개발 환경
- DB : MariaDB
- Driver : net.sf.log4jdbc.sql.jdbcapi.DriverSpy
- 시스템 사양 : 맥북 프로 14 M3, M3 Pro 11코어, 14코어 GPU, 1TB, 36GB
배경
저는 현재 인턴십에서 정산 프로세스를 개발하고 있습니다. 매월 대량의 결제 데이터를 초기화해야 하는 정산 작업의 특성상, 기존에 구현했던 단건 데이터 생성 방식과는 달리 대량 데이터를 한 번에 삽입하는 bulk insert 구현이 필요했습니다.
단건씩 save를 할 경우, DB 커넥션 사용이 증가하면서 데이터 양이 많아질수록 성능이 저하될 수 있다는 가정하에 bulk insert의 필요성을 느꼈습니다.
이 글에서는 bulk insert 과정에서 겪은 트러블 슈팅과 해결 방법, 그리고 성능 테스트 과정에 대해 공유해보고자 합니다.
Bulk Insert를 구현해보자
Driver가
net.sf.log4jdbc.sql.jdbcapi.DriverSpy임에 따라 jdbcTemplate의 bulk Insert를 통해 실제로 나가는 쿼리는 확인할 수 없었습니다.
이에 직접 프로젝트를 구성하여 MySQL, MySQL driver로 다음과 같이 설정하였습니다.spring: datasource: url: jdbc:mysql://localhost:3306/db명?rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=999999
save
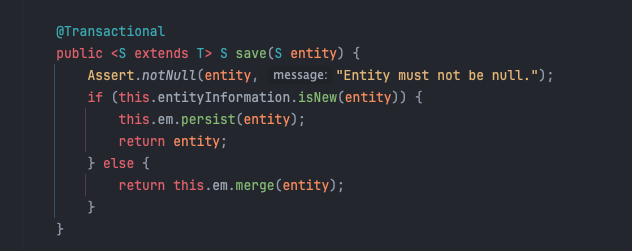
기존에는 반복문을 돌며, 각 객체들에 개별로 JPA의 save() 메서드를 호출했는데요, 먼저 JpaRepository의 구현체인 SimpleJpaRepository.java를 살펴보면 save()의 동작 코드는 아래와 같습니다.
하나의 트랜잭션으로 관리되며, 새 엔티티의 경우 persist()를 호출하여 데이터베이스에 저장하고, 기존 엔티티라면 merge()를 호출하여 변경된 필드를 데이터베이스에 반영합니다.
따라서 단건 저장에는 적합할 수 있지만, 대용량 데이터를 bulk로 insert할 경우에는 적합하지 않아보입니다.
save All
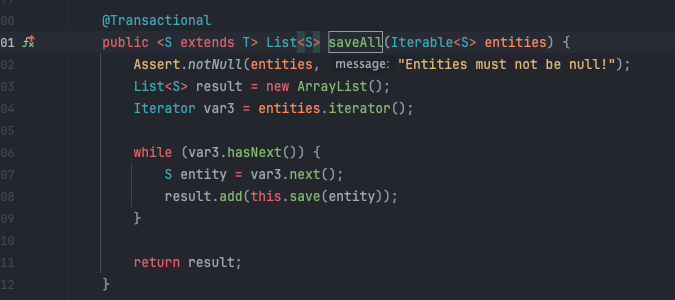
그렇다면 SimpleJpaRepository.java에서 saveAll() 메서드는 어떻게 구현되어 있을까요? 아래 사진을 보면, saveAll은 내부적으로 각 엔티티마다 save 메서드를 사용하여 개별적으로 처리하고 있습니다.
그러나 메서드 레벨에 트랜잭션이 설정되어 있어 saveAll을 작업하는 동안은 동일한 트랜잭션 내에서 수행되기 때문에 save를 직접 반복 호출하는 것 보다는 조금 더 효율적일 수 있습니다. (즉, saveAll()을 사용하는 경우, 트랜잭션은 한 번만 생성됩니다.)
그러나 마찬가지로, 대용량 데이터 처리에는 여전히 각각 엔티티에 대해 개별 쿼리를 수행하기 때문에 네트워크와 데이터베이스 I/O가 많아져 성능이 저하됩니다. 즉, 진정한 배치 성능 향상을 얻기에는 어려워 보입니다.
그러나 이는 아래와 같이 하이버네이트 배치 설정을 통해 해결할 수 있습니다.
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 100또한 MySQL JDBC의 경우 JDBC URL에
rewriteBatchedStatements=true옵션을 추가해야 합니다.jdbc-url: jdbc:mysql://localhost:3306/hibernate_batch?rewriteBatchedStatements=trueMySQL의 경우 실제로 생성된 쿼리는
logger=com.mysql.jdbc.log.Slf4JLogger&profileSQL=true옵션으로 로그를 통해 확인할 수 있습니다.
https://kwonnam.pe.kr/wiki/java/hibernate/batch
하이버네이트는 JDBC의 배치 기능을 활용하여 PreparedStatement.addBatch()로 쿼리를 모으고, 설정한 배치 크기에 도달하면 PreparedStatement.executeBatch()를 호출하여 DB로 한번에 전송합니다. 이를 통해 DB 통신 횟수와 락 사용 횟수를 줄여 성능을 향상시킵니다.
MySQL 환경의 스프링부트에 하이버네이트 배치 설정해 보기
배치 설정을 마쳤으니 테스트코드를 통해 확인해보도록 하겠습니다.
@ActiveProfiles("test")
@SpringBootTest
public class SettlementBulkUpdateTest {
@PersistenceContext
private EntityManager entityManager;
@Autowired
private SettlementRepository settlementRepository;
@Autowired
private SettlementJdbcRepository settlementJdbcRepository;
@Autowired
private SettlementConfigRepository settlementConfigRepository;
@Autowired
private PaymentRepository paymentRepository;
@Autowired
private BrandJpaRepository brandJpaRepository;
@Autowired
private ManufacturerJpaRepository manufacturerJpaRepository;
@MockBean
private ServletServerContainerFactoryBean createServletServerContainerFactoryBean;
private static final int TEST_COUNT = 10;
private final YearMonth month = YearMonth.now();
private Brand brand;
private Manufacturer manufacturer;
private SettlementConfig latestConfig;
private List<Payment> payments;
private List<Settlement> settlements;
@BeforeEach
public void setUp() {
settlementRepository.deleteAll();
paymentRepository.deleteAll();
setUpBrandAndManufacturer();
setUpSettlementConfig();
setUpPayments();
setUpSettlements();
settlementJdbcRepository.saveAll(settlements);
entityManager.flush();
entityManager.clear(); // 영속성 컨텍스트 초기화
// JPA에서 저장된 상태로 다시 불러오기
settlements = settlementRepository.findAll();
}
private void setUpBrandAndManufacturer() {
brand = Brand.builder()
.brandName("Ogu Brand")
.build();
brandJpaRepository.save(brand);
manufacturer = Manufacturer.builder()
.manufacturerName("Mock Manufacturer")
.build();
manufacturerJpaRepository.save(manufacturer);
}
private void setUpSettlementConfig() {
latestConfig = SettlementConfig.builder()
.cosvisorFeeAppliedRate(BigDecimal.valueOf(10))
...
.build();
settlementConfigRepository.save(latestConfig);
}
private void setUpPayments() {
LocalDateTime baseDate = month.atDay(1).atStartOfDay();
int daysInMonth = month.lengthOfMonth();
payments = new ArrayList<>();
for (int i = 0; i < TEST_COUNT; i++) {
Payment payment = Payment.builder()
.paymentAmount(1000 + i * 100)
...
.build();
payments.add(payment);
}
paymentRepository.saveAll(payments);
}
private void setUpSettlements() {
settlements = payments.stream()
.map(payment -> Settlement.builder()
.settlementConfig(latestConfig)
.payment(payment)
...
.collect(Collectors.toList());
}
@Test
@Transactional
@DisplayName("JPA의 saveAll은 Bulk Update 시에 개별 UPDATE 쿼리를 생성한다.")
public void testBulkUpdateSQLGeneratedBySaveAll() {
// given: 영속화된 엔티티 목록 조회
List<Settlement> managedSettlements = settlementRepository.findAll();
// 상태를 COMPLETED로 변경
managedSettlements.forEach(settlement -> settlement.updateSettlementStatus(SettlementStatus.COMPLETED));
// when: 상태가 변경된 엔티티를 saveAll 호출로 업데이트
settlementRepository.saveAll(managedSettlements);
// then: 업데이트된 상태 검증
List<Settlement> updatedSettlements = settlementRepository.findAll();
assertThat(updatedSettlements).hasSize(TEST_COUNT);
assertThat(updatedSettlements.stream()
.allMatch(settlement -> settlement.getSettlementStatus() == SettlementStatus.COMPLETED))
.isTrue();
}
}하지만 쿼리문을 살펴보면 저희가 생각했던 바와 달리 단건으로 INSERT문이 실행되고 있습니다. (사진이 날아갔네요 ㅠㅠ)
왜일까요?
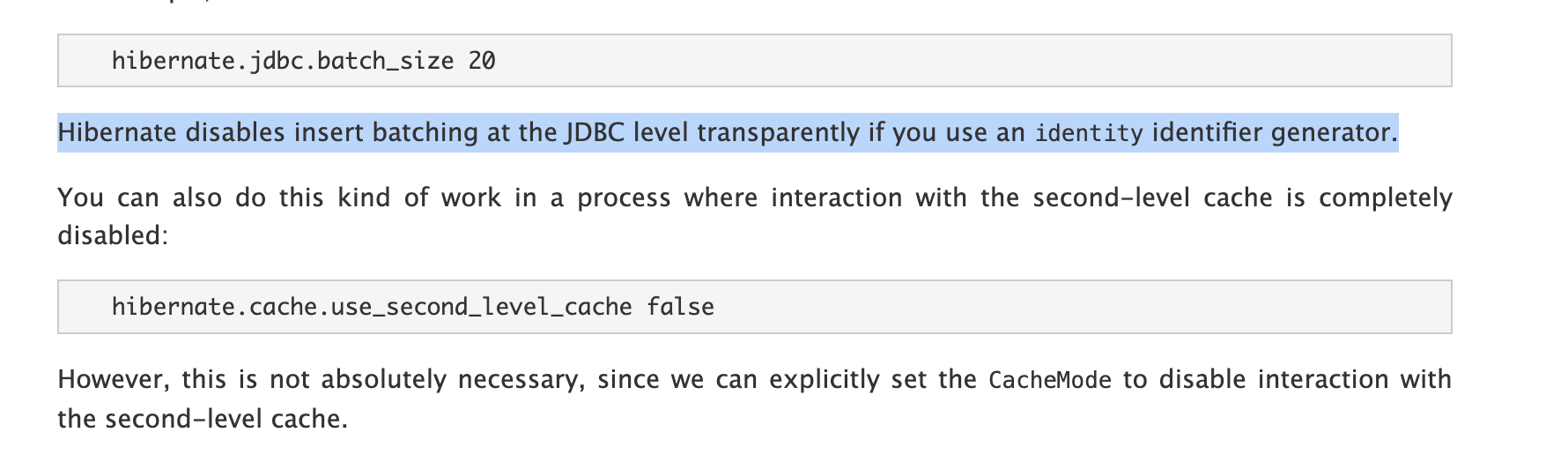
MySQL에서 IDENTITY(auto_increment) 전략을 사용하면, ID 값이 데이터베이스 삽입 시에만 생성되므로 Hibernate는 insert batching을 지원하지 않습니다.
ID 값을 미리 알 수 없는 상황에서 Hibernate는 배치를 비활성화하기 때문입니다.
따라서 MySQL과 auto_increment를 사용해 대량 삽입을 수행하려면 JPA 대신 JDBC나 native SQL을 사용해야 합니다.
Hibernate 공식문서에는 다음과 같이 나와있습니다.
💡 Hibernate disables insert batching at the JDBC level transparently if you use an
identityidentifier generator.
https://docs.jboss.org/hibernate/orm/4.1/manual/en-US/html/ch15.html
Hibernate의 매커니즘 상 Id를 알 수 없는 경우 Transactional write behind(트랜잭션을 지원하는 쓰기 지연) 방식과 충돌한다.
→ 트랜잭션 쓰기 지연 : 트랜잭션이 커밋 될 때까지 내부 쿼리 저장소에 모아뒀다가 한 번에 실행
Persistence Context 내부에서 엔티티를 식별할때는 엔티티 타입과 엔티티의 id 값으로 엔티티를 식별하지만 IDENTITY 의 경우 DB에 insert 문을 실행해야만 id 값을 확인 가능하기 때문에 batch insert 를 비활성화
MySQL 환경의 스프링부트에 하이버네이트 배치 설정해 보기 | 우아한형제들 기술블로그
ID 생성 전략이 IDENTITY일 때 Bulk Insert
이러한 대표적인 JPA 구현체인 하이버네이트의 특성에 따라 JPARepository를 통한 IDENTITY전략의 항목들에 대해 bulk Insert가 불가능했고, 이를 해결할 방법이 필요했습니다.
JdbcTempalte의 batchUpdate()
jdbcTemplate의 batchUpdate() 메서드 사용,
batch의 적정 사이즈는 아래와 같다고 합니다.
- 작은 데이터베이스 또는 개발 환경 : 100~200
- 운영 환경 또는 강력한 DB 서버 : 500 ~ 1000개
우선 현재 상태에서는 고성능의 DB를 사용하고 있지는 않은 것 같아 우선 배치 사이즈를 100개로 설정하여 테스트를 진행하였다.
JdbcTemplate에 구현되어있는 batchUpdate() 메서드의 코드는 아래와 같습니다.
public <T> int[][] batchUpdate(String sql, final Collection<T> batchArgs, final int batchSize, final ParameterizedPreparedStatementSetter<T> pss) throws DataAccessException {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Executing SQL batch update [" + sql + "] with a batch size of " + batchSize);
}
int[][] result = (int[][])this.execute(sql, (ps) -> {
List<int[]> rowsAffected = new ArrayList();
try {
boolean batchSupported = JdbcUtils.supportsBatchUpdates(ps.getConnection());
int n = 0;
Iterator var8 = batchArgs.iterator();
while(var8.hasNext()) {
T obj = var8.next();
pss.setValues(ps, obj);
++n;
int batchIdx;
if (batchSupported) {
ps.addBatch();
if (n % batchSize == 0 || n == batchArgs.size()) {
if (this.logger.isTraceEnabled()) {
batchIdx = n % batchSize == 0 ? n / batchSize : n / batchSize + 1;
int items = n - (n % batchSize == 0 ? n / batchSize - 1 : n / batchSize) * batchSize;
this.logger.trace("Sending SQL batch update #" + batchIdx + " with " + items + " items");
}
rowsAffected.add(ps.executeBatch());
}
} else {
batchIdx = ps.executeUpdate();
rowsAffected.add(new int[]{batchIdx});
}
}
int[][] result1 = new int[rowsAffected.size()][];
for(int i = 0; i < result1.length; ++i) {
result1[i] = (int[])rowsAffected.get(i);
}
int[][] var17 = result1;
return var17;
} finally {
if (pss instanceof ParameterDisposer) {
((ParameterDisposer)pss).cleanupParameters();
}
}
});
Assert.state(result != null, "No result array");
return result;
}jdbcTemplate으로 batchInsert 구현하기
@Repository
@RequiredArgsConstructor
public class SettlementJdbcRepository {
private final JdbcTemplate jdbcTemplate;
private static final int BATCH_SIZE = 100;
@Transactional
public void saveAll(List<Settlement> settlements) {
String sql = "INSERT INTO settlement (settlement_config_id, payment_id, brand_id, manufacturer_id, ...) " +
"VALUES (?, ?, ?, ?, ?, ?, ?, ?)";
for (int i = 0; i < settlements.size(); i += BATCH_SIZE) {
List<Settlement> batchList = settlements.subList(i, Math.min(i + BATCH_SIZE, settlements.size()));
jdbcTemplate.batchUpdate(sql, batchList, batchList.size(), (ps, settlement) -> {
ps.setLong(1, settlement.getSettlementConfig().getSettlementConfigId());
ps.setLong(...);
ps.setLong(...);
....
});
}
}
}여기서 ps.set~ 메서드 안의 숫자(1, 2, 3, 등)는 SQL의 각 ? 위치에 값을 할당하기 위한 인덱스로, 예를 들어 위의 코드에선 아래와 같이 매핑됩니다.
| 위치 인덱스 | 컬럼 이름 | 데이터 설정 메서드 예시 |
|---|---|---|
| 1 | settlement_config_id | ps.setLong(1, settlement.getSettlementConfig().getSettlementConfigId()); |
| 2 | payment_id | ps.setLong(2, settlement.getPayment().getId()); |
| 3 | brand_id | ps.setLong(3, settlement.getBrand().getBrandId()); |
| ... | ... | ... |
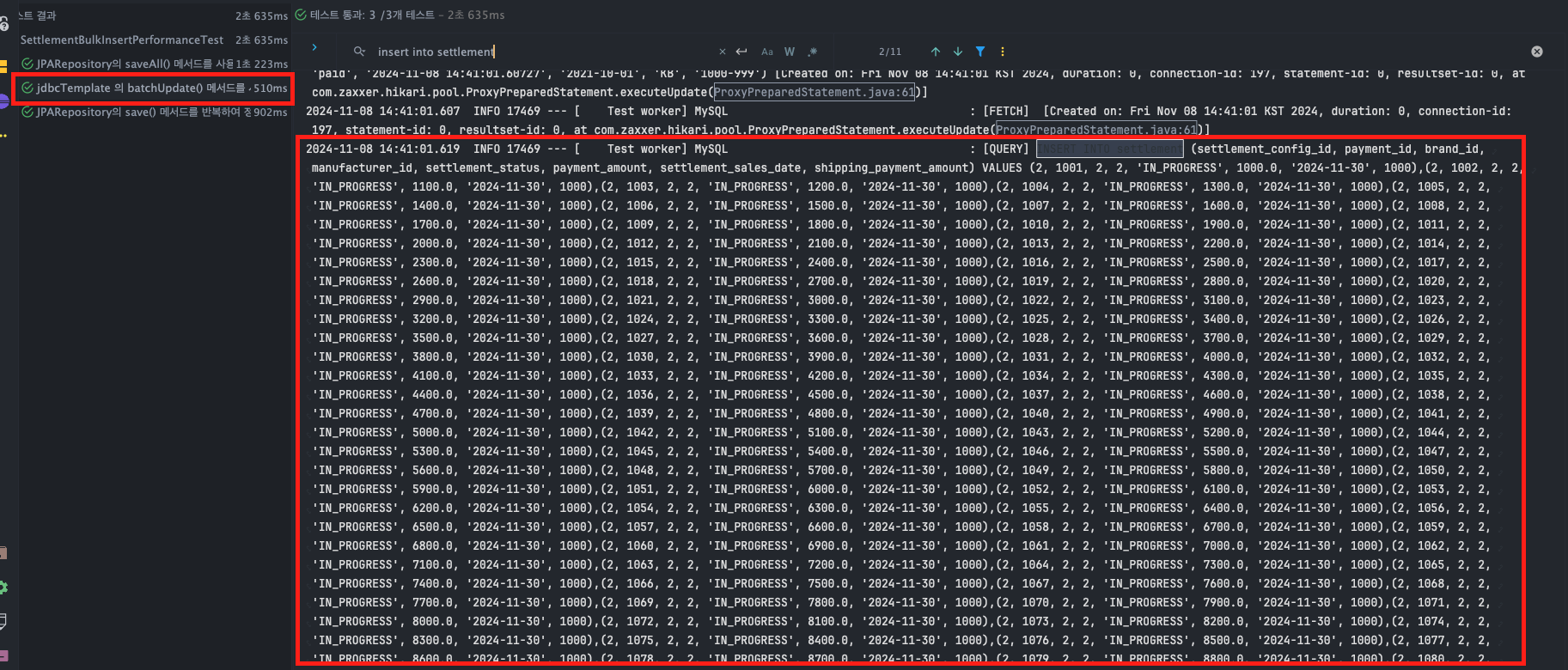
테스트코드를 통해 실제 쿼리를 확인해 보면, 아래와 같이 의도한 바 대로 배치 사이즈만큼 하나의 INSERT문을 통해 저장하고 있음을 확인할 수 있습니다.
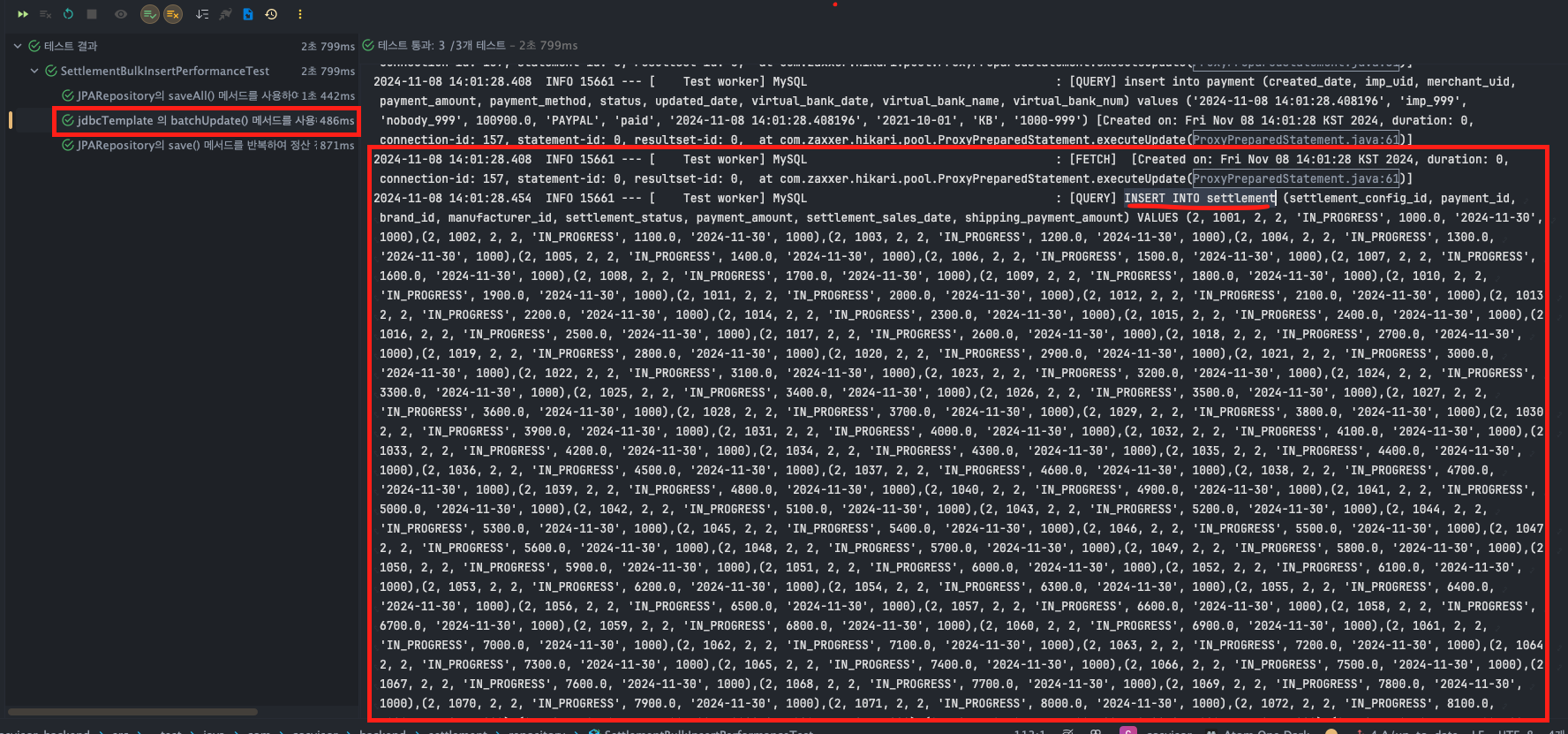
성능 테스트
Test 어노테이션
@DataJpaTest
Spring Boot에서 @DataJpaTest를 사용하면 기본적으로 각 테스트 메서드는 트랜잭션 내에서 실행되며, 테스트 완료 시 자동으로 롤백됩니다. 따라서 테스트 데이터가 남지 않아 테스트 간의 데이터 격리를 유지할 수 있습니다.
@DataJpaTest는 기본적으로 H2 인메모리를 사용한다.
참고
https://emgc.tistory.com/143
@DataJpaTest는 기본적으로 JPA와 관련된 빈만을 로드하도록 설정된 테스트이기 때문에, 주로 JpaRepository를 상속한 레포지토리를 테스트하는 데 사용됩니다. @DataJpaTest는 JPA와 관련된 설정을 자동으로 구성하고, 기본적으로 JdbcTemplate을 포함하지 않습니다. 따라서 @DataJpaTest 환경에서는 JdbcTemplate이 자동으로 빈으로 주입되지 않기 때문에 JdbcTemplate 관련 테스트를 수행할 수 없습니다.
만약 JdbcTemplate을 사용하여 테스트를 진행하고 싶다면, @SpringBootTest를 사용하여 전체 애플리케이션 컨텍스트를 로드하거나 @DataJpaTest와 함께 @AutoConfigureTestDatabase를 추가하고 JdbcTemplate 빈을 명시적으로 구성할 수 있습니다.
@DataJpaTest는 주로 JPA 엔티티와 JPA 레포지토리를 테스트하는 데 최적화되어 있어서, JdbcTemplate과 관련된 레이어는 추가 설정이 필요한 점 참고하시기 바랍니다.
@SpringBootTest
@SpringBootTest는 전체 스프링 애플리케이션 컨텍스트를 로드하여, 애플리케이션이 실제로 실행될 때와 동일한 환경에서 테스트를 진행할 수 있도록 합니다. 즉, 모든 빈과 설정이 로드되므로 @DataJpaTest처럼 특정 레이어만 테스트하는 것이 아닌, 전체 애플리케이션 흐름을 테스트할 수 있습니다.
@SpringBootTest로 테스트를 진행할 때 @Transactional을 함께 사용하면, 테스트가 끝난 후 해당 트랜잭션이 자동으로 롤백됩니다. 이 방식은 데이터베이스 상태를 테스트 이전 상태로 유지해주기 때문에, 테스트 간 데이터가 쌓이거나 변경되는 문제를 방지할 수 있습니다. 이렇게 함으로써 각 테스트가 독립적으로 실행되며, 데이터 일관성도 유지할 수 있습니다.
@SpringBootTest와 @Transactional의 주요 특징
- 테스트 격리: 각 테스트가 끝날 때마다 롤백되어 데이터베이스가 초기 상태로 돌아가므로, 이후 테스트에 영향을 주지 않습니다.
- 일관성 유지: 데이터베이스의 상태가 테스트 중 변경되지 않으므로, 동일한 테스트 데이터를 바탕으로 반복 실행해도 결과에 차이가 없습니다.
따라서, @SpringBootTest 환경에서 데이터베이스와 연관된 테스트를 진행할 때는 @Transactional을 사용하여 데이터의 일관성을 보장하는 것이 좋습니다.
@Rollback의 기본값은 true로, @Rollback을 명시적으로 설정하지 않으면 테스트는 기본적으로 롤백됩니다.
Spring Boot에서 @DataJpaTest나 @Transactional을 사용한 테스트는 기본적으로 자동 롤백됩니다. 따라서 @Rollback을 생략해도 테스트 후 데이터가 DB에 남지 않고 삭제됩니다.
application-test.yml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/cosvisor-local?rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=999999
username: root
password: 1234
jpa:
properties:
hibernate:
jdbc:
batch_size: 100
hibernate:
ddl-auto: create
logging:
level:
jdbc:
sqlonly: "off"
sqltiming: "debug"
resultsettable: "info"
audit: "off"
resultset: "off"
connection: "off"
성능테스트 테스트코드 작성
@ActiveProfiles("test")
@SpringBootTest
@Transactional
public class SettlementBulkInsertPerformanceTest {
@Autowired
private SettlementRepository settlementRepository;
@Autowired
private SettlementJdbcRepository settlementJdbcRepository;
@Autowired
private SettlementConfigRepository settlementConfigRepository;
@Autowired
private PaymentRepository paymentRepository;
@Autowired
private BrandJpaRepository brandJpaRepository;
@Autowired
private ManufacturerJpaRepository manufacturerJpaRepository;
@MockBean
private ServletServerContainerFactoryBean createServletServerContainerFactoryBean;
private static final int TEST_COUNT = 10000;
private final YearMonth month = YearMonth.now();
private Brand brand;
private Manufacturer manufacturer;
private SettlementConfig latestConfig;
private List<Payment> payments;
private List<Settlement> settlements;
@BeforeEach
public void setUp() {
setUpBrandAndManufacturer();
setUpSettlementConfig();
setUpPayments();
setUpSettlements();
}
// 브랜드와 제조업체 설정
private void setUpBrandAndManufacturer() {
brand = Brand.builder()
.brandName("Ogu Brand")
.build();
brandJpaRepository.save(brand);
manufacturer = Manufacturer.builder()
.manufacturerName("Mock Manufacturer")
.build();
manufacturerJpaRepository.save(manufacturer);
}
// SettlementConfig 설정
private void setUpSettlementConfig() {
latestConfig = SettlementConfig.builder()
.cosvisorFeeAppliedRate(BigDecimal.valueOf(10))
.paypalFeeAppliedRate(BigDecimal.valueOf(4.4))
.paypalFeeFixedAmount(BigDecimal.valueOf(0.3))
.transferFeeRate(BigDecimal.valueOf(97))
.transferFeeAmount(BigDecimal.valueOf(1500))
.build();
settlementConfigRepository.save(latestConfig);
}
// 결제 데이터 생성
private void setUpPayments() {
LocalDateTime baseDate = month.atDay(1).atStartOfDay();
int daysInMonth = month.lengthOfMonth();
payments = new ArrayList<>();
for (int i = 0; i < TEST_COUNT; i++) {
Payment payment = Payment.builder()
.paymentAmount(1000 + i * 100)
.paymentMethod("PAYPAL")
.merchantUid("nobody_" + i)
.impUid("imp_" + i)
.virtualBankName("KB")
.virtualBankNum("1000-" + i)
.virtualBankDate("2021-10-01")
.createdDate(baseDate.plusDays(i % daysInMonth))
.status(PaymentDTO.Status.PAID.getValue())
.build();
payments.add(payment);
}
paymentRepository.saveAll(payments);
}
// 결제 데이터로부터 정산 데이터 생성
private void setUpSettlements() {
settlements = payments.stream()
.map(payment -> Settlement.builder()
.settlementConfig(latestConfig)
.payment(payment)
.brand(brand)
.manufacturer(manufacturer)
.settlementStatus(SettlementStatus.IN_PROGRESS)
.paymentAmount(BigDecimal.valueOf(payment.getPaymentAmount()))
.settlementSalesDate(month.atEndOfMonth())
.shippingPaymentAmount(BigDecimal.valueOf(1000))
.build())
.collect(Collectors.toList());
}
@Test
@DisplayName("JPARepository의 save() 메서드를 반복하여 정산 정보를 초기화한다.")
public void settlementBulkInsertWithJpaSave() {
// given
long startTime = System.currentTimeMillis();
// when
for (Settlement settlement : settlements) {
settlementRepository.save(settlement);
}
// then
long endTime = System.currentTimeMillis();
System.out.println("execution time : " + (endTime - startTime) + "ms");
assertThat(settlementRepository.count()).isEqualTo(TEST_COUNT);
}
@Test
@DisplayName("JPARepository의 saveAll() 메서드를 사용하여 정산 정보를 초기화한다.")
public void settlementBulkInsertWithJpaSaveAll() {
// given
long startTime = System.currentTimeMillis();
// when
settlementRepository.saveAll(settlements);
// then
long endTime = System.currentTimeMillis();
System.out.println("execution time : " + (endTime - startTime) + "ms");
assertThat(settlementRepository.count()).isEqualTo(TEST_COUNT);
}
@Test
@DisplayName("jdbcTemplate 의 batchUpdate() 메서드를 사용하여 정산 정보를 초기화한다.")
public void setSettlementBulkInsertWithJdbcBatchInsert() {
// given
long startTime = System.currentTimeMillis();
// when
settlementJdbcRepository.saveAll(settlements);
// then
long endTime = System.currentTimeMillis();
System.out.println("execution time : " + (endTime - startTime) + "ms");
assertThat(settlementRepository.count()).isEqualTo(TEST_COUNT);
}
}데이터 1,000건 insert
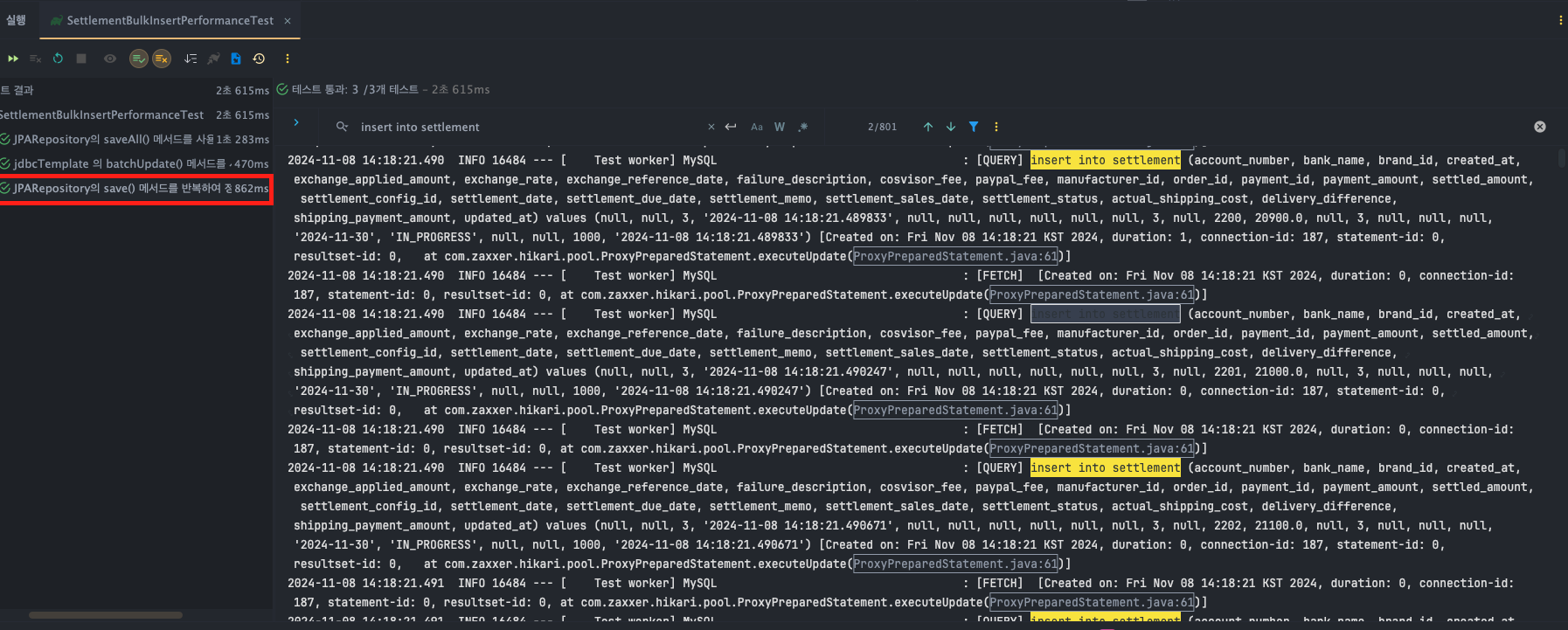
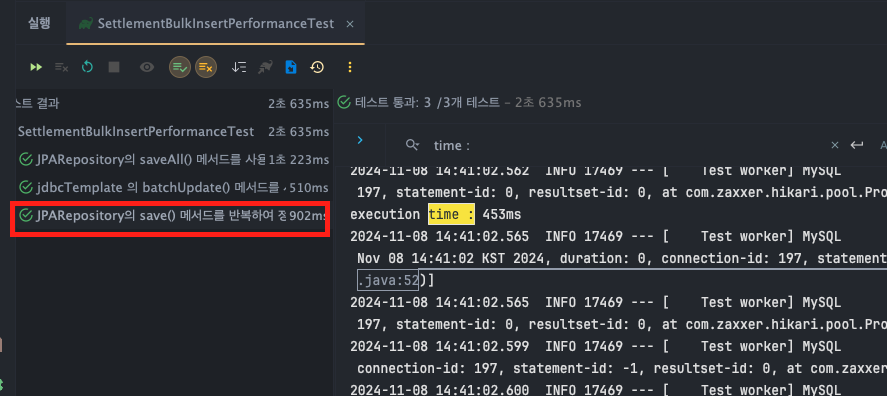
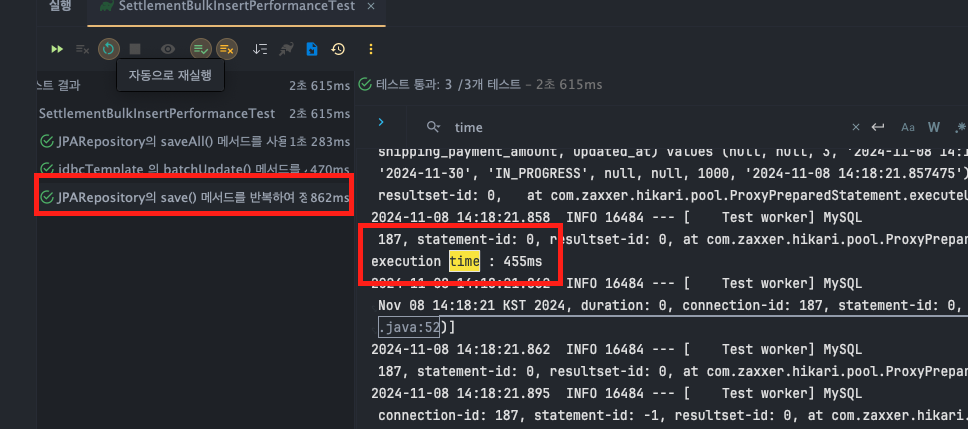
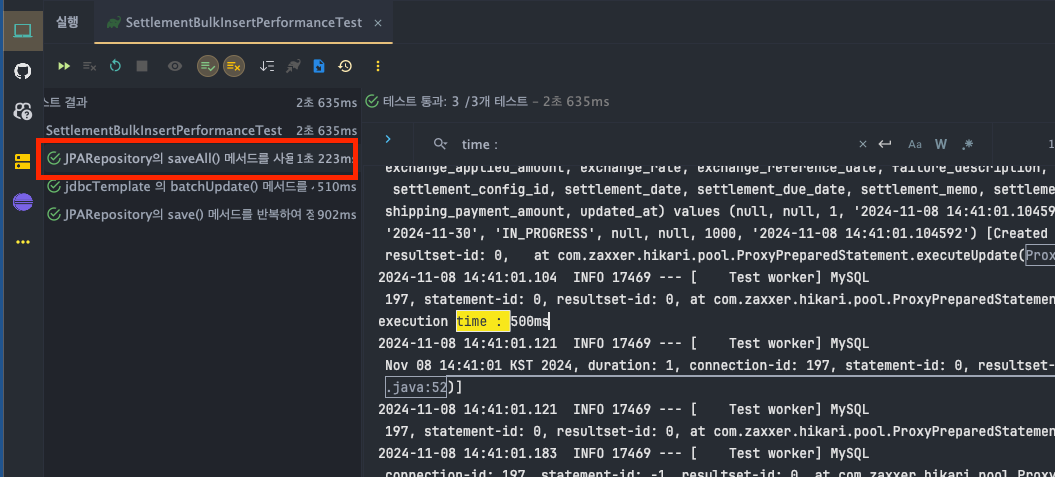
JPARepository - save()
- execution time : T1 : 453ms, T2 : 455ms, T3 : 453 ms
JPARepository - saveAll()
- execution time : T1 : 500ms, T2 : 559ms, T3 : 567ms
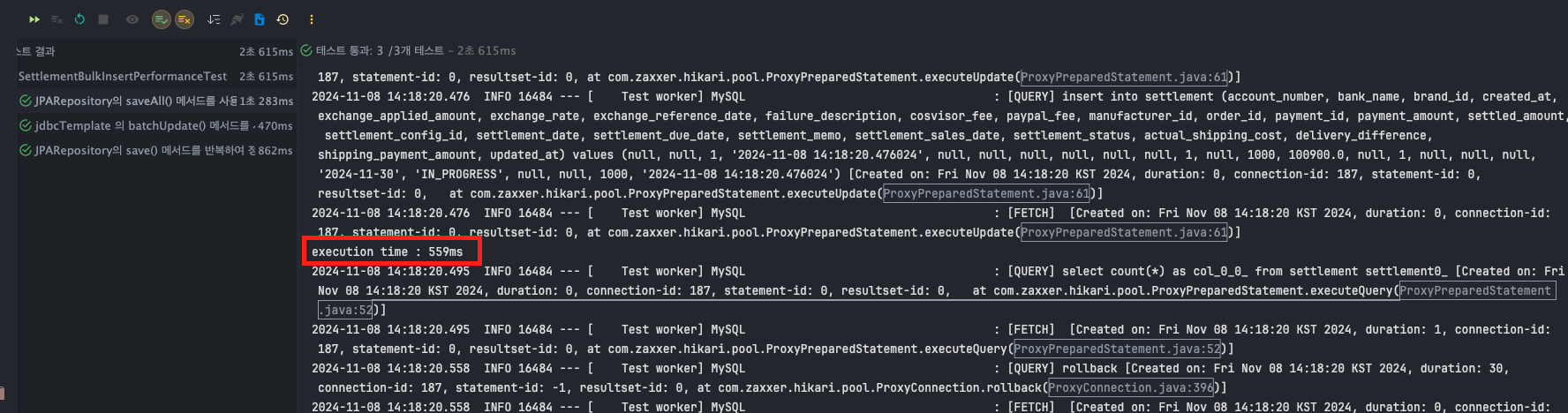
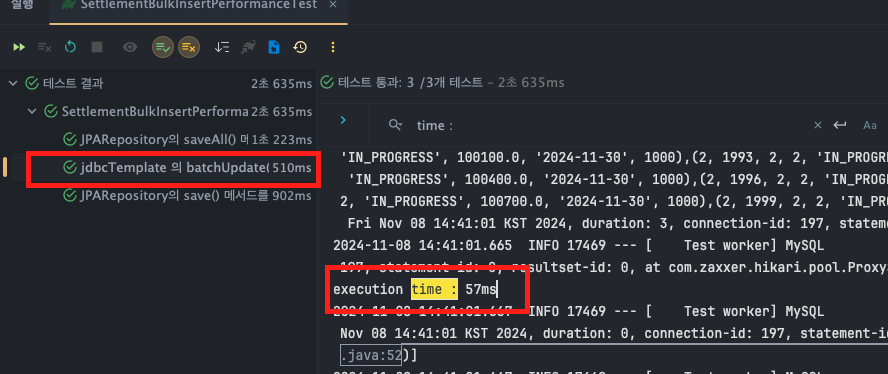
jdbcTemplate - batchUpdate()
- execution time : T1 : 59ms, T2 : 59ms, T3 : 61ms
데이터 10,000건 bulk insert
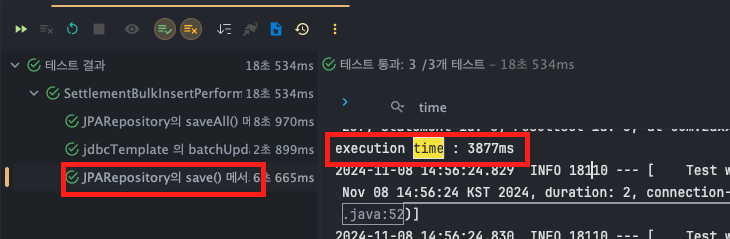
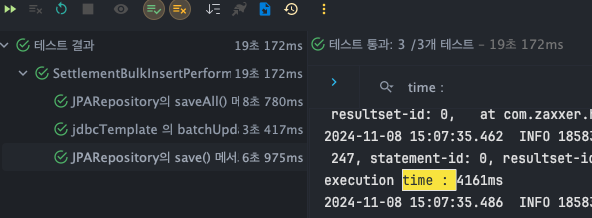
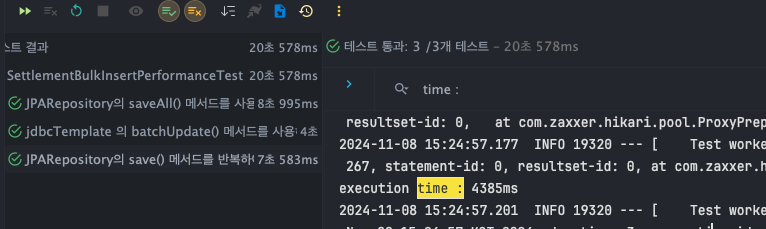
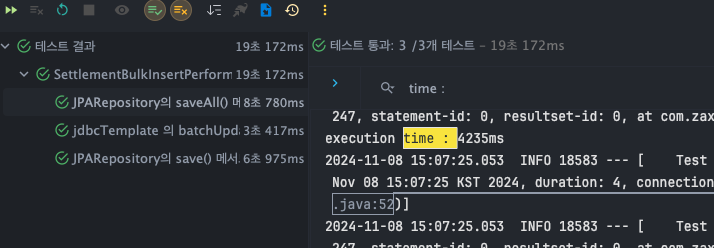
JPARepository - save()
- T1 : 3877ms
- T2 : 4161ms
- T3 : 4375ms
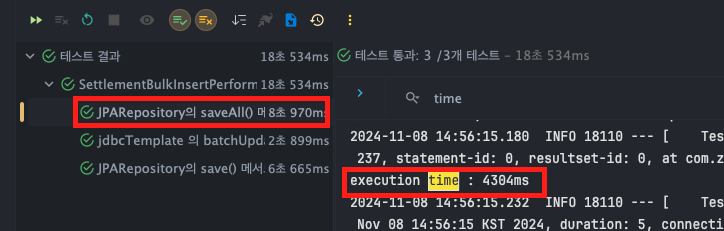
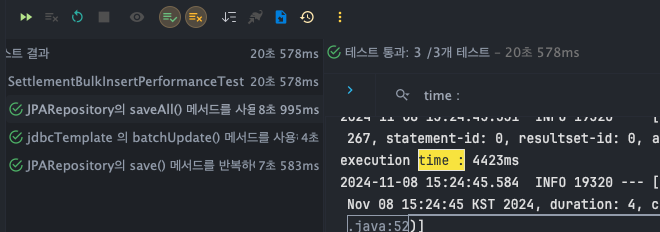
JPARepository - saveAll()
- T1 : 4304ms
- T2 : 4235ms
- T3 : 4423ms
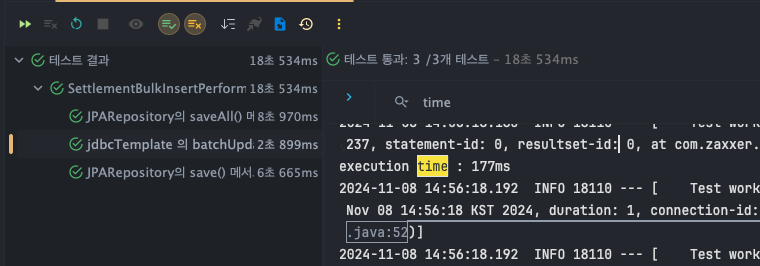
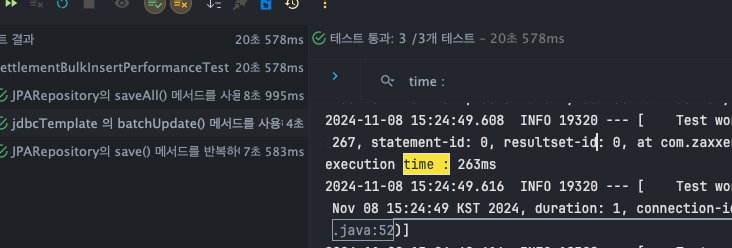
jdbcTemplate - batchUpdate()
- T1 : 177ms
- T2 : 200ms
- T3 : 263ms
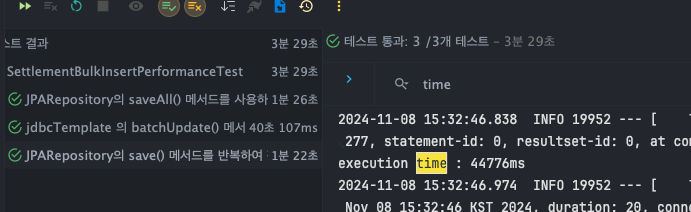
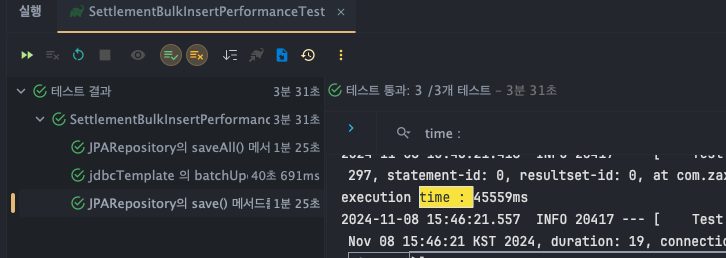
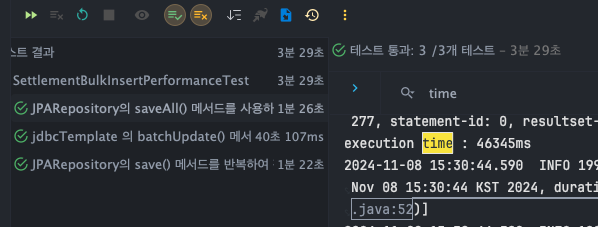
데이터 100,000건 bulk insert
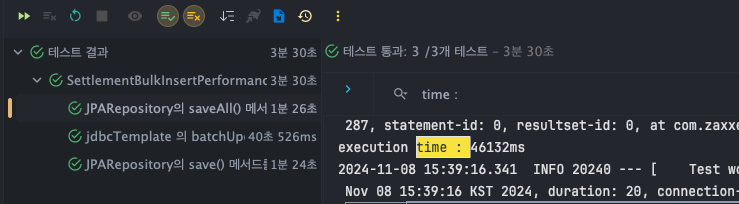
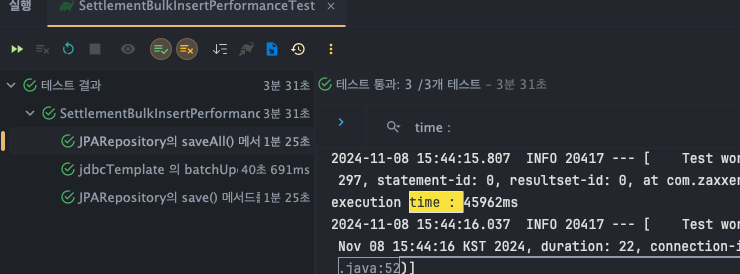
JPARepository - save()
- T1 : 44776ms
- T2 : 44946ms
- T3 : 45559ms
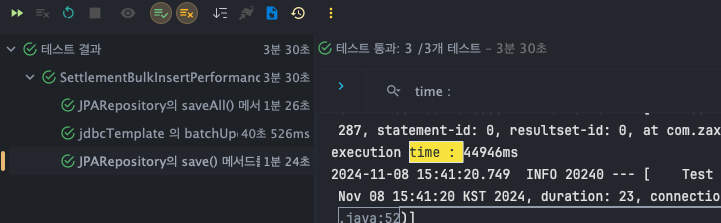
JPARepository - saveAll()
- T1 : 46345ms
- T2 : 46132ms
- T3 : 45962ms
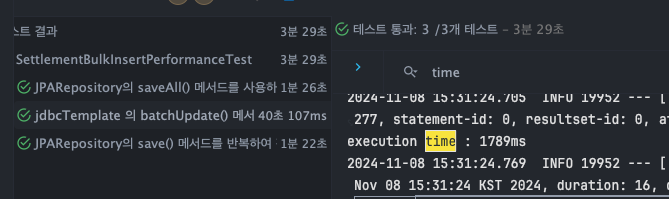
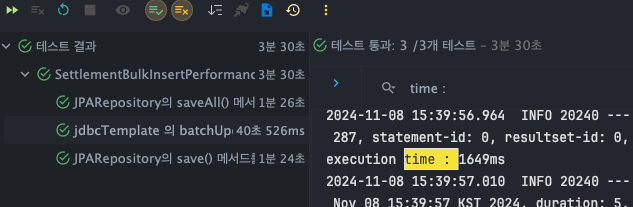
jdbcTemplate - batchUpdate()
- T1 : 1789ms
- T2 : 1649ms
- T3 : 1692ms
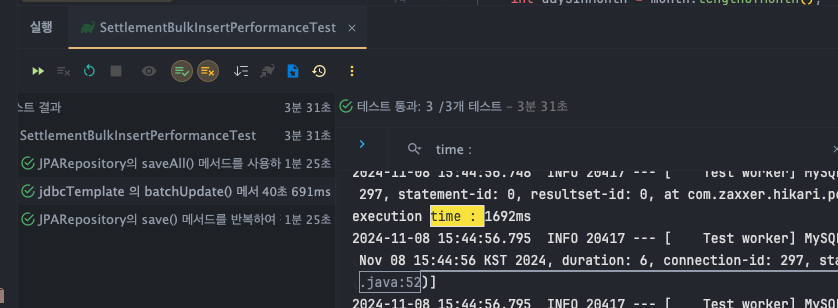
통계 및 성능 지표
통계를 내보면 다음과 같습니다.
| 데이터 양 | JPARepository - save() | JPARepository - saveAll() | jdbcTemplate - batchUpdate() |
|---|---|---|---|
| 1,000건 | 평균 453.67ms | 평균 542ms | 평균 59.67ms |
| 10,000건 | 평균 4,137.67ms | 평균 4,320.67ms | 평균 213.33ms |
| 100,000건 | 평균 45,427ms | 평균 46,146.33ms | 평균 1,710ms |
성능 개선 지표는 다음과 같습니다.
데이터 건수가 증가할수록 jdbcTemplate의 batchUpdate() 방식이 JPA save() 메서드보다 성능 면에서 더욱 두드러진 우수성을 보임을 확인할 수 있습니다.
데이터 건수가 100만 건, 200만 건 이상으로 증가할 경우, jdbcTemplate의 batchUpdate() 방식은 JPA save() 메서드 대비 기하급수적인 성능 개선 효과를 보일 것으로 예상됩니다.
| 데이터 건수 | JPARepository - save() | jdbcTemplate - batchUpdate() | 성능 개선 배율 |
|---|---|---|---|
| 1,000건 | 평균 454ms | 평균 60ms | 약 7.6배 |
| 10,000건 | 평균 4,138ms | 평균 213ms | 약 19.4배 |
| 100,000건 | 평균 45,427ms | 평균 1,710ms | 약 26.6배 |
참고
