

RESTful API
API
🐱🏍 Application Programmable Interface
컴퓨터끼리 통신할 수 있도록 하는 인터페이스
사용자가 프로그래밍하여 원하는 서비스를 구현할 수 있음
RESTful API
🐱🏍 REpresentational State Transfer API
웹상에서 http 프로토콜을 통해 원격으로 프로그램을 제어(이용)하는데 사용
딥러닝 앱 만들기
Gradio, Hugging Face API를 사용하여 간단한 딥러닝 앱 만들기를 수행하였다.
Gradio
개념
Python 기반의 머신 러닝 모델 배포 및 인터페이스 생성을 위한 라이브러리
활용 예시
✅ 실행된 캔버스에 그림을 그리면 이를 180도 회전시켜주는 프로그램
import gradio as gr
def predict(image):
return image.rotate(180)
app = gr.Interface(fn=predict,
inputs=gr.Image(source="canvas", type="pil"),
outputs="image",
live=True)
app.launch()Hugging Face
개념
사전 학습된 모델을 제공하여 빠르고 정확한 모델 구축 및 활용 가능
활용 예시
✅ 감정분석 프로그램
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")✅ 챗봇
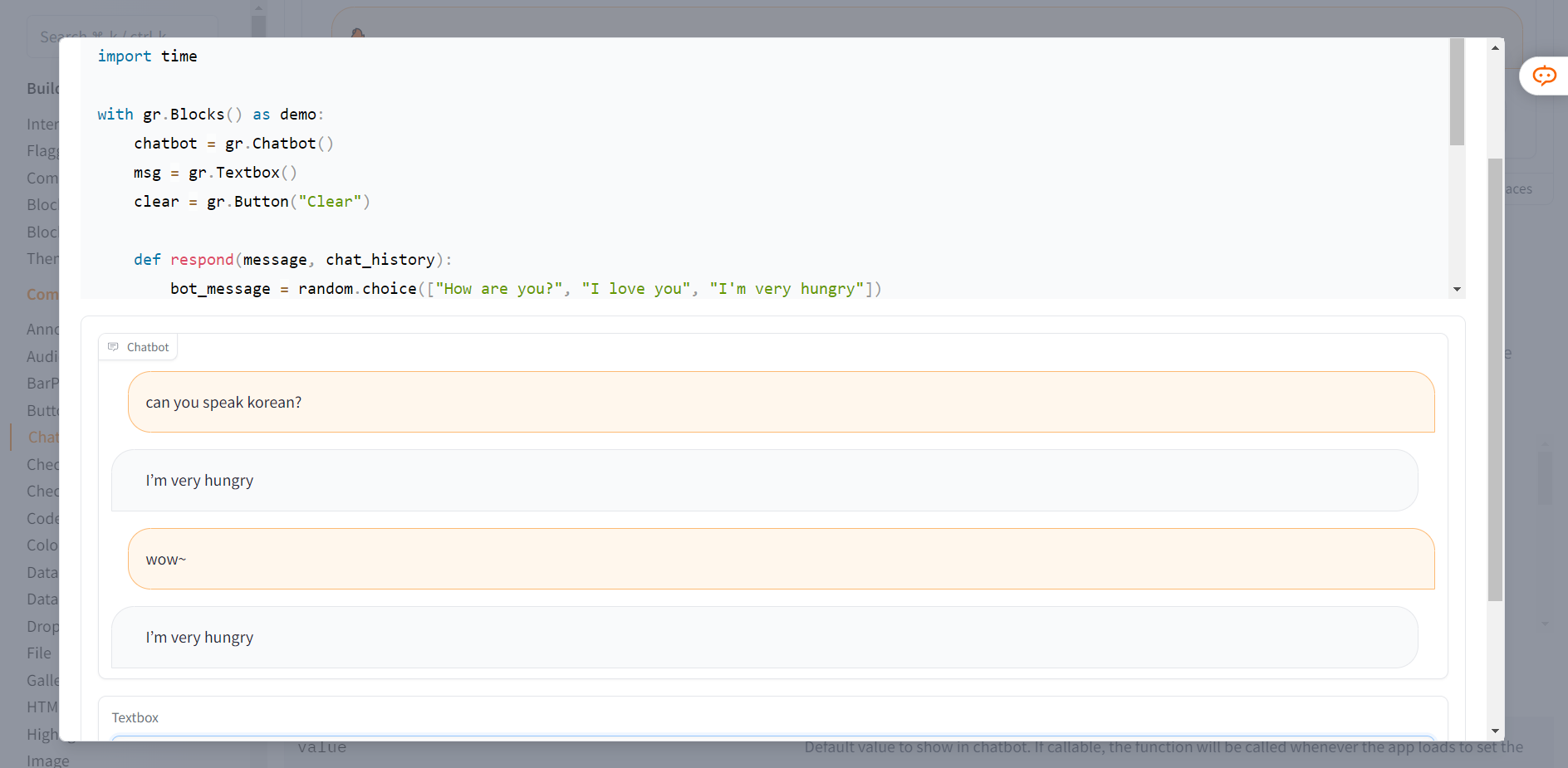
이는 허깅페이스 사이트 내에 있는 챗봇서비스 관련 코드와 사용예시이다.
내가 코드를 제대로 보지 못하고
🤷♀️ 왜 먼 말을 해두 배고프다고만하지?^^ 했는데
코드가 애초에 'How are you?', 'I love you', 'I'm very hungry' 중 랜덤으로 출력되는 것이였다.
이처럼 허깅페이스에서 제공하는 모델을 사용해 내가 원하는 서비스를 구현할 수 있다!
미니프로젝트 7차
이제 남은건 프로젝트뿐!
프로젝트 시작을 우리의 담임선생님께서 맡아주셨다.✨🏆💡🙆♀️👍
데이터 전처리
여러 번 강조해도 부족한 데이터 전처리 총정리를 해주셨다👍
데이터 분할이유
train, val, test로 데이터를 분할하는 이유는 다음과 같다.
💡 일반화된 성능을 얻기 위해서!
일반화된 성능이란 train 뿐만 아니라 val, test 모두에서 좋은 성능을 보이는 경우를 말한다.
전처리 순서
- 변수 삭제
- NaN 채우기
- 변수 추가
- 가변수화
- x, y 분할
- 스케일링
- KNN Imputer
⭐ 순서
위 순서는 절대적인 것은 아니다. 단, 2번과 4번은 순서를 꼮 지켜줘야한다!! 꼮!!!
2번 NaN 채우기가 가변수화보다 먼저 수행되어야 한다.
⭐ KNN Imputer
지난 프로젝트 때 성능을 높이는 데 큰 역할을 한 KNN Imputer!(나는 못씀)
개념
결측치(missing values)를 처리하기 위한 대표적인 방법
원리
K개의 가장 가까운 이웃을 활용하여 값을 추정하는 방법
- 결측치가 아닌 데이터를 기반으로 KNN 알고리즘을 적용
- 각 결측치와 가장 가까운 이웃들 탐색
- 이웃들의 평균값, 중앙값, 최빈값 등을 활용하여 결측치를 예측 및 보간
코드
# 1. 라이브러리 가져오기
from sklearn.impute import KNNImputer
# 2. 인스턴스 생성
imputer = KNNImputer(n_neighbors=5, metric='nan_euclidean')
# 3. 결측치 처리
imputed_data = imputer.fit_transform(data)MLFlow
이제서야 알아서 너무 아쉬울정도인 mlflow!
개념
머신 러닝 실험을 관리하고 추적하기 위한 오픈 소스 플랫폼
구성요소
1. Tracking
- 실험을 기록하고 관리하는 데 사용되는 기능
- 메트릭, 파라미터, 모델 등의 정보 기록 👉 실험 결과 추적 및 비교
2. Projects
- 머신 러닝 프로젝트의 코드, 데이터 및 환경을 패키지화
- 다른 환경에서 재현될 수 있도록 코드와 종속성을 캡슐화
- 모델 훈련과 실행에 필요한 일관된 환경 구축
3. Models
- 모델 아티팩트 관리 및 추적
- 훈련된 모델을 저장, 버전 관리 👉 배포나 추론에 사용
코드
모델링
# 1. mlflow 설정 및 추적
mlflow_uri = "sqlite:///mlflow.db"
mlflow.set_tracking_uri(mlflow_uri)
# 2. 실험 만들기
exp_id = mlflow.create_experiment("exp")
exp_id
# 3. 새 실험에 tracking 하기
with mlflow.start_run(): # 추적 시작 지정
# 파일 자동관리 시작
mlflow.keras.autolog()
# 모델 선언 및 훈련
# ...
# 파일 자동관리 끝
mlflow.sklearn.autolog(disable = True)
모델 로딩
# 버전으로 가져오기
model_uri = "models:/CarSeat/1"
model1 = mlflow.sklearn.load_model(model_uri)
# 최신버전으로 가져오기
model_uri = "models:/CarSeat/latest"
model2 = mlflow.sklearn.load_model(model_uri)
# 운영중인 버전 가져오기
model_uri = "models:/CarSeat/production"
model3 = mlflow.sklearn.load_model(model_uri)
# 예측
model1.predict(x)