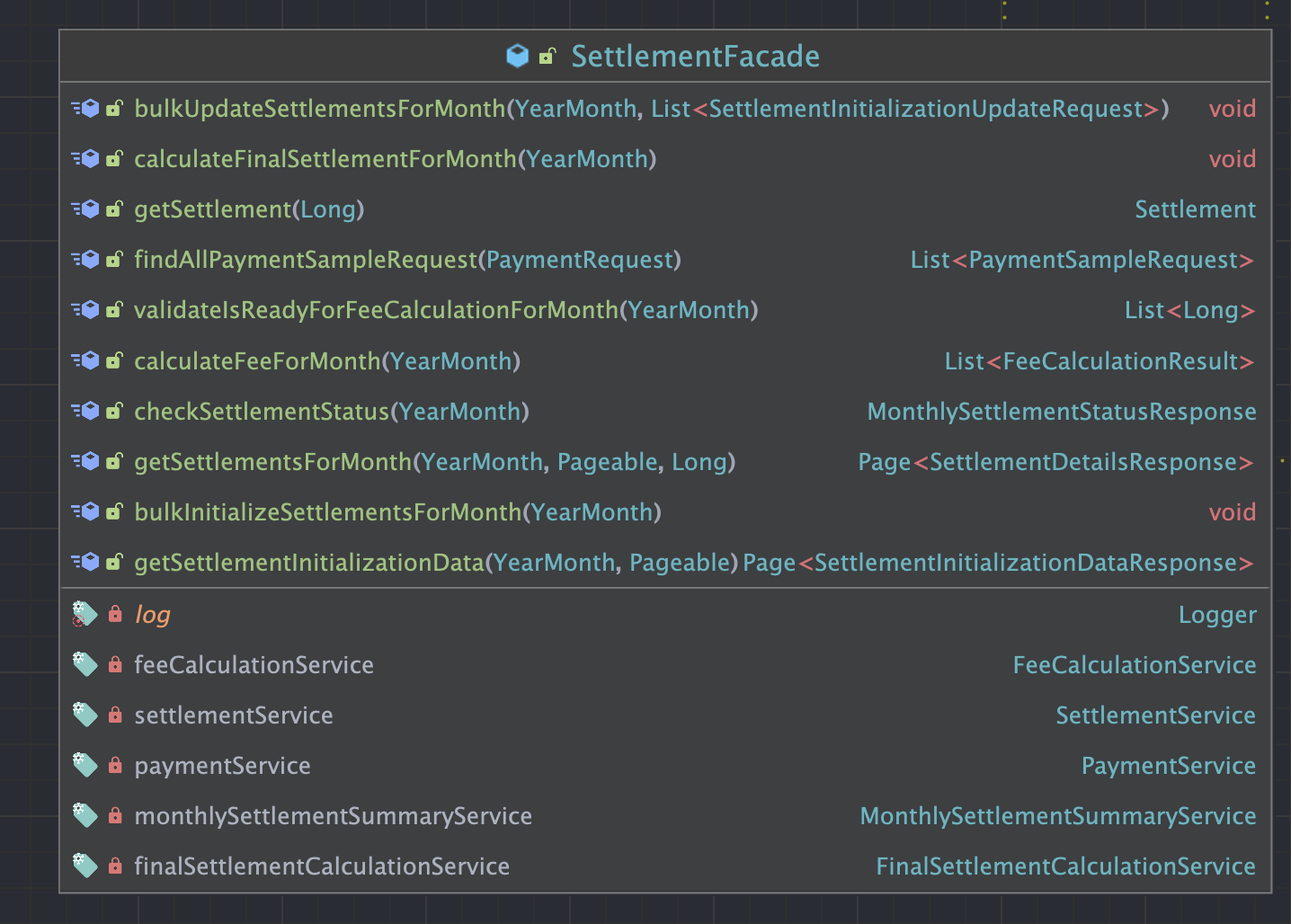
퍼사드 패턴으로 진행
정산 특성상 여러 테이블로부터 정보를 취합해야 했기 때문에 다양한 Service를 이용해야 했다. 따라서 Facade 디자인패턴을 적용해 하위 모듈간의 종속성을 낮출 수 있도록 노력하여 가장 상위 Facade클래스에서 여러 Service를 활용하도록 했다. -
데이터 정합성이 많이 깨져있고 안쓰는 fk키 및 로직들이 있어 어떤 테이블로부터 어떤 정보들을 조합할것인지 고민을 많이 했다. 이것과 관련해서는 대리님께서 많이 도움을 주셨다.
-> 이 과정에서 챗 GPT가 부동소수점을 이용하는 것을 알게 되었다.
정산 초기화
스케줄링
- 수동 초기화
- 가능한 자동화는 최대한 도입하는 것이 효율적이라 판단하여 스케줄링을 적용하였다.
- 무거운 배치 프로세스 대신, @Scheduled 어노테이션과 cron 문법을 활용해 간단하고 가벼운 스케줄링을 구현하였다.
데이터 타입 - BigDecimal
- 숫자 타입을 BigDecimal로 사용
일반 숫자타입은 부동소수점을 사용하지만, BigDecimal은 고정소수점을 사용해 정확한 계산을 할 수 있다.
또한 BigDecimal은 매우 큰 숫자도 다룰 수 있어 보통 금융권에서는 대부분 BigDecimal을 사용한다고 한다.
소수점 처리
지금까지 해온 프로젝트는 숫자를 다뤄도 소수점 처리까지 다룰 비즈니스는 없었다. 원화만 다루었다면 소수점처리까지 필요하지 않았겠지만, 달러 특성상 각종 수수료에 소수점 형태가 많았다.
INSERT, UPDATE 방식
Status
처음에는 세세하게 다루어야한다는 욕심에 Status를 매우 세분화하여 두었다.
초기의 상태는 포트원의 정산 페이지를 참고하여 주문의 Status와 정산의 Status를 아래와 같이 기획했다.
-
주문
- 정산 가능
- 정산 대기
- 주문 취소
- 정산 완료
- 정산 보류
-
정산 Status
- 지급 예정
- 지급 보류
- 지급 실패
- 지급 완료
결제 정산 시스템 설계에서 가장 큰 과제는 다양한 상태를 세밀히 관리하는 것이었다. 그러나 상태가 복잡해질수록 예외 상황을 완벽히 처리할 자신이 없었고, 구조적인 복잡성도 커질 수밖에 없었다. 더불어 정산 데이터를 ‘주문’ 테이블이 아닌 ‘결제’ 테이블에서 가져와야 함을 깨달았다. 이에 따라, ‘주문’ 테이블에 정산 관련 상태(Status)를 추가하는 것은 설계상 맞지 않는 방향이라는 결론을 내렸다.
정산 상태 관리의 본질도 다시 고민하게 되었다. 이를 ‘정산’ 자체의 관리라기보다는 ‘지급 관리’에 더 가깝다고 봤다. 그래서 정산의 본질에 초점을 맞추기로 했고, 초기에는 수동 입력이 많은 현실적인 상황을 감안해 최대한 간단한 구조로 재설계를 진행했다.
이 과정에서 복잡한 상태 관리를 지양하고, 확장성을 고려하되 지금 당장의 필요에 충실한 설계를 목표로 삼았다.
월정산 상태 조회 로직 개선: MonthlySettlementSummary 도입
기존 방식의 문제점
월정산이라는 특성상, 사용자가 특정 월을 클릭하면 해당 월의 정산 상태를 가장 먼저 조회해야 했습니다. 이를 위해 기존에는 다음과 같은 로직이 사용되었습니다:
1. JPA의 DateBetween 문법을 사용해 해당 월의 정산 기간에 속하는 데이터를 검색.
2. SettlementStatus 필드를 기준으로 조건에 맞는 데이터가 있는지 확인.
월정산이라는 특성상 프론트에서 해당 월을 클릭했을 때 우선 당월의 정산 상태를 알아야 했다. 따라서 당월 정산 상태를 조회하는 API를 가장 먼저 호출하여 확인했는데 이때의 서버 로직이 매우 비효율적이었다.
DateBetween JPA 문법을 사용해 해당 기간 내에 특정 SettlementStatus 상태의 컬럼이 있는지 확인하는 방식으로 구현되어 있었다.
DateBetween이 매우 느릴 뿐더러, 정산테이블의 데이터가 매우 많아질 경우 아무리 Exists 문법으로 하나만 찾는다고 하더라도 exists + dateBetween + settlementStatus 검증 방식으로 매번 조회하여 당월 정산 상태를 확인하는 것은 너무나도 비효율적이었다.
따라서 당월 정산 상태를 중앙화하여 관리할 수 있도록 별도로 MonthlySettlementSummary 테이블을 분리하게 되었다.
이렇게 분리함으로써 ~와 같은 장점
최종 Status
SettlementStatus
- INITIALIZED,
- IN_PROGRESS,
- FAILED,
- COMPLETED
MonthlySettlementStatus
- INITIALIZED
- IN_PROGRESS
- COMPLETED
- NOT_STARTED
Validation
- 정산이 가능한 달인지
- 다음 단계로 넘어갈 수 있는 상태인지
- 이전 단계가 완료되었는지, 누락된 필드가 있는지 등등 검증
- Request의
당월 정산 Summary 테이블 분리
예외처리 및 에러 코드
같은 원인의 에러여도 디버깅을 위해서 더 자세히 상황을 알려주어야 하는 것이 좋아보였다. 따라서 어떠한 id때문에 에러가 발생했다면, 해당 id를 포함하여 에러 메시지 및 로그를 찍도록 리팩토링했다.
- 에러코드
- 에러 ENUM
- 에러 코드 (숫자)
- 에러 메시지
테이블/엔티티 정의
도메인적으로 반영하기 위해 관련성이 높은 필드는 VO로 묶어 하나의 애그리거트로 관리될 수 있도록 했다. (@Embeded)
변수 네이밍
통화 관리
모든 금액과 관련한 필드는 원화, 달러 두가지 타입이 있었다.
모두 통상적으로 내부에서 해당 필드의 통화를 알고있다고 가정을 하고 개발을 진행했지만, 원래라면 해당 필드의 금액과 통화를 같이 관리하는 것이 맞다는 판단이 되었다. 하지만 이를 해결하기 위해서는 VO로 풀어야 할 것 같은데, 현재
MonthlySettlementSummary
당월 정산이 필요한 제조사 리스트 조회
- 당월 정산 완료 페이징의 제조사 필터링에 사용할 리스트 조회
-> distinct 문법을 사용해 당월 정산 데이터가 있는 제조사 리스트 선별
아직 비효율적인 로직
- IN_PROGRESS로 넘어가기 위해 해당 기간 내의 데이터들이 필수 정보들이 모두 입력되어있는지 확인함
